Large Language Models (LLMS) Generate text step by step, limiting their ability to plan for tasks that require multiple reasoning steps, such as structured writing or problem solving. This lack of prolonged planning affects their coherence and decision -making in complex scenarios. Some approaches evaluate different alternatives before making a choice, which improves prediction precision. However, they have higher calculation costs and are prone to errors whose future forecasts were incorrect.
Apparently search algorithms like Monte Carlo Tree Search (MCS) and beam search is liked in AI planning and decision-making, but lacks inherent restrictions. They use repeated simulations of the future with increasing calculation costs and make them unsuitable for real -time systems. They also depend on a value model to estimate any state which, if wrong, propagates the error along the search. As longer predictions create more errors, build up and reduce these errors and reduce decision -making accuracy. This is especially problematic in complicated tasks that require long -term planning where it becomes challenging to maintain accurate foresight, resulting in subordinate results.
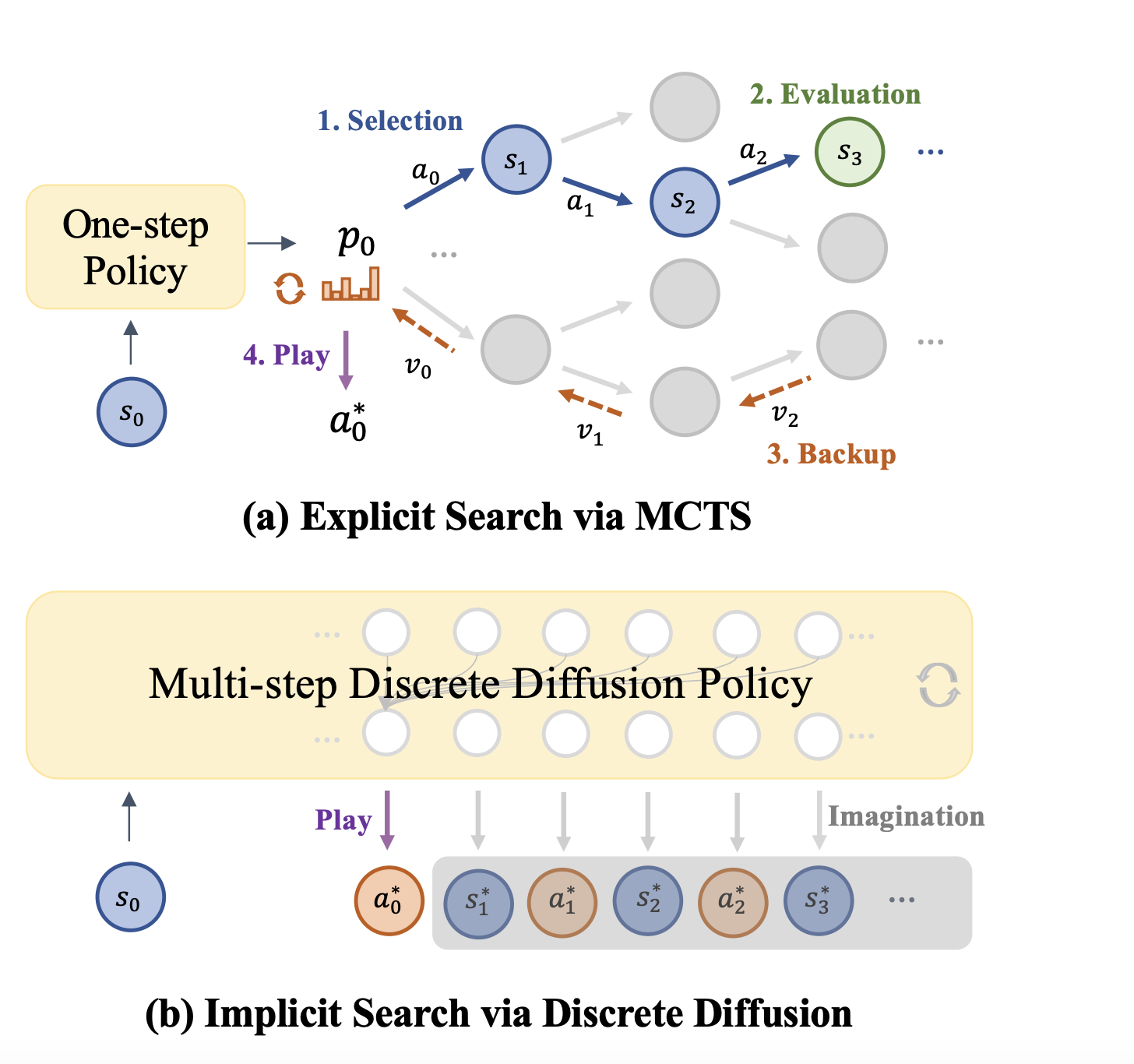
To mitigate these questions, scientists from University of Hong Kong, Shanghai Jiaotong University, Huawei Noah’s Ark Lab, and Shanghai AI Laboratory proposed Diffusearch. This discreet diffusion -based framework eliminates explicit search algorithms as McS. Instead of relying on expensive search processes, diffusearch is training the policy to directly predict and use future representations, it iterative using diffusion models using diffusion models. The integration of the world model and the policy into a single framework reduces the calculation cost, while the efficiency and accuracy are improved in long -term planning.
The framework trains the model using monitored learning and utilizes Stockfish as an Oracle to feel board states from chess games. Different future representations are examined with the Action State (S-A-ASA) method selected for simplicity and efficiency. Instead of directly predicting future sequences, the model uses discreet diffusion modeling that uses self -perception and iterative denoising to improve advancies of action gradually. Diffusearch avoids costly marginalization over future conditions under inference by direct sampling from the trained model. An easy-to-first decoding strategy prioritizes more predictable denoising symbols, improvement of accuracy.
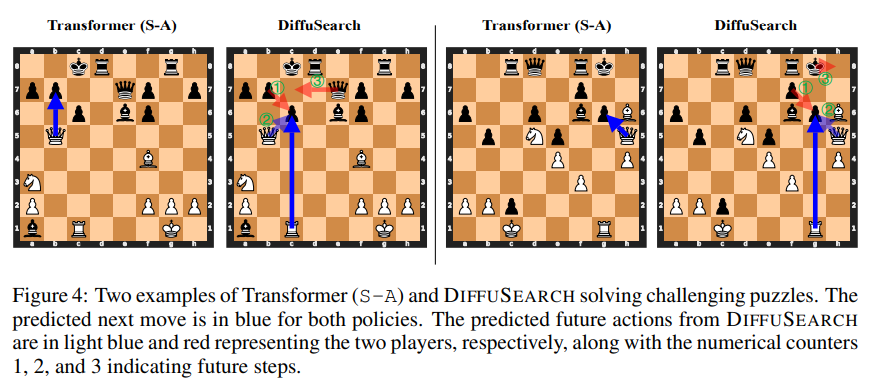
Researchers assessed Diffusearch Against three transformer-based basic lines: State Action (SA), State Value (SV) and Action Value (SA-V) models trained using behavioral cloning, value-based decision-making and comparison of legal action. Using a Dataset of 100k Chess Games, With States Encoded in Fen Format and Actions In UCI Notation, They Implemented GPT-2-Based Models With An Adam Optimizer, A 3E-4 Learning Rate, A Batch Size of 1024, An 8-Layer Architecture (7M Parameters), A Horizon of 4, and Diffusion Timesteps Set to 20. Diffusearch surpassed SA with 653 Elo and 19% In action accuracy and exceeded SA-V despite having used 20 times fewer data registers. Discreet diffusion with linear λt achieved the highest accuracy (41.31%), Surpass authentic and Gaussian methods. Diffusearch retained prediction ability in future movements, although accuracy fell over steps, and performance improved with more attention layers and refined decoding. Located as an implicit search method, the competitiveness demonstrated with explicit MCTS-based approaches.

In summary, the proposed model noted that implicit search via discreet diffusion could effectively replace explicit search and improve the chess decision. The model surpassed searcheless and explicit policies and showed its potential to learn future-imitative strategies. Although the use of an external oracle and a limited data set indicated the model of future opportunities for improvement through self-play and long-context modeling. More generally, this method can be used to improve the next token prediction in language models. As a starting point for further examination, it forms a basis for examining implicit search in AI planning and decision making.
Check out The paper and the github side. All credit for this research goes to the researchers in this project. You are also welcome to follow us on Twitter And don’t forget to join our 80k+ ml subbreddit.
🚨 Recommended Reading AI Research Release Nexus: An Advanced System Integrating Agent AI system and Data Processing Standards To Tackle Legal Concerns In Ai Data Set
Divyesh is a consulting intern at MarkTechpost. He is pursuing a BTech in agricultural and food technology from the Indian Institute of Technology, Kharagpur. He is a data science and machine learning enthusiast who wants to integrate these leading technologies into the agricultural domain and solve challenges.
🚨 Recommended Open Source AI platform: ‘Intellagent is an open source multi-agent framework for evaluating complex conversation-ai system’ (promoted)