Artificial intelligence systems have made significant progress in simulating human style reasoning, especially math and logic. These models don’t just generate answers – they go through a series of logical steps to reach out to conclusions and provide insight into how and why these answers are produced. This step-by-step reason, often called chain-of-thoughthought (COT), has become crucial to how machines handle complex problem-solving tasks.
A common problem that scientists encounter with these models is inefficiency during the inference. Reasoning models often continue to process even after reaching a correct conclusion. This over -thinking results in the unnecessary generation of tokens, increasing calculation costs. Whether these models have an internal sense of correctness remains unclear – do they realize when an intermediate answer is right? If they could identify this internally, the models could stop the treatment earlier and become more effective without losing accuracy.
Many current approaches measure a model’s confidence through verbal prompt or by analyzing multiple outputs. These black-box strategies ask the model to report how sure it is of its answer. However, they are often inaccurate and calculated expensive. On the other hand, white boxing methods examine the models’ internal hidden conditions to extract signals that can correlate with response correction. Previous work shows that a model’s internal states may indicate the validity of the final answers, but applying this to intermediate steps in long reasoning chains is still an undersired direction.
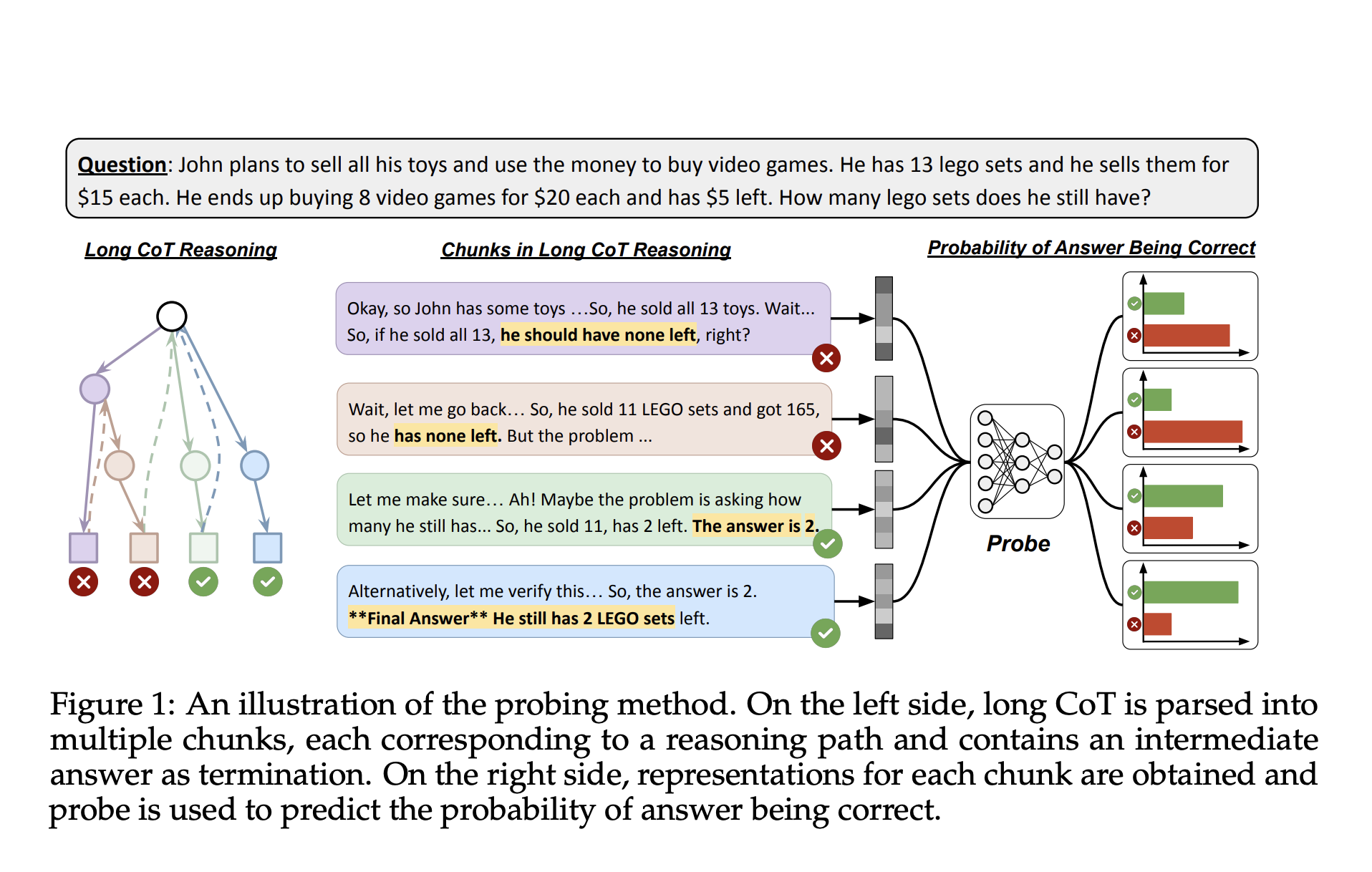
The research, introduced by a team from New York University and Nyu Shanghai, tackled this gap by designing a light probe-a single two-layer neural network-to inspect a model hidden states in intermediate reasoning steps. The models used for experimentation included the Deepseek-R1-Distill series and QWQ-32B, known for their step-by-step-rounding features. These models were tested across different data sets that involved mathematical and logical tasks. The researchers trained their probe to read the internal state associated with each pile of reasoning and predict whether the current intermediate response was correct.
To construct their approach, the researchers first segment each long childbearing output in smaller parts or chunks using markers such as “wait” or “verify” to identify breaks in the reasoning. They used the last token’s hidden state in each part as a representation and matched this into a correctness mark that was judged using another model. These representations were then used to train the probe on binary classification tasks. The probe was fine-tuned using grid searches across hyperparameters such as learning speed and hidden layer size, where most models converged to linear probes-what indicates that correctness information is often linearly embedded in the hidden conditions. The probe worked for fully formed answers and showed the ability to predict correctness before an answer was even completed, which suggested the look-aead capacities.
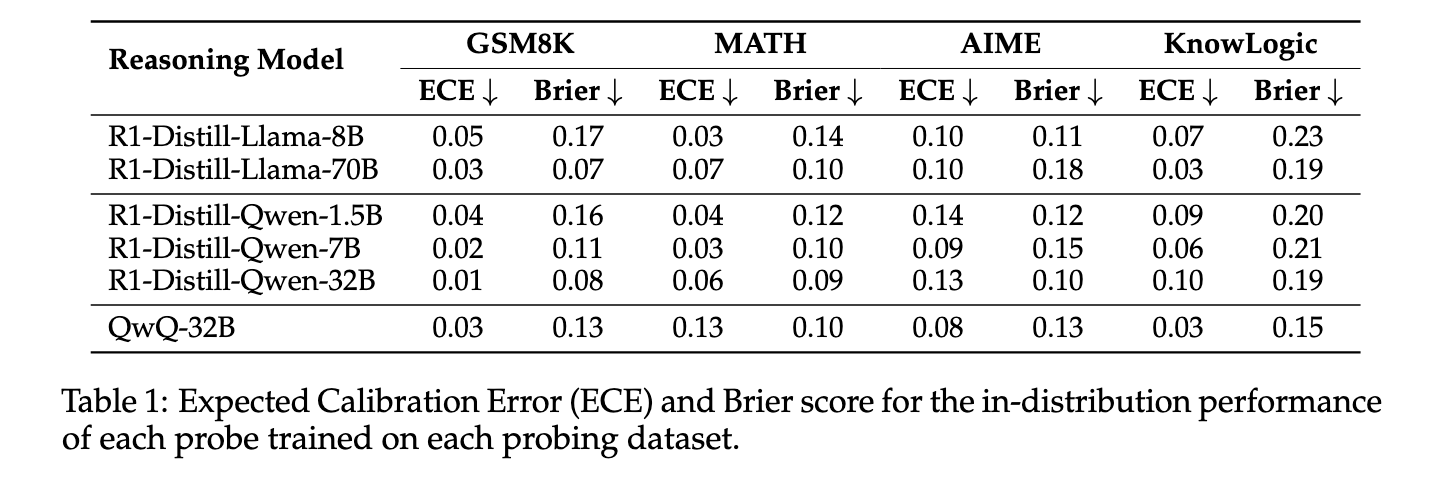
The results of the performance were clear and quantifiable. The probes achieved ROC-AUC scores that exceed 0.9 for some data sets like AIME when using models such as R1-Distill-Qwen-32B. Expected calibration error (ECE) remained below 0.1, which showed high reliability. For example, R1-Distill-Qwen-32B had an ECE of only 0.01 on GSM8K and 0.06 on math data set. In use, the probe was used to implement a trust-based early exit strategy under the inference. The reasoning process was stopped as the probe’s confidence in a response exceeded a threshold. At a trustworthy of 0.85, the accuracy remained 88.2%, while the inference token number was reduced by 24%. Even at a threshold of 0.9, accuracy remained at 88.6% with a 19% token reduction. Compared to static exit methods, this dynamic strategy achieved up to 5% higher accuracy using the same or fewer symbols.
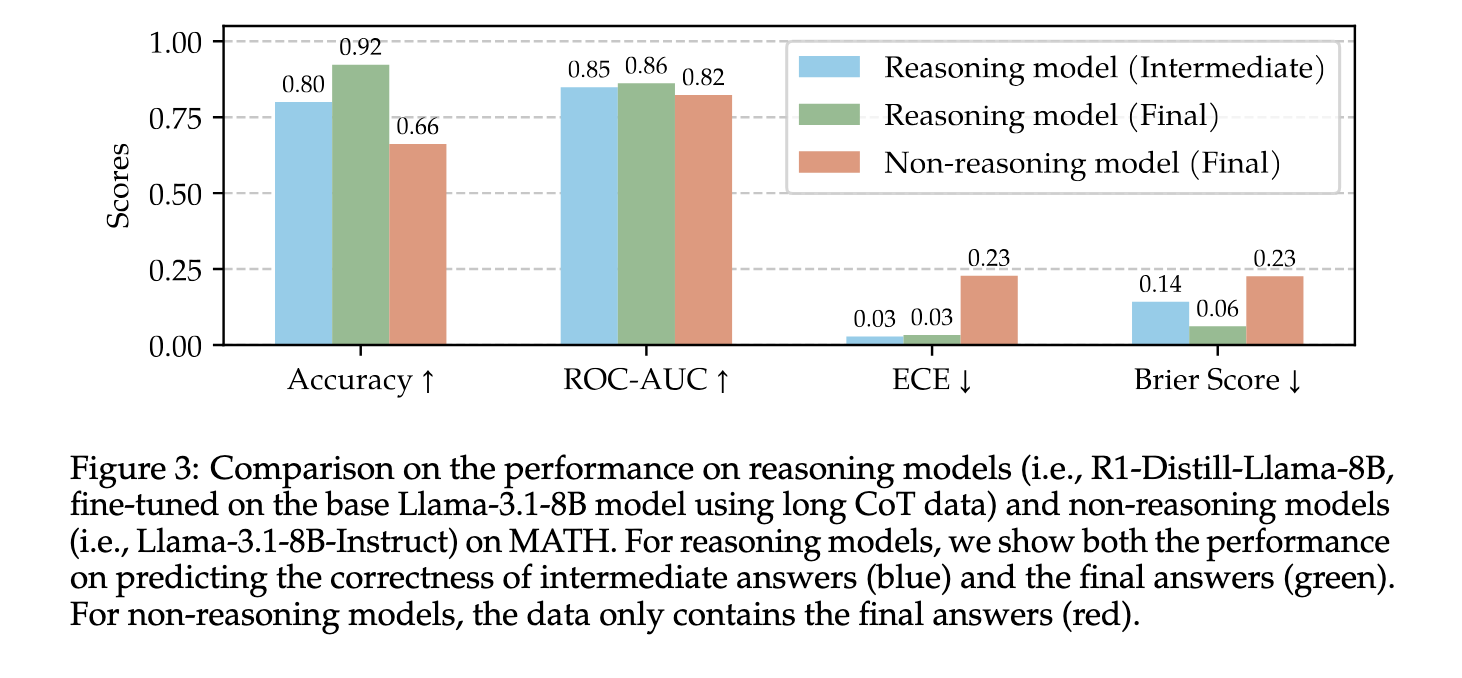
This study offers an effective, integrated way to resonate models for self-verification during inference. The researchers’ approach that clarifies a hole – while models inherently know when they are right, they do not act on it. The research reveals a path to smarter, more effective reasoning systems by exploiting internal representations through exploration. It shows that utilizing what the model already “knows” can lead to meaningful improvements in services and resource consumption.
Check out Paper. All credit for this research goes to the researchers in this project. You are also welcome to follow us on Twitter And don’t forget to join our 85k+ ml subbreddit.
Nikhil is an internal consultant at MarkTechpost. He is pursuing an integrated double degree in materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who always examines applications in fields such as biomaterials and biomedical science. With a strong background in material science, he explores new progress and creates opportunities to contribute.
