The field of artificial intelligence is developing rapidly with increasing efforts to develop more skilled and effective language models. However, scaling of these models comes with challenges, especially with regard to calculation resources and the complexity of training. The research community is still investigating best practices for scaling extremely large models, whether they use a close or mix of experts (MOE) architecture. Until recently, many details of this process were not widely divided, making it difficult to refine and improve large AI systems.
Qwen AI aims to tackle these challenges with QWEN2.5-MAX, a large MOE model that is prior to 20 trillion tokens and further refined through monitored fine-tuning (SFT) and reinforcement learning from Human Feedback (RLHF). This approach fine -tunes the model to better adapt to human expectations, while the efficiency maintains the effectiveness of scaling.
Technically, QWEN2.5-MAX uses a mixture of expert architecture, allowing it to only activate a subgroup of its parameters under the inference. This optimizes the calculation efficiency while maintaining performance. The extensive Pretraining phase provides a strong foundation for knowledge, while SFT and RLHF refine the model’s ability to generate coherent and relevant answers. These techniques help improve the model’s reasoning and usability across different applications.
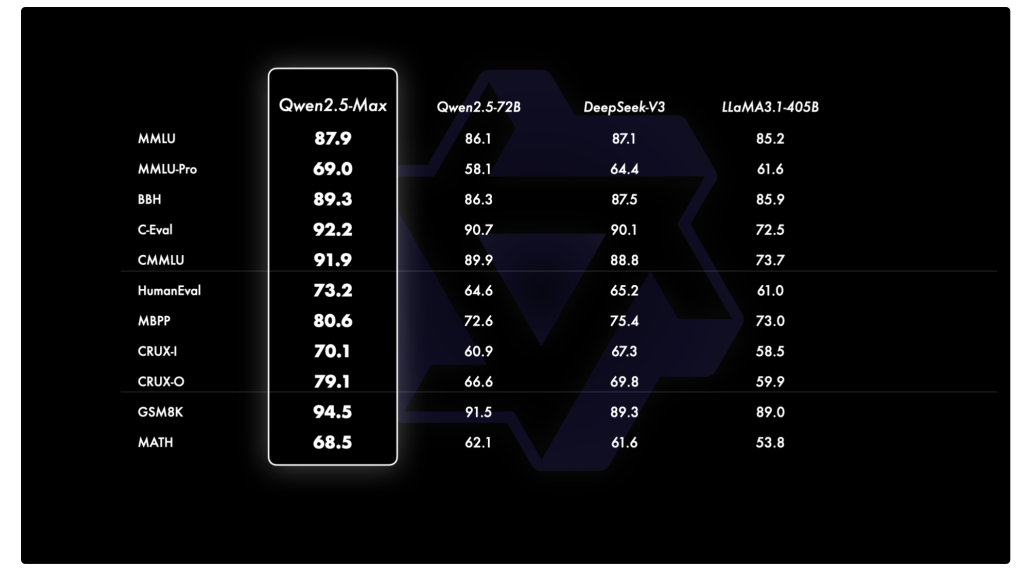
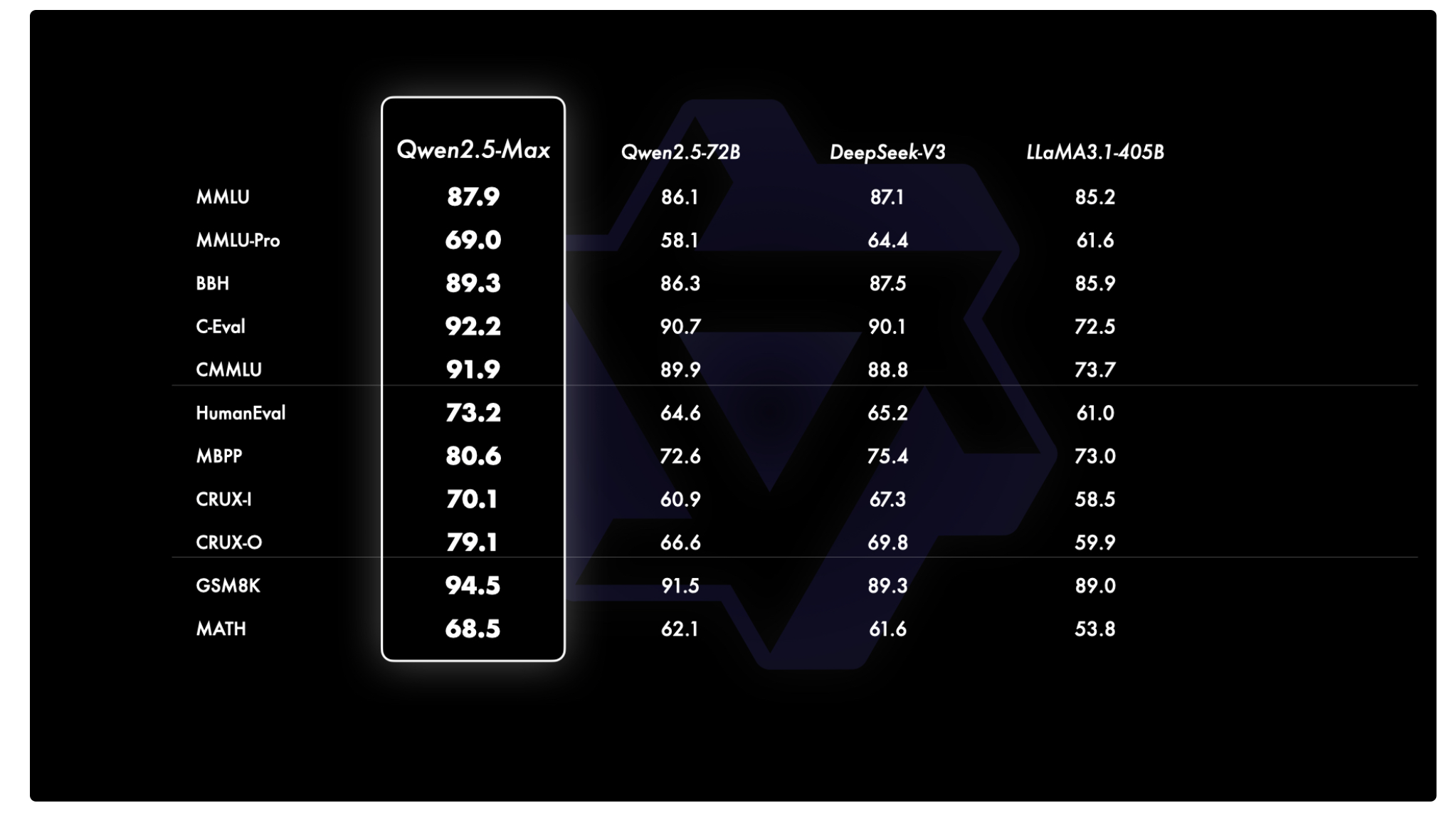
QWEN2.5-MAX has been evaluated against leading models on benchmarks such as MMLU-Pro, LiveCodeBench, Livebench and Arena-Hard. The results suggest that it works competitively and surpasses Deepseek V3 in tests such as Arena-Hard, Livebech, Live Codebench and GPQA diamond. Its performance on MMLU-Pro is also strong and highlights its capabilities in knowledge enrollment, coding tasks and wider AI applications.
In summary, QWEN2.5-MAX presents a thought-provoking approach to scaling language models while maintaining efficiency and performance. By utilizing a MOE architecture and strategic methods after training, it addresses the important challenges of AI model development. As AI research progresses, models such as QWEN2.5-MAX show how thought-provoking data usage and training techniques can lead to more skilled and reliable AI systems.
Check out Demo about hugging face and technical details. All credit for this research goes to the researchers in this project. Nor do not forget to follow us on Twitter and join in our Telegram Channel and LinkedIn GrOUP. Don’t forget to take part in our 70k+ ml subbreddit.
🚨 [Recommended Read] Nebius AI Studio is expanded with visual models, new language models, embedders and lora (Promoted)
Aswin AK is a consulting intern at MarkTechpost. He is pursuing his double degree at the Indian Institute of Technology, Kharagpur. He is passionate about data science and machine learning, which brings a strong academic background and practical experience in solving real life challenges across domains.
✅ [Recommended] Join our Telegram -Canal