The growth in the development and implementation of large language models (LLMs) is closely linked to architectural innovations, large data sets and hardware improvements. Models such as DeepSEEK-V3, GPT-4O, Claude 3.5 Sonnet and Llama-3 have shown how scaling improves reasoning and dialogue functions. As their performance increases, computing, memory and communication band width require, which puts significant strain on hardware. Without parallel progress in the co-design of the model and infrastructure, these models risk only becoming available to organizations with massive resources. This makes optimization of training costs, inference speed and memory efficiency to a critical research area.
A core challenge is the discrepancy between model size and hardware features. LLM memory consumption grows over 1000% annually, while high-speed memory bandwidth increases by less than 50%. Under inference, the cache stores add cache prior context in key value (kV) stores to the memory tribe and slow down the treatment. Tette models activate all parameters per Token, escalating calculation costs, especially for models with hundreds of billions of parameters. This results in billions of fluent point operations per year. Token and high energy requirements. Time per Output -Token (TPOT), a key production metrics, also suffers and affects the user experience. These problems require solutions in addition to just adding more hardware.
Techniques such as Multi-Query Authall (MQA) and Grouped-Query Autthor (GQA) reduce memory consumption by sharing attention weights. Window KV cache lowers memory use by only saving recent tokens, but can limit long context understanding. Quantized compression with low-bit formats such as 4-bit and 8-bit cuts memory further, however, sometimes with balancing in accuracy. Precision formats such as BF16 and FP8 enhance the training speed and efficiency. Although useful, these techniques often tackle individual problems rather than a comprehensive solution to scaling challenges.
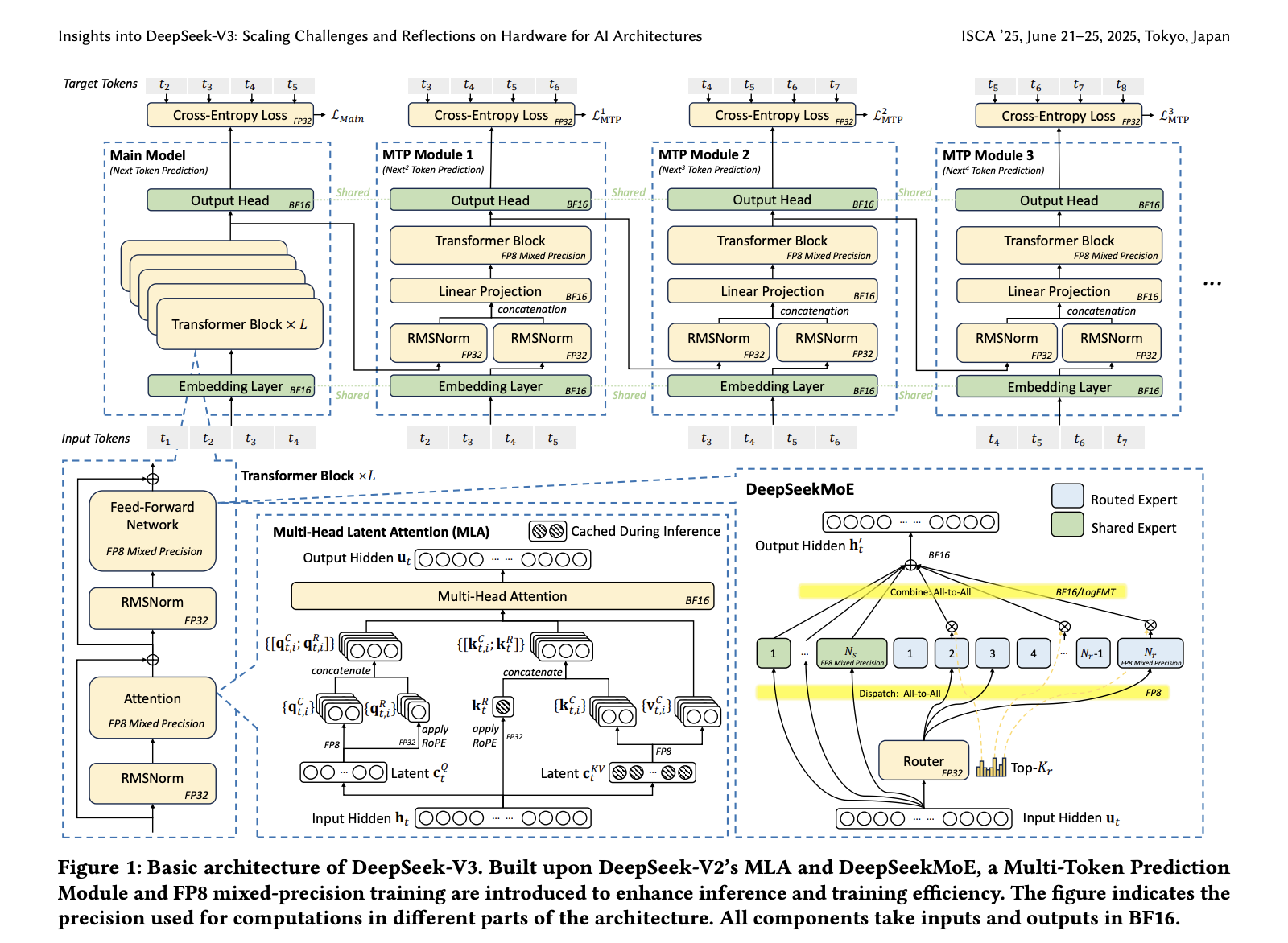
Researchers from Deepseek-IA introduced a more integrated and effective strategy with the development of Deepseek-V3, designed to scale intelligently rather than excessive. Using 2,048 NVIDIA H800 GPUs, the model achieves advanced performance while focusing on cost -effectiveness. Instead of depending on expansive infrastructure, the team designed the model architecture to work harmoniously with hardware limits. Central to this effort is innovations such as latent attention in multiple heads (MLA) for memory optimization, a mixture of experts (MOE) framework for calculation efficiency and FP8-mixed-precision training to speed up performance without sacrificing accuracy. A custom multi-plan network topology was also used to minimize communication costs between devices. Overall, these components make Deepseek-V3 a scalable and accessible solution that is able to compete with much larger systems while working on markedly leaner resources.
The architecture achieves memory efficiency by reducing the KV cache requirement per year. Token to only 70 KB using MLA respectively compared to 327 KB and 516 KB in QWEN-2.5 and Llama-3.1 respectively. This reduction is achieved by compressing attention heads into a less latent vector trained with the model. Calculation efficiency is further increased with the MOE model, increasing the total parameters to 671 billion, but activates only 37 billion per year. Token. This contrasts sharply with dense models that require full parameter activation. For example, Llama-3.1 needs 2,448 GFLOPS per year. Token, while Deepseek-V3 works on only 250 Gflops. Architecture also integrates a multi -token prediction (MTP) module that enables the generation of multiple tokens in a single step. The system achieves up to 1.8x improvement in generational speed, and measurements in the real world show 80-90% token acceptance for speculative decoding.

Using a system associated with the CX7 400 Gbps Infiniband NICS, Deepseek-V3 achieves a theoretical TPOT of 14.76 milliseconds, equivalent to 67 tokens per year. Second. With higher bandwidth setups such as NVIDIA GB200 NVL72, which offers 900 GB/s, this number can be reduced to 0.82 milliseconds TPOT, which potentially achieves 1,200 tokens per year. Second. The practical flow is lower due to calculation communication overlapping and memory restrictions, but the framework lays the basis for future high -speed implementations. FP8 precision adds additional speed gains. The training frame uses tile 1 × 128 and block 128 × 128 quantization with less than 0.25% accuracy loss compared to BF16. These results were validated on smaller 16B and 230B parameter versions before integration into the 671B model.
Several important takeaways from the research on insight into Deepseek-V3 include:
- MLA Compression reduces KV -Cache size per Token from 516 KB to 70 KB, which significantly lowers memory requirements under the inferency.
- Only 37 billion of the 671 billion total parameters are activated per year. Token, which dramatically reduces calculation and memory requirements without compromising the model performance.
- Deepseek-V3 requires only 250 GFLOPS per day. Token compared to 2,448 Gflops for dense models such as Llama-3.1, which highlights its calculation efficiency.
- Achieves up to 67 tokens per Second (TPS) on a 400 Gbps infiniband network, with the potential to scale to 1,200 TPS using advanced interconnections such as NVL72.
- Multi-token Prediction (MTP) improves the generational speed by 1.8 × with a token accept speed of 80-90%, which improves the inference flow.
- FP8 Mixing precision training enables faster calculation with less than 0.25% accuracy decrease, validated through extensive small-scale ablations.
- Able to run on a $ 10,000 server with a consumer quality GPU delivers nearly 20 TPS, making high performance LLMs more accessible.
Finally, research presents a rounded framework to build powerful and resource -conscious large language models. By directly tackling basic restrictions, such as memory restrictions, high calculation costs and inference latency, researchers demonstrate that intelligent architecture hardware-CO design can unlock high performance without relying on enormous infrastructure. Deepseek-V3 is a clear example of how efficiency and scalability coexist, enabling broader adoption of advanced AI capacities across different organizations. This approach moves the narrative from scaling through brute force to scaling through smarter technique.
Check the paper. All credit for this research goes to the researchers in this project. You are also welcome to follow us on Twitter And don’t forget to join our 90k+ ml subbreddit.
Sana Hassan, a consultant intern at MarkTechpost and dual-degree students at IIT Madras, is passionate about using technology and AI to tackle challenges in the real world. With a great interest in solving practical problems, he brings a new perspective to the intersection of AI and real solutions.
