Language models (LMS) are significant progress through increased calculation power during training, primarily through large -scale self -monitored pre -entering. While this approach has provided powerful models, a new paradigm called test time scaling has emerged focusing on improving performance by increasing the calculation at inference time. Openai’s O1 model has validated this approach showing improved reasoning features through test time Compute Scaling. However, replicating these results has proved challenging with different experiments using techniques such as Monte Carlo Tree Search (MCS), Multi-Agent approaches and reinforcement learning. Even models like Deepseek R1 have used millions of tests and complex training stages, but no one has replicated test time scaling behavior in O1.
Different methods have been developed to tackle the test time scaling challenge. Sequential scaling methods allow models to generate successive solution experiments where each iteration is based on previous results. Wood -based search methods combine sequential and parallel scaling, implementation of techniques such as MCTs and guided beam search. Rebase has emerged as a remarkable approach using a process rewarding model to optimize wood search through balanced utilization and pruning, showing superior performance compared to sampling methods and MCTs. These approaches are highly dependent on reward models found in two forms: Result Reward models for evaluating complete solutions in best-of-n selection and process rewarding models for assessing individual reasoning steps in wood-based search methods.
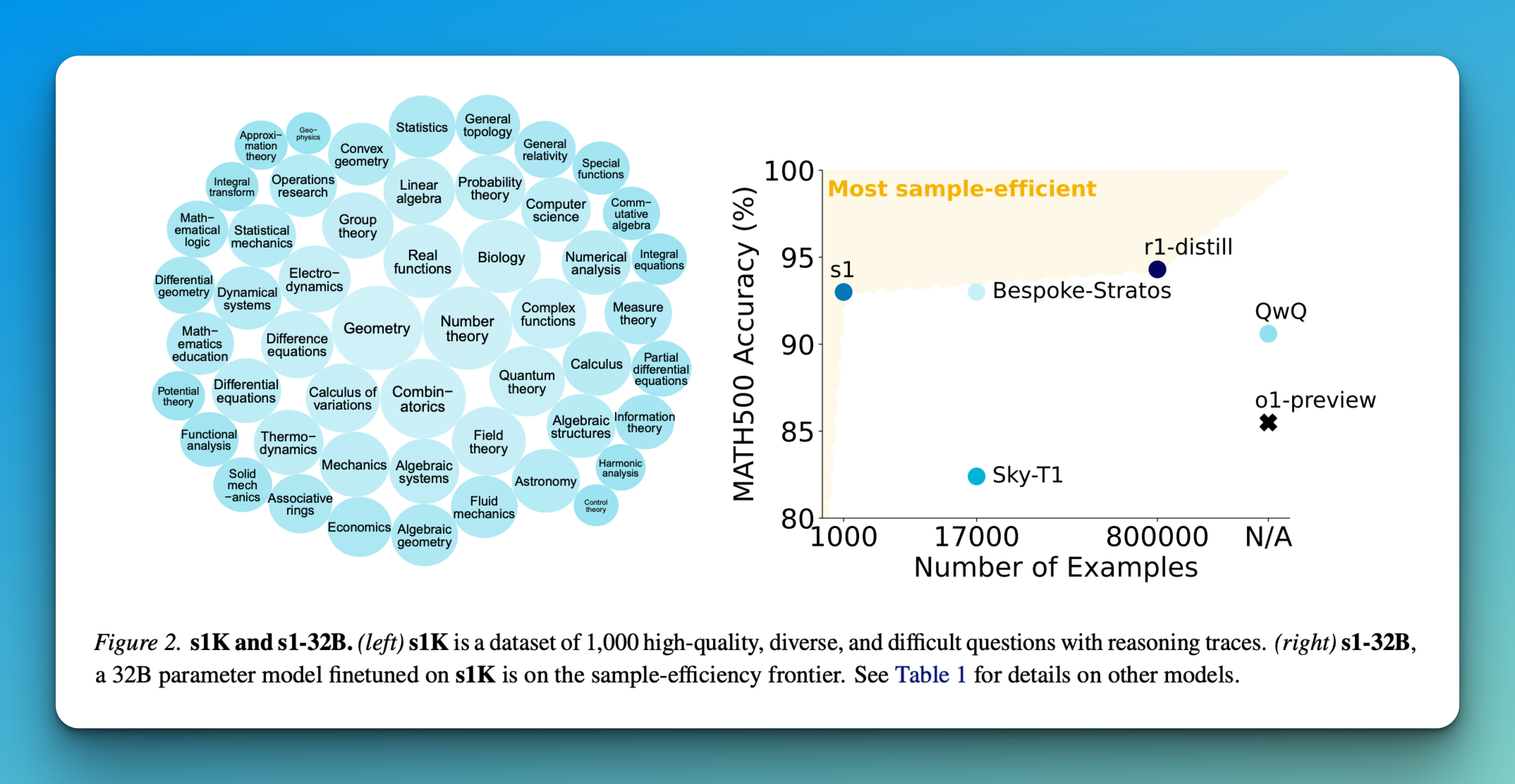
Researchers from Stanford University, University of Washington, Allen Institute for AI and Contextual AI have proposed a streamlined approach to achieving test time scaling and improved reasoning features. Their method centers on two key innovations: the carefully curated S1K data set, which includes 1,000 questions with reasoning traces, chosen based on difficulties, diversity and quality criteria and a new technique called budget -tvang. This budget obligation mechanism controls the calculation of test time by either cutting maps or expanding the model’s thinking process through strategic “wait” inputs, allowing the model to review and correct its reasoning. The procedure was implemented by fine-tuning the QWEN2.5-32B instruction language model on the S1K data set.
The data selection process follows a three-step filtration method based on quality, difficulties and diversity criteria. The quality filtering step begins by removing samples with API errors and formatting problems, reducing the initial data set to 51,581 examples from which 384 samples of high quality are initially selected. The difficulty assessment uses two key metrics: Model performance evaluation using QWEN2.5-7B instructions and QWEN2.5-32B instruction models, with correctness verified by Claude 3.5 Sonnet and reasoning track length measured by QWEN2.5-tokenizer. For diversity, questions are classified in specific domains using the subject classification system of mathematics through Claude 3.5 Sonnet. This comprehensive filtration process results in a last dataset of 1,000 samples spans 50 domains.
The S1-32B model demonstrates significant performance improvements through test time Compute scaling with the budget coercion. S1-32B works in a superior scaling paradigm compared to the base QWEN2.5-32B instruction model using a majority vote, which validates the effectiveness of sequential scaling over parallel approaches. In addition, the S1-32B appears as the most effective open data reimbursement model in sample efficiency, which shows marked improvement over the base model with only 1,000 additional training samples. While R1-32B achieves better performance, it requires 800 times more training data. In particular, the S1-32B Gemini 2.0 is approaching achievement on AIME24, which suggests successful knowledgeillation.
This paper shows that monitored fine-tuning (SFT) with only 1,000 carefully selected examples can create a competitive reasoning model that matches O1-Print’s performance and achieves optimal efficiency. The introduced budget management technique reproduces when combined with the reasoning model, successfully Openai’s test time scaling behavior. The effectiveness of such minimal training data suggests that the model’s reasoning functions are largely present from the prior trillions of symbols where the fine -tuning process simply activates these latent abilities. This matches “superficial adaptation hypothesis” from Lima research, suggesting that a relatively small number of examples can effectively adapt a model behavior with the desired results.
Check out The paper and the github side. All credit for this research goes to the researchers in this project. Nor do not forget to follow us on Twitter and join in our Telegram Channel and LinkedIn GrOUP. Don’t forget to take part in our 75k+ ml subbreddit.
🚨 Recommended Open Source AI platform: ‘Intellagent is an open source multi-agent framework for evaluating complex conversation-ai system’ (promoted)

Sajjad Ansari is a last year bachelor from IIT KHARAGPUR. As a technical enthusiast, he covers the practical uses of AI focusing on understanding the impact of AI technologies and their real world. He aims to formulate complex AI concepts in a clear and accessible way.
✅ [Recommended] Join our Telegram -Canal