Fine tuning of LLMs often requires extensive resources, time and memory, challenges that can prevent rapid experimentation and implementation. Unloth AI revolutionizes this process by enabling fast, efficient fine-tuning of advanced models such as QWEN3-14B with minimal GPU memory, utilizing advanced techniques such as 4-bit quantization and Lora (low-rank adjustment). In this tutorial, we go through a practical implementation on Google Colab to fine-tune QWEN3-14B using a combination of reasoning and instructional data sets that combine Unloth’s FastLanguag Model tools with TRL.SftTrainer users can achieve a strong fine-tuning of the service with just consumption degree.
%%capture
import os
if "COLAB_" not in "".join(os.environ.keys()):
!pip install unsloth
else:
!pip install --no-deps bitsandbytes accelerate xformers==0.0.29.post3 peft trl==0.15.2 triton cut_cross_entropy unsloth_zoo
!pip install sentencepiece protobuf "datasets>=3.4.1" huggingface_hub hf_transfer
!pip install --no-deps unslothWe install all the important libraries required to fine-tune the QWEN3 model using Unloth AI. It installs conditional dependencies based on the environment using a slight approach to Colab to ensure compatibility and reduce overhead. Key components such as Bitsandbytes, TRL, Xformers and Unsloth_ZOO are included to enable 4-bit quantized training and Lora-based optimization.
from unsloth import FastLanguageModel
import torch
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/Qwen3-14B",
max_seq_length = 2048,
load_in_4bit = True,
load_in_8bit = False,
full_finetuning = False,
)
We load the QWEN3-14B model using Fastlanguag Model from Unloth Library, which is optimized for effective fine tuning. It initializes the model with a context length of 2048 symbols and loads it into 4-bit precision, which significantly reduces memory consumption. Full fine -tuning is disabled, making it suitable for light parameter -efficient techniques like Lora.
model = FastLanguageModel.get_peft_model(
model,
r = 32,
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj"],
lora_alpha = 32,
lora_dropout = 0,
bias = "none",
use_gradient_checkpointing = "unsloth",
random_state = 3407,
use_rslora = False,
loftq_config = None,
)
We apply Lora (low rank custom) to the QWEN3 model using Fastlanguagmodel.get_peft_model. The injections of training bare adapters into specific transformer layers (such as Q_Proj, V_Proj, etc.) with a rank of 32, enabling effective fine tuning, while most model weights are frozen. Using the “Non -Sloth” gradient control pointing further optimizes memory consumption, making it suitable for training large models on limited hardware.
from datasets import load_dataset
reasoning_dataset = load_dataset("unsloth/OpenMathReasoning-mini", split="cot")
non_reasoning_dataset = load_dataset("mlabonne/FineTome-100k", split="train")We load two pre -curated data sets from Hugging Face Hub using the library. The reasoning_dataset contains problems with chain-afhoughthought problems from Unloth’s OpenMathreasoning mini, designed to improve logical reasoning in the model. Non_Reasoning_dataset draws general instructional data from Mlabonne’s Finetome-100K, which helps the model learn broader conversation and task-oriented skills. Together, these data sets support a rounded fine tuning target.
def generate_conversation(examples):
problems = examples["problem"]
solutions = examples["generated_solution"]
conversations = []
for problem, solution in zip(problems, solutions):
conversations.append([
{"role": "user", "content": problem},
{"role": "assistant", "content": solution},
])
return {"conversations": conversations}This feature, Genry_conversation, transforms raw question-answer couples from the justification data set to a chat style format suitable for fine tuning. For each problem and its correspondingly generated solution, a conversation is conducted where the user asks a question and the assistant gives the answer. The output is a list of dictionaries according to the structure expected of chat-based language models preparing the data for tokenization with a chat template.
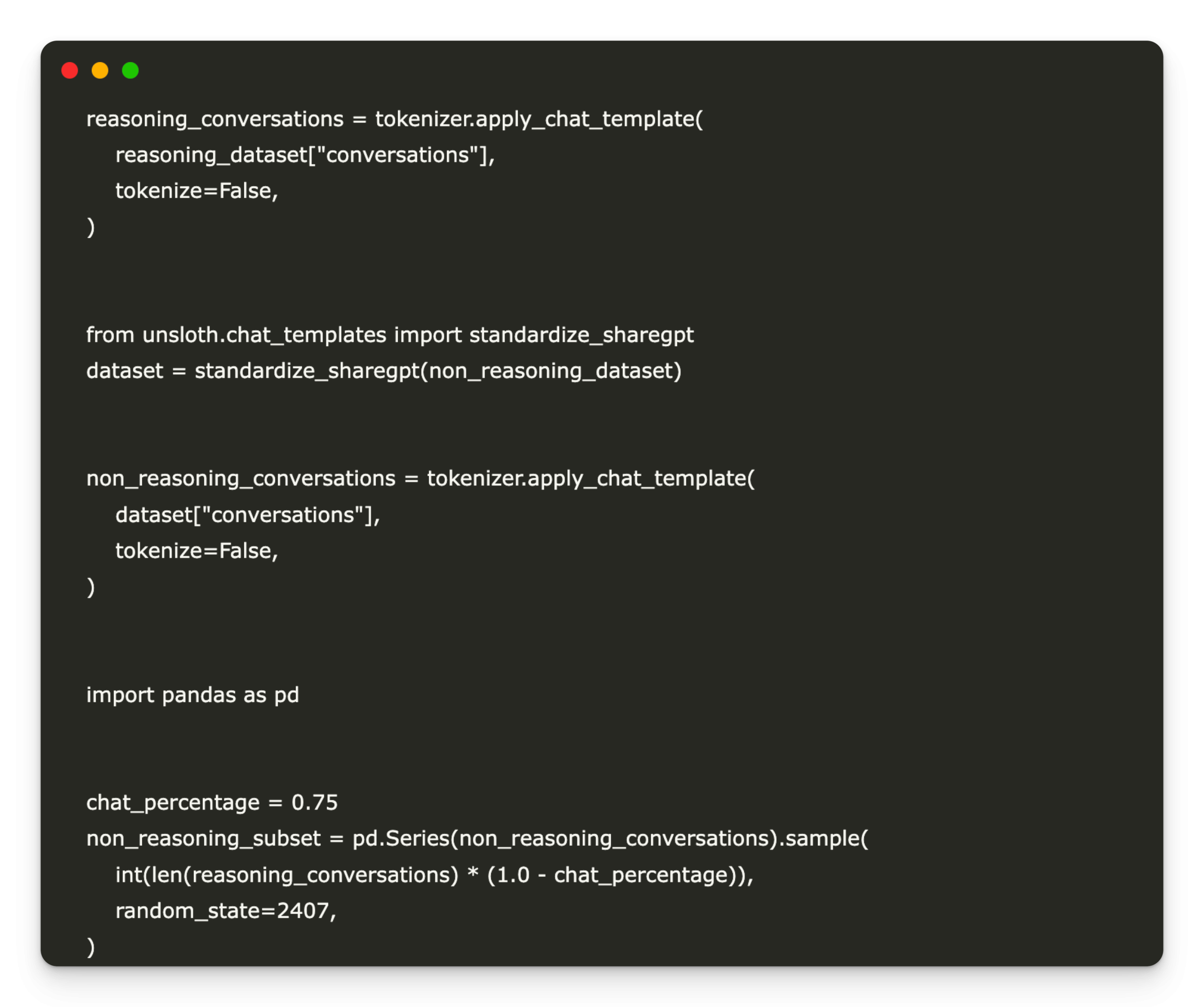
reasoning_conversations = tokenizer.apply_chat_template(
reasoning_dataset["conversations"],
tokenize=False,
)
from unsloth.chat_templates import standardize_sharegpt
dataset = standardize_sharegpt(non_reasoning_dataset)
non_reasoning_conversations = tokenizer.apply_chat_template(
dataset["conversations"],
tokenize=False,
)
import pandas as pd
chat_percentage = 0.75
non_reasoning_subset = pd.Series(non_reasoning_conversations).sample(
int(len(reasoning_conversations) * (1.0 - chat_percentage)),
random_state=2407,
)
data = pd.concat([
pd.Series(reasoning_conversations),
pd.Series(non_reasoning_subset)
])
data.name = "text"We prepare the fine -tuning data set by converting reasoning and instructional data set to a consistent chat format and then combining them. It first uses Tokenizer’s Apply_chat_template to convert structured conversations to tokenizable strings. The Standardize_Shargpt feature normalizes the instructional data set to a compatible structure. Then a 75-25 mixture is created by sampling 25% of the non-riding (instruction) conversations and combining them with the reasoning data. This mixture ensures that the model is exposed to logical reasoning and general instructional tasks, which improves its versatility during training. The final combined data is stored as a single column Pandas series called “Text”.
from datasets import Dataset
combined_dataset = Dataset.from_pandas(pd.DataFrame(data))
combined_dataset = combined_dataset.shuffle(seed=3407)
from trl import SFTTrainer, SFTConfig
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=combined_dataset,
eval_dataset=None,
args=SFTConfig(
dataset_text_field="text",
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
warmup_steps=5,
max_steps=30,
learning_rate=2e-4,
logging_steps=1,
optim="adamw_8bit",
weight_decay=0.01,
lr_scheduler_type="linear",
seed=3407,
report_to="none",
)
)
We take the processed conversations, wrap them in a hugged face data set (ensures that the data is in a consistent format), and mix the data set with a solid seed for reproducibility. Then the fine -tuning trainer is initialized using TRLS Sfttrainer and SftConfig. The coach is set to use the combined data set (with the text column called “text”) and defines training of hyperparameters such as batch size, gradient collection, number of heating and training steps, learning speed, optimizer parameters and a linear learning speed planning. This configuration is aimed at effective fine -tuning while maintaining reproducibility and logs minimal details (with report_to = “none”).
Trainer.Train () starts the fine-tuning process for the QWEN3-14B model using SFTTrainer. It trains the model of the prepared mixed data set with reasoning and instructional conversations that only optimize the Lora-adapted parameters thanks to the underlying unclear setup. Exercise continues according to the previously specified configuration (eg max_steps = 30, batch_size = 2, lr = 2e-4), and progress is printed each logging stage. This final command launches the actual model adaptation based on your custom data.
model.save_pretrained("qwen3-finetuned-colab")
tokenizer.save_pretrained("qwen3-finetuned-colab")We save the fine-tuned model and tokenizer locally to the “QWEN3-FINNETUNED-COLAB” catalog. By calling Save_Pretrained (), the customized weights and tokenizer configuration can be released later to inference or further education, locally or to upload to the hugging face hub.
In conclusion, using non-sloth AI, is fine-tuning of massive LLMs such as QWEN3-14B feasible using limited resources and is extremely effective and accessible. This tutorial demonstrated how to load a 4-bit quantized version of the model, uses structured chat templates, mixes multiple data sets for better generalization and trainer using TRLS SFTTrainer. Whether you are building custom assistants or specialized domain models, Unloth’s tools are dramatically reducing the barrier for fine -tuning on scale. As open source fine-tuning ecosystems develops, Unloth continues to lead to making LLM training faster, cheaper and more convenient for everyone.
Check Colab Notebook. All credit for this research goes to the researchers in this project. You are also welcome to follow us on Twitter And don’t forget to join our 95k+ ml subbreddit and subscribe to Our newsletter.
Asif Razzaq is CEO of Marketchpost Media Inc. His latest endeavor is the launch of an artificial intelligence media platform, market post that stands out for its in -depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts over 2 million monthly views and illustrates its popularity among the audience.
🚨 Build Genai you can trust. ⭐ Parlant is your open source engine for controlled, compatible and targeted AI conversations-star parlant on GitHub! (Promoted)