Large language models (LLMs) such as GPT, Gemini and Claude use huge training data sets and complex architectures to generate high quality answers. However, optimization of their inference time calculation remains challenging as rising model size leads to higher calculation costs. Researchers continue to explore strategies that maximize efficiency while maintaining or improving model performance.
A widely adopted approach to improving LLM performance is ensembling, where several models are combined to generate a final output. Mix-of-agents (MOA) is a popular ensembling method that aggregates answers from different LLMs to synthesize a high quality response. However, this method introduces a fundamental trade -off between diversity and quality. While it may offer benefits of combining different models, it can also result in suboptimal performance due to the inclusion of lower quality reactions. Researchers aim to balance these factors to ensure optimal performance without compromising the response quality.
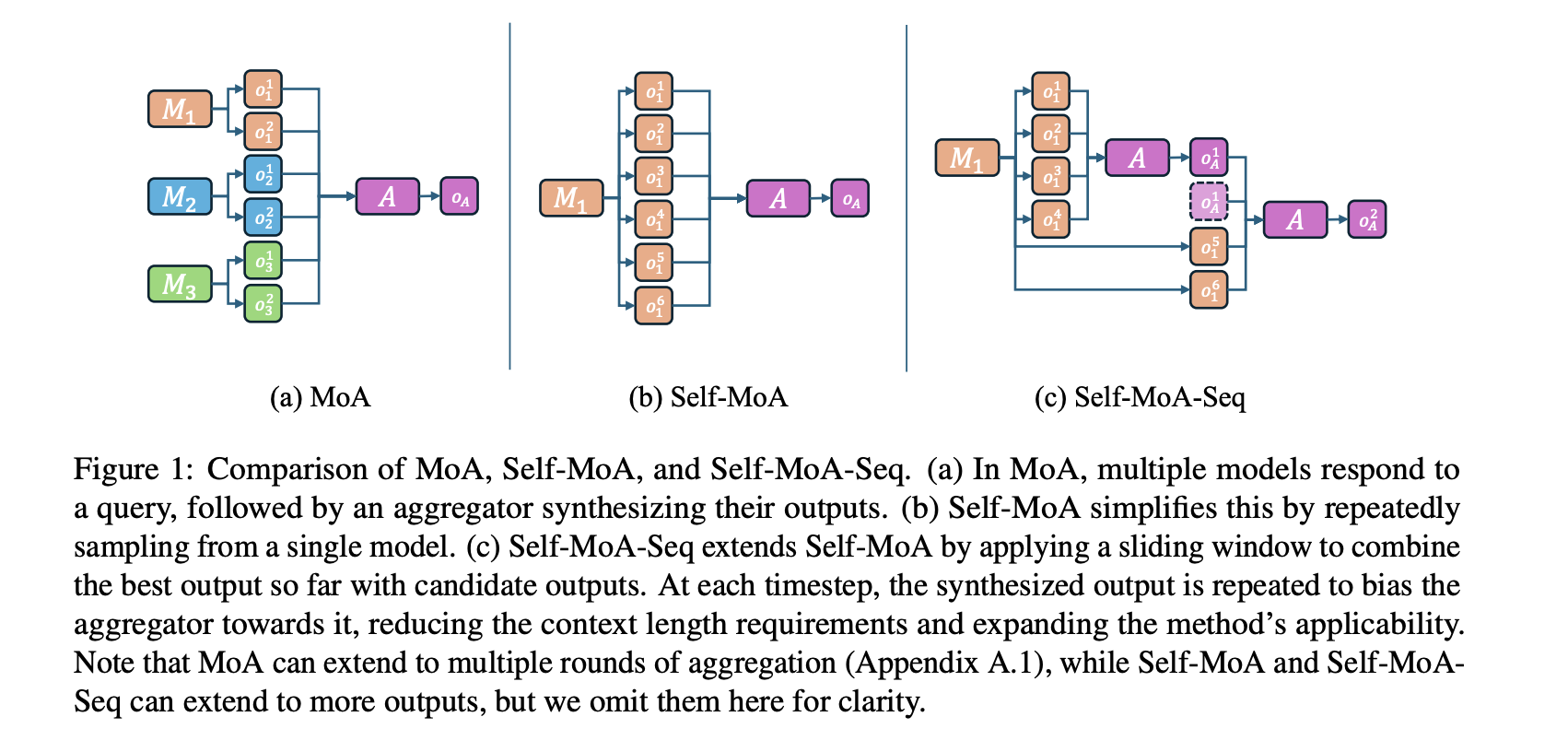
Traditional MOA frames work by first asking several suggestions models to generate answers. An aggregate model then synthesizes these answers in a final answer. The effectiveness of this method depends on the assumption that diversity among suggestions models leads to better performance. However, this assumption does not take into account potential degradation of quality caused by weaker models in the mixture. Previous research has primarily focused on increasing diversity across the model rather than optimizing the quality of the suggestion models, which has led to performance discrepancies.
A research team from Princeton University introduced Self-Moa, a new ensembling method that eliminates the need for more models by gathering different outputs from a single high-performance model. Unlike traditional MOA, mixing different LLMs, self-moan in-model utilizes diversity by repeatedly sampling from the same model. This approach ensures that only high quality responses contribute to the final output that addresses the quality of the quality diversity observed in mixed-MOA configurations.
Self-MOA works by generating multiple answers from a single top prestant model and synthesis them for a final output. This eliminates the need to incorporate lower quality models, thereby improving the overall response quality. To further improve scalability, researchers introduced self-moa-seq, a sequential variation that processes several answers iteratively. This enables effective aggregation of output, even in scenarios where calculation resources are limited. Self-MOA-SEQ Processes Outputs Using a Gliding Win Dinduet Access, which ensures that LLMs with shorter context lengths can still benefit from ensembling without compromising the performance.
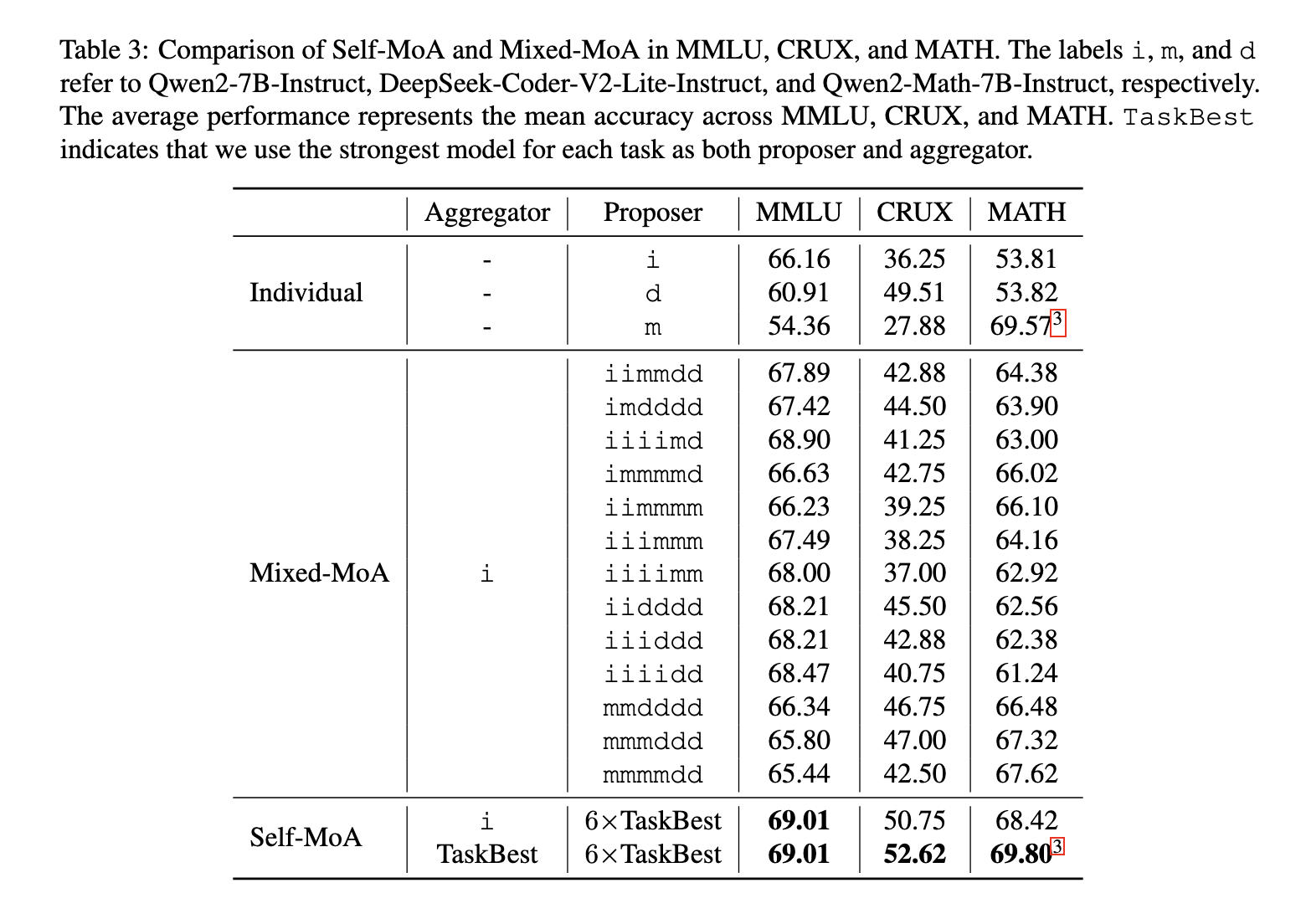
Experiments demonstrated that Self-MOA significantly surpasses Mixed-MOA across different benchmarks. At Alpacaeval 2.0-Benchmark, Self-MOA achieved an improvement of 6.6% compared to traditional MOA. When tested across multiple data sets, including MMLU, Crux and Mathematics, Self-MOA showed an average improvement of 3.8% compared to mixed MOA approaches. When used for one of the top ranked models in Alpacaeval 2.0, Self-MOA set a new advanced performance record, which further validated its effectiveness. Furthermore, self-moa-seq turned out to be as effective as collecting all outputs at the same time, while addressing the limitations imposed on model context length restrictions.
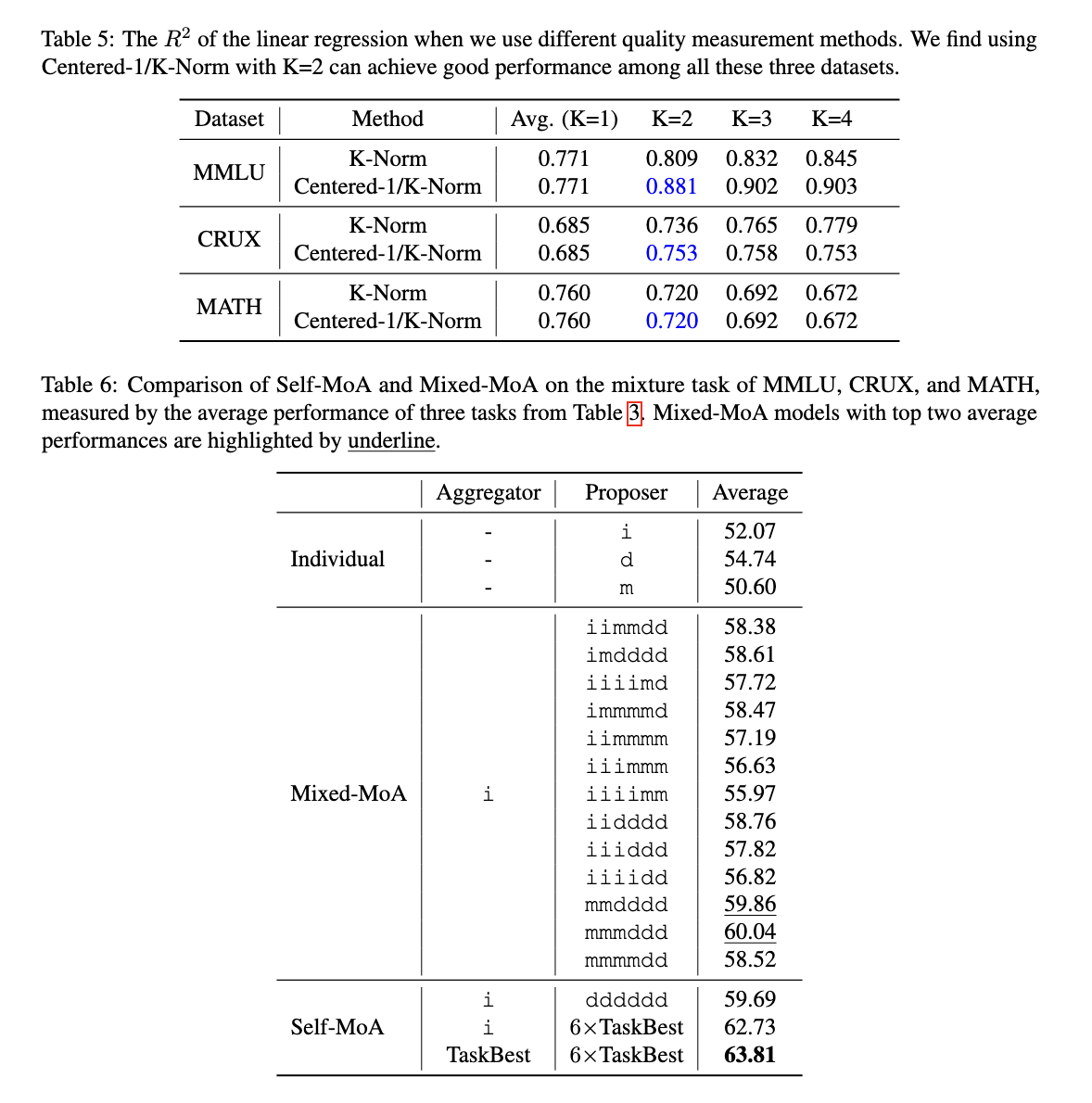
The research results highlight a crucial insight into MOA configurations – which is very sensitive to the quality of the proposal. The results confirm that the incorporation of different models does not always lead to superior performance. Instead, ensemling answers from a single high quality model provides better results. Researchers conducted over 200 experiments to analyze the exchange between quality and diversity and concluded that self-MOA consistently surpasses Mixed-MOA when the best executed model is used exclusively as proposes.
This study challenges the prevailing assumption that mixing different LLMs leads to better results. By demonstrating the superiority of self-moa, it presents a new perspective on optimizing LLM-in-in-time calculation. The results indicate that the focus on individual models of high quality rather than increasing diversity can improve the overall performance. As LLM research continues to develop, Self-MOA provides a promising alternative to traditional ensembling methods that offer an effective and scalable approach to improving model output quality.
Check out the paper. All credit for this research goes to the researchers in this project. Nor do not forget to follow us on Twitter and join in our Telegram Channel and LinkedIn GrOUP. Don’t forget to take part in our 75k+ ml subbreddit.
🚨 Recommended Open Source AI platform: ‘Intellagent is an open source multi-agent framework for evaluating complex conversation-ai system’ (Promoted)
Nikhil is an internal consultant at MarkTechpost. He is pursuing an integrated double degree in materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who always examines applications in fields such as biomaterials and biomedical science. With a strong background in material science, he explores new progress and creates opportunities to contribute.
✅ [Recommended] Join our Telegram -Canal