Large Language Models (LLMs) have shown remarkable reasoning functions in mathematical problem solving, logical inference and programming. However, their effectiveness is often conditioned by two approaches: monitored fine tuning (SFT) with human-annoted reasoning chains and Search strategies in inference time Guided by external verifiers. While monitored fine -tuning offers structured reasoning, it requires significant annotation effort and is limited by the quality of the teacher model. Searching techniques in inference time, such as Verifier-controlled sampling, improve accuracy, but increase the calculation requirements. This raises an important question: Can an LLM develop reasoning capabilities independently without relying on extensive human supervision or external verifiers? In order to tackle this, scientists have introduced SatoriA 7B parameter LLM designed to internalize reasoning search and self-improvement mechanisms.
Introduction of Satori: A model for self -reflective and self -embracing reasoning
Researchers from MIT, Singapore University of Technology and Design, Harvard, Mit-Ibm Watson Ai Lab, IBM Research and Umass Amherst propose Satoria model that uses Authorous search— A mechanism that allows it to refine its reasoning steps and explore alternative strategies autonomously. Unlike models that are dependent on extensive fine tuning or knowledge distillation, satori improves reasoning through a novel Chain-of-Action Thoughts (Coat) Reasoning Paradigm. Built on QWEN-2.5-MATH-7BSatori follows a two-step training frame: Small scale format tuning (FT) and Large -scale self -improvement via reinforcement learning (RL).
Technical details and benefits of satori
Satori’s training frame consists of two phases:
- Format Tuning (FT) Step:
- A small dataset (~ 10k samples) is used to introduce Coat Reasoningthat include three meta-actions:
- Continue (<| Fortsæt |>?: Expands the reasoning course.
- Reflect (<| Reflect |>?: Ask for a self -control at previous reasoning steps.
- Explore (<| Udforsk |>?: Uping the model to consider alternative approaches.
- In contrast to conventional cot training that follows predefined reasoning paths, Coat enables dynamic decision making Under reasoning.
- A small dataset (~ 10k samples) is used to introduce Coat Reasoningthat include three meta-actions:
- Reinforcement learning (RL) Step:
- A large -scale self -improvement process using Reinforcement learning with reboot and explore (RAE).
- The model Reboot Resonance from Middle Stagerefining its problem -solving approach iteratively.
- A Reward Model assigns scores based on self -corrections and depth of investigations, which leads to Progressive learning.
Insight
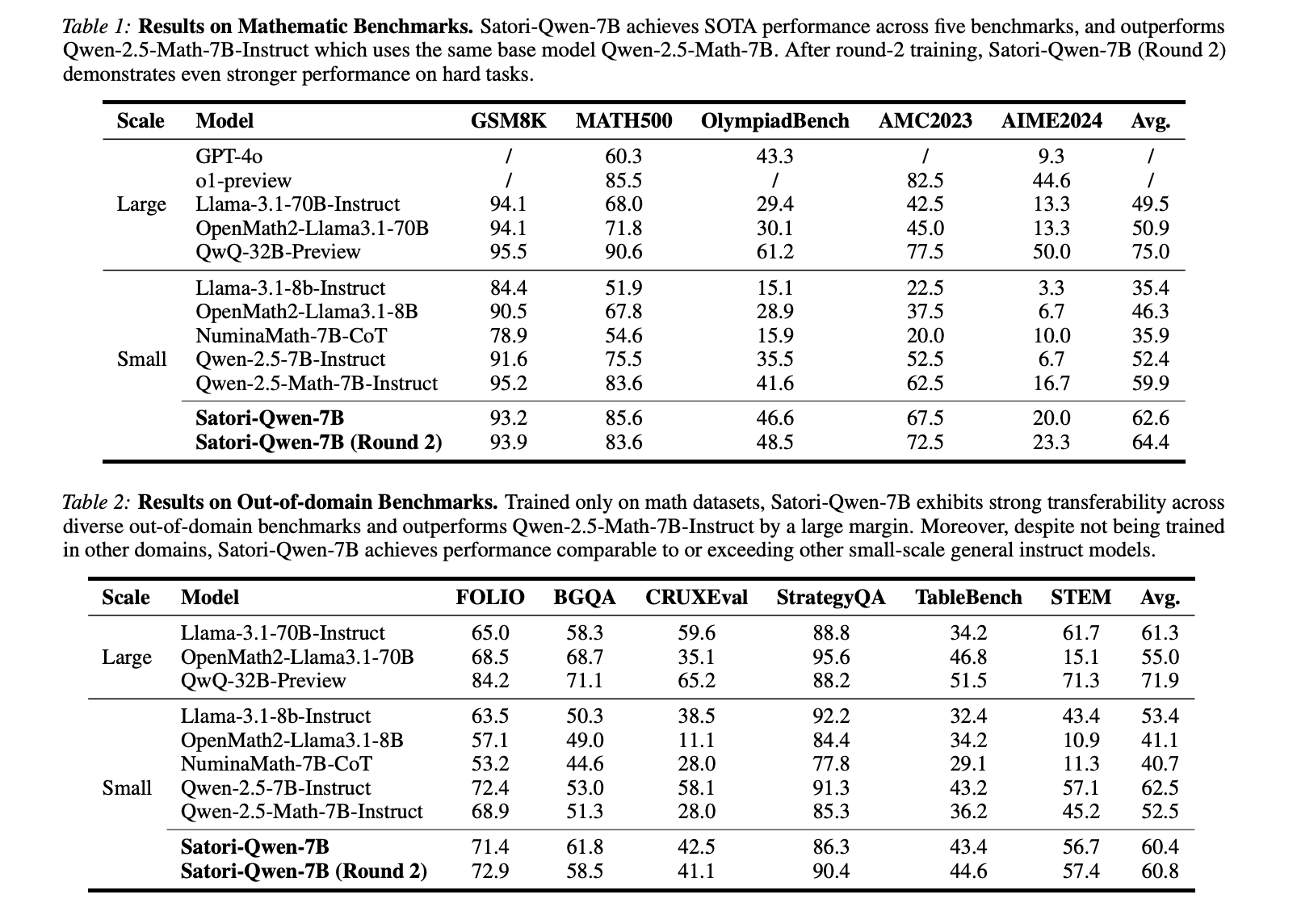
Evaluations show that Satori works strongly on multiple benchmarks and often surpasses models that depend on monitored fine tuning or knowledge distillation. The main findings include:
- Mathematical Benchmark -Performance:
- Satori surpasses QWEN-2.5-MATH-7B instructions on data sets such as GSM8K, Math500, Olympiadbench, AMC2023 and AIME2024.
- Self -improvement ability: With additional reinforcement training rounds, Satori demonstrates continuous refinement without further human intervention.
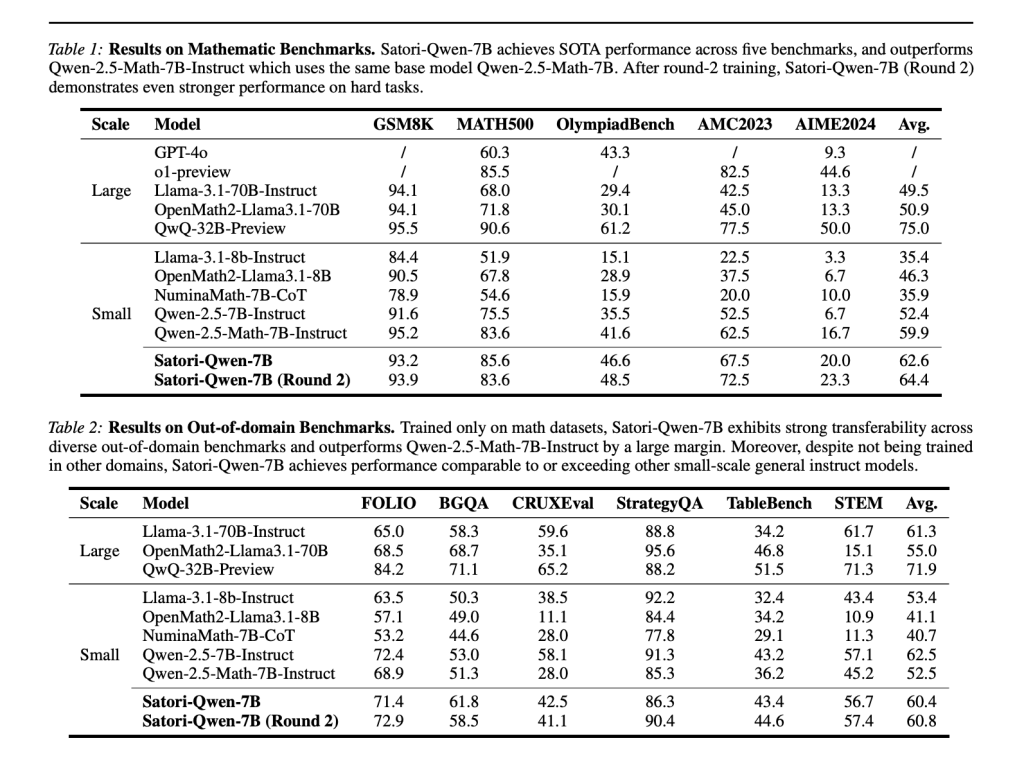
- Out of domain Generalization:
- Despite training primarily in mathematical reasoning, Sideri is exhibiting Strong generalization For various reasoning tasks, including logical reasoning (folio, boardgameqa), common reasoning (strategyqa) and tabular reasoning (tabletbench).
- This suggests it RL-driven self-improvement improves adaptability In addition to mathematical contexts.
- Efficiency gains:
- Compared to conventional Monitored fine tuningSatori achieves similar or better reasoning performance With significantly fewer annotated training samples (10k vs. 300k for comparable models).
- This approach reduces the dependence on extensive human comments while maintaining effective reasoning skills.
Conclusion: One step toward autonomous learning in LLMS
Satori presents a promising direction in LLM Reasoning Researchthat demonstrates that models can refine their own reasoning without external verifiers or high quality teacher models. By integrating Coat Reasoning, Reinforcement Learning and Authorous SearchSatori shows that LLMs iteratively can improve their reasoning skills. This approach not only improves problem -solving accuracy, but also extends the generalization to unseen tasks. Future work can explore refining Meta-Action frames, optimization of reinforcement learning strategies and expansion of these principles to wider domains.
Check out The paper and the github side. All credit for this research goes to the researchers in this project. Nor do not forget to follow us on Twitter and join in our Telegram Channel and LinkedIn GrOUP. Don’t forget to take part in our 75k+ ml subbreddit.
🚨 Recommended Open Source AI platform: ‘Intellagent is an open source multi-agent framework for evaluating complex conversation-ai system’ (promoted)
Aswin AK is a consulting intern at MarkTechpost. He is pursuing his double degree at the Indian Institute of Technology, Kharagpur. He is passionate about data science and machine learning, which brings a strong academic background and practical experience in solving real life challenges across domains.
✅ [Recommended] Join our Telegram -Canal