Effective reasoning is crucial to solving complex problems in fields such as math and programming, and LLMs have shown significant improvements through long -term reasoning. However, transformer -based models face restrictions due to their square calculation complexity and linear memory requirements, making it challenging to treat long sequences effectively. While techniques such as Chain of Thought (COT) reasoning and adaptive calculation distribution have helped increase model performance, these methods also increase calculation costs. In addition, it is generating multiple outputs and choosing the best examined as a way to improve the accuracy of the reasoning. However, such methods still depend on transformer -based architectures that struggle with scalability in large batches, long -checking tasks.
To tackle these challenges, alternatives to the transformer architecture have been examined, including RNN-based models, state space models (SSMs) and linear attention mechanisms that offer more effective memory use and faster inference. Hybrid models that combine self-perception with subquadratic layers have also been developed to improve scaling time coaling inference time. In addition, knowledge distillation techniques that transmit capacities from large models to smaller have shown a promise to maintain reasoning performance while reducing the model size. Research in cross -architecture distillation, such as transferring knowledge from transformers to RNNs or SSMs, is ongoing to achieve high reasoning features in smaller, more efficient models.
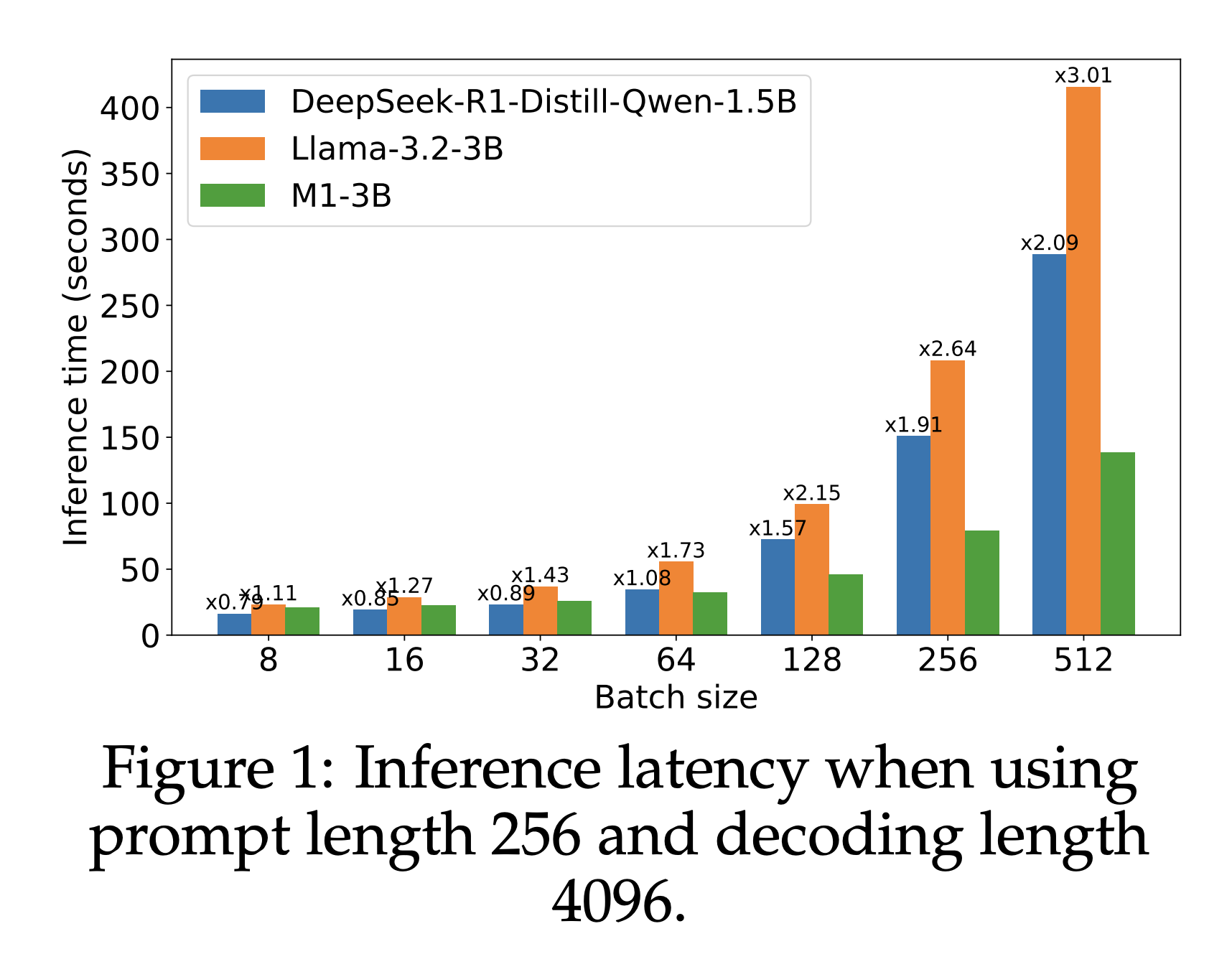
Researchers from Togetherai, Cornell University, University of Geneva and Princeton University present M1, a Hybrid Linear RNN Reasoning Model built on the Mamba architecture, which improves memory-efficient inference. M1 is trained through a combination of distillation, monitored fine tuning and reinforcement learning. Experimental results on AIME and Math Benchmarks show that M1 is better than previous linear RNN models and matches the performance of Deepseek R1 distilled transformers. In addition, the M1 achieves a 3x speedup in inference compared to transformers of the same size, which increases the accuracy of the reasoning through techniques such as self -consistency and verification, making it a strong model for large -scale inference.
The M1 model is built through a three-step process: distillation, SFT and RL. First, a prior transformer model is distilled to the Mamba architecture with a modified approach to linear projections and additional parameters for better performance. In the SFT phase, the model is fine-tuned on mathematical problem data sets, first with general data sets and then with reasoning focused data set from the R1 Model Series. Finally, RL is used using the GRPO, which improves the model’s reasoning by training with benefit estimates and encouraging diversity in its answers, further increasing its performance further.
The experiment uses Llama3.2-3 B instruction models as a measure of distillation, where the Mamba layers use a 16-size SSM mode. The evaluation includes a number of mathematical benchmarks, including Math500, AIME25 and Olympiad Bench, which assesses model performance based on coverage and accuracy. Passport@K -Metry is used for cover, indicating the probability of a proper resolution among generated samples. The model’s performance is compared to the models from different advanced models, giving competitive results, especially in reasoning tasks. Inference Speed and Test-Time Scaling is evaluated, demonstrating M1’s effectiveness in generating large batches and longer sequence contexts.
Finally, the M1 is a hybrid reasoning model based on the MAMBA architecture, designed to overcome scalability problems in transformer models. By using distillation and fine -tuning techniques, M1 is obtained compared to advanced reasoning models. It offers more than 3x faster inference than transformer models of similar size, especially with large batch sizes, making resource -intensive strategies as self -consistency’s more feasible. M1 surpasses linear RNN models and matches Deepseek R1’s performance on benchmarks such as AIME and Math. In addition, it demonstrates superior accuracy under fixed time budgets, making it a strong, effective alternative to transformer -based architectures for mathematical reasoning tasks.
Here it is Paper. Nor do not forget to follow us on Twitter and join in our Telegram Channel and LinkedIn GrOUP. Don’t forget to take part in our 90k+ ml subbreddit.
🔥 [Register Now] Minicon Virtual Conference On Agentic AI: Free Registration + Certificate for Participation + 4 Hours Short Event (21 May, 9- 13.00 pst) + Hands on Workshop
Sana Hassan, a consultant intern at MarkTechpost and dual-degree students at IIT Madras, is passionate about using technology and AI to tackle challenges in the real world. With a great interest in solving practical problems, he brings a new perspective to the intersection of AI and real solutions.
