Quantization is a crucial technique for deep learning for reducing calculation costs and improving model efficiency. Large language models require significant treatment power, making quantization important to minimize memory consumption and improve the rate of inference. By converting high precision weights to lower bit formats, such as Int8, Int4 or InT2, quantization reduces storage requirements. However, standard techniques often deteriorate accuracy, especially at low trials such as INT2. Researchers need to compromise the accuracy of efficiency or maintain multiple models with different quantization levels. New strategies are greatly needed to maintain model quality while optimizing calculation efficiency.
The basic problem of quantization is to handle precision reduction exactly. The available approaches are training either unique models per. Precision or does not benefit from the hierarchical nature of the intestine. Quantization of accuracy, as in the case of Int2, is most difficult because its memory gets inhibits widespread use. LLMS such as Gemma-2 9B and Mistral 7B are very calculated intensive, and a technique that allows a single model to function at multiple precision levels would significantly improve efficiency. The necessity of a high -performance, flexible quantization method has led researchers to seek solutions outside conventional methods.
There are several quantization techniques, each balancing accuracy and efficiency. Learning -free methods such as Minmax and GPTQ use statistical scaling to map model weights to lower bit widths without changing parameters, but they lose accuracy at low trials. Learning -based methods such as Quantization AWARE TRAINING (QAT) and ubiquitous optimizing quantization parameters using gradient displacement. Qat updates model parameters to reduce losses by quantization accuracy, while ubiquitous learns to scale and change parameters without changing nuclear weights. However, both methods still require separate models for different trials that complicate implementation.
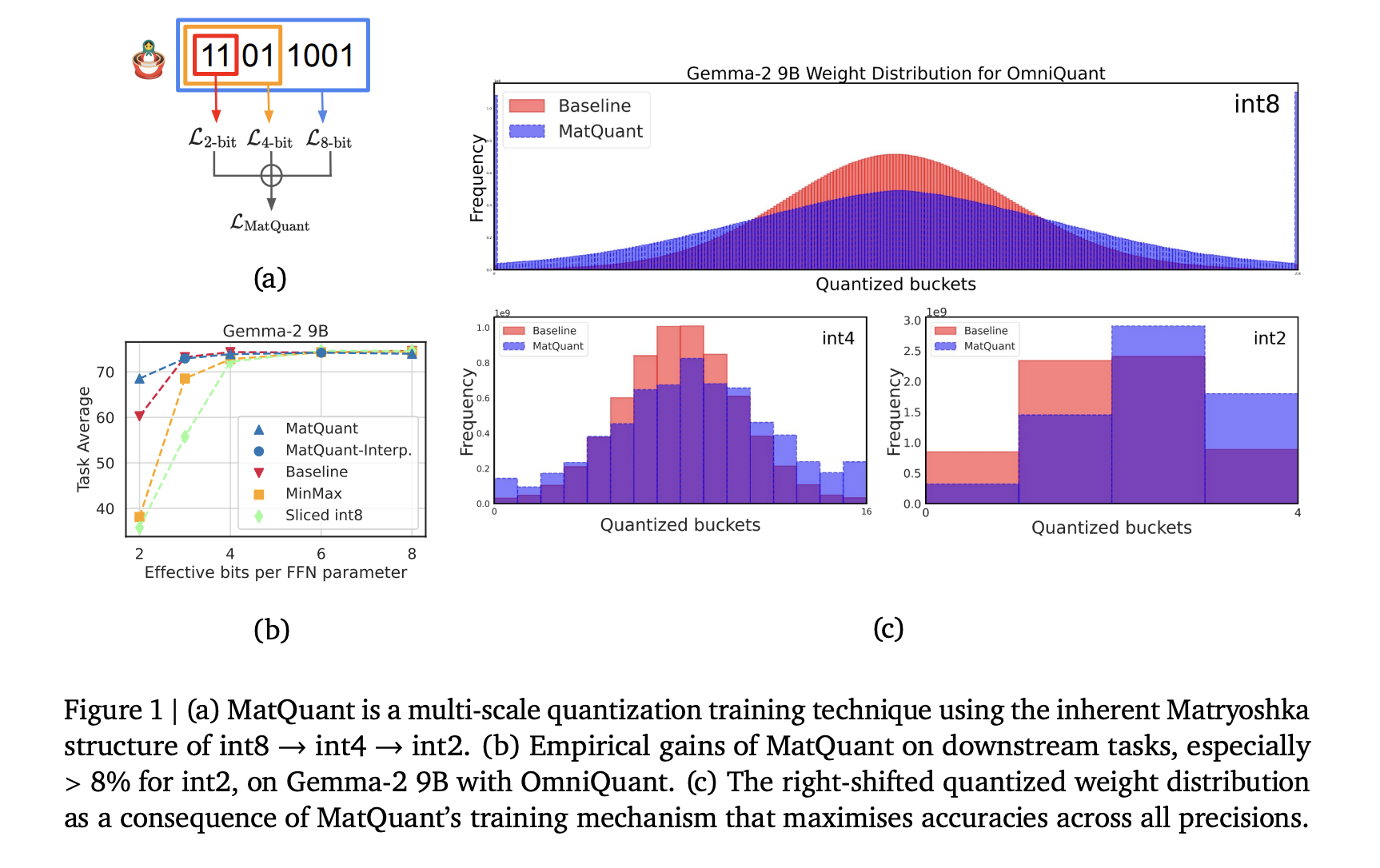
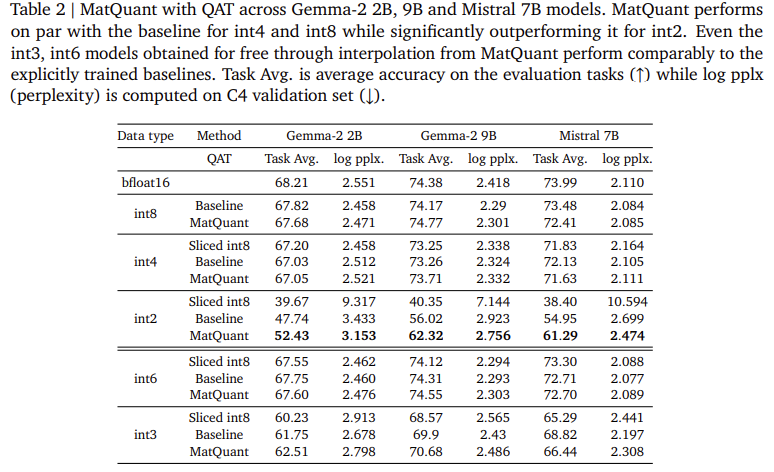
Researchers on Google Deepmind introduced Matryoshka Quantization (Matquant) To create a single model that works across multiple precision levels. Unlike conventional methods that treat each bit width separately, Matquant optimizes a model for InT8, Int4 and InT2 using a shared bitter representation. This makes it possible to implement models at different reimbursements without retraining, which reduces calculation and storage costs. Matquant extracts lower bit models from a high Bit model while retaining accuracy by utilizing the hierarchical structure of heroaltate types. Testing on Gemma-2 2B, Gemma-2 9B and Mistral 7B models showed that Matquant improves the Int2 accuracy by up to 10% compared to standard quantization techniques such as Qat and ubiquitous.
Matquant represents model weights at different precision levels using shared most significant bits (MSBs) and optimizes them together to maintain accuracy. The education process incorporates co-training and co-distillation, ensuring that the Int2 representation retains critical information that is typically lost in conventional quantization. Instead of discarding lower bit structures, Matquant integrates them into a multi-scale optimization frame for effective compression without performance loss.
Experimental evaluations of Matquant demonstrate his ability to mitigate accuracy loss from quantization. Researchers tested the method of transformer -based LLMs focusing on quantizing forward network (FFN) parameters, a key factor in Inferens Latency. The results show that Matquant’s Int8 and Int4 models achieve comparable accuracy with independently trained basic lines while surpassing them at Int2 Precision. On the Gemma-2 9B model, Matquant Int2 accuracy improved by 8.01%, while the Mistral 7B model experienced an improvement of 6.35% over traditional quantization methods. The study also found that Matquant’s right changed quantized weight distribution improves accuracy across all bit width, especially for the benefit of lower precision models. Matquant also enables trouble-free interpolating bit width and layer mix’n’match configurations, allowing flexible implementation based on hardware constraints.

Several important takeaways appear in the research on Matquant:
- Multi-scale quantization: Matquant introduces a new approach to quantization by training a single model that can work at several precision levels (eg Int8, Int4, Int2).
- Nestet bit structure utilization: The technique utilizes the inherent embedded structure within heroaltate types, enabling less Bit-width integers to be derived from greater.
- Improved accuracy with low precision: Matquant improves the accuracy of Int2 quantized models, surpassing traditional quantization methods such as Qat and ubiquitous by up to 8%.
- Versatile Use: Matquant is compatible with existing learning -based quantization techniques such as Quantization Aware Training (QAT) and Omniquant.
- Demonstrated Performance: The method was successfully used to quantize the FFN parameters for LLMs such as Gemma-2 2B, 9B and Mistral 7B, showing its practical tools.
- Efficiency gains: Matquant enables the creation of models that offer a better change between accuracy and calculation costs, making it ideal for resource -limited environments.
- Pareto-Optimal trade-offs: It allows for trouble-free extraction of interpolative bit width, such as Int6 and INT3, and admits a close accuracy-VS-VS Cost Pareto-Optimal Compromise by enabling Layer Mix’n’match of different precisions.
Finally, Matquant presents a solution to control multiple quantized models by using a multi -scale training method that utilizes the embedded structure of heroal types. This provides a flexible, high-performance option for low-bit quantization in effective LLM inference. This research shows that a single model can be trained to operate at several precision levels without significantly declining accuracy, especially at very low bit widths, marking an important increase in model quantization techniques.
Check out the paper. All credit for this research goes to the researchers in this project. You are also welcome to follow us on Twitter And don’t forget to join our 75k+ ml subbreddit.
🚨 Recommended Open Source AI platform: ‘Intellagent is an open source multi-agent framework for evaluation of complex conversation-a-system‘ (Promoted)
Asif Razzaq is CEO of Marketchpost Media Inc. His latest endeavor is the launch of an artificial intelligence media platform, market post that stands out for its in -depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts over 2 million monthly views and illustrates its popularity among the audience.
✅ [Recommended] Join our Telegram -Canal