Text Development and Restriction are fundamental to modern information systems that operate applications such as semantic search, recommendation systems and retrieval-augmented generation (RAG). However, the current approaches often face the most important challenges – especially to achieve both high multilingual beliefs and the adaptability of the task without relying on proprietary APIs. Existing models often fall short in scenarios that require nuanced semantic understanding across multiple languages or domain -specific tasks such as code collection and instruction after. In addition, most open source models lack either scale or flexibility, while commercial APIs remain expensive and closed.
QWEN3 DEBT AND QWEN3 RERANCE: A new default for open source in-camp
Alibaba’s Qwen team has revealed the QWEN3 injury and QWEN3-Rerancher series models that put a new benchmark in multilingual textual hire and relevance ranking. The series is built on the QWEN3 Foundation models and includes variants in 0.6B, 4B and 8B parameter sizes and supports a wide range of languages (119 in total), making it one of the most versatile and performing open-source offers to date. These models are now open sourced under the Apache 2.0 license on embraced face, GitHub and Modelsscope and are also available via Alibaba Cloud APIs.
These models are optimized for use cases such as semantic retrieval, classification, rag, sentiment analysis and code search – providing a strong alternative to existing solutions such as Gemini Development and Openai’s embedding of APIs.
Technical architecture
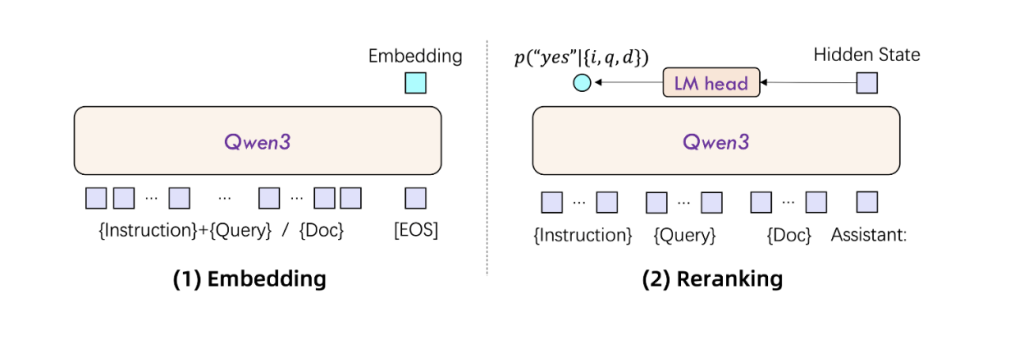
QWEN3 Empire models adopt a dense transformer-based architecture with causal attention that produces embedders by extracting the hidden condition that corresponds to [EOS] Token. Instructions awareness is a key function: Input queries are formatted as {instruction} {query}<|endoftext|>that enables task -conditioned embedders. The Reranches models are trained with a binary classification format that assesses relevance to document-torses in an instruction-controlled way using a token-probe-based scoring function.
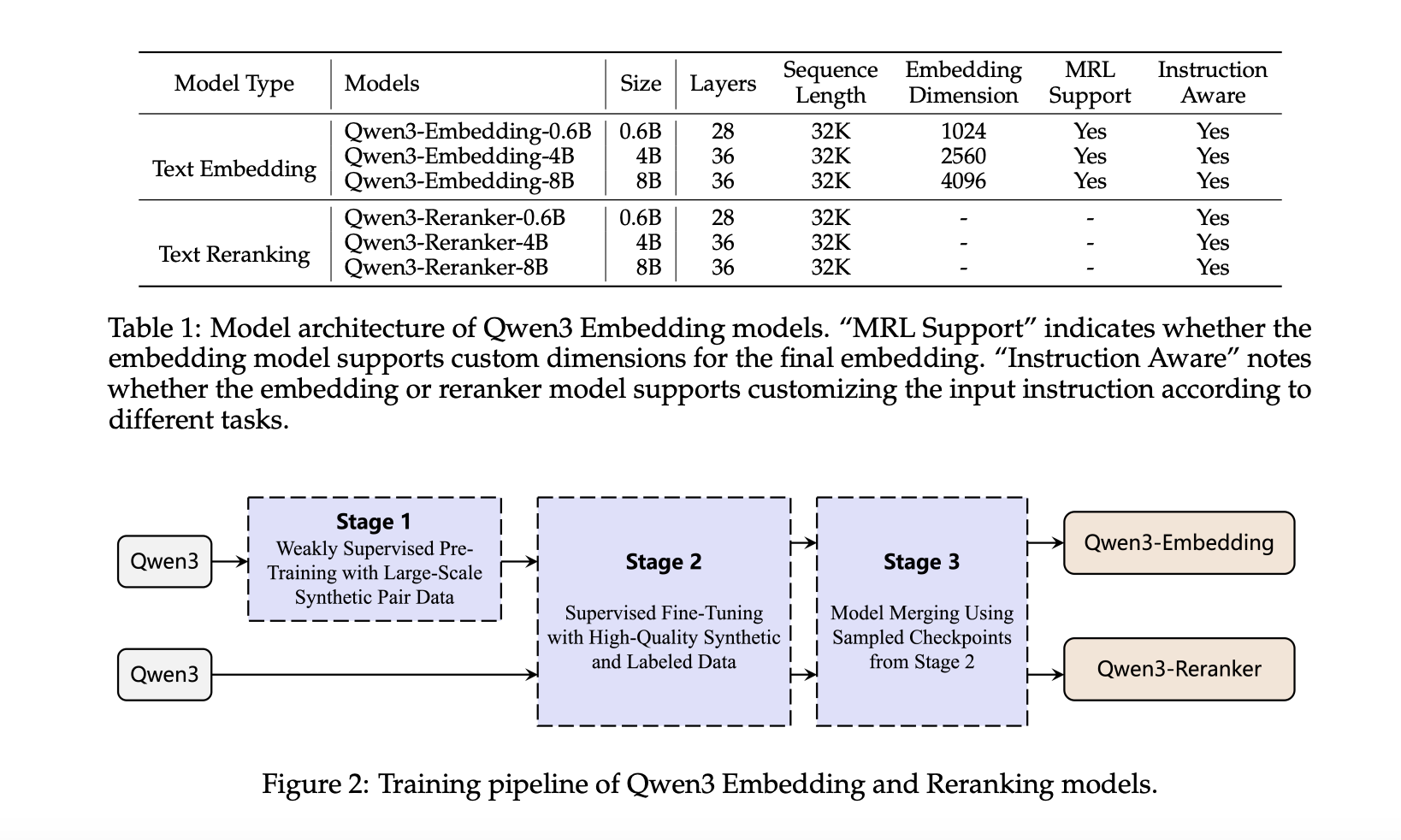
The models are trained using a sturdy multi -stage training pipeline:
- Large -scale weak supervision: 150 m of synthetic workouts generated using QWEN3-32B, which covers retrieval, classification, STS and BitXT mining across languages and tasks.
- Monitored fine tuning: High quality 12M data bars are selected by means of Kosinus equality (> 0.7), and fine -tuning of the performance in downstream applications.
- Model Fusion: Sheric linear interpolation (SLERP) of several fine -tuned control points ensures robustness and generalization.
This synthetic data rating pipeline enables control of data quality, language diversity, task ability and more-results to a high degree of coverage and relevance in low resource settings.
Performance Benchmarks and Insight
QWEN3 Empire and Qwen3 Rerancher series demonstrates strong empirical performance across several multilingual benchmarks.
- At mmteb (216 assignments across 250+ languages), QWEN3-Development-8B achieves an average task score on 70.58surpassed Gemini and GTE-QWEN2 series.
- On MTEB (English V2): Qwen3-in-end-8b when 75.22Better than other open models, including NV-lap-V2 and GritLM-7B.
- On MTEB code: QWEN3 Development-8B leads with 80.68is distinguished in applications such as code collection and stack overflow QA.
For reorganization:
- QWEN3-RERANKER-0.6B is already surpassing Jina and BGE Rerankers.
- QWEN3-RERANKER-8B achieves 81.22 on MTEB code and 72.94 On MMTEB-R that marks advanced performance.
Ablation studies confirm the necessity of each training stage. Removal of synthetic prior or model fusion led to significant benefit drops (up to 6 points on MMTEB), emphasized their contribution.
Conclusion
Alibaba’s QWEN3-incidental and QWEN3-Rerancher series presents a robust, open and scalable solution to multilingual and instruction-conscious semantic representation. With strong empirical results across MTEB, MMTEB and MTEB code, these models build the gap between proprietary APIs and opening of open source. Their thought-provoking training design-to increase high quality synthetic data, instructional reconciliation and model mergers-placing them as ideal candidates for corporate applications in search, retrieval and rag pipes. By opening these models, the QWEN team not only pushes the limits of language understanding, but also gives the wider community to innovate on top of a solid foundation.
Check the paper, technical details, QWEN3 in-damages and QWEN3 re-anchor. All credit for this research goes to the researchers in this project. You are also welcome to follow us on Twitter And don’t forget to join our 95k+ ml subbreddit and subscribe to Our newsletter.
Asif Razzaq is CEO of Marketchpost Media Inc. His latest endeavor is the launch of an artificial intelligence media platform, market post that stands out for its in -depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts over 2 million monthly views and illustrates its popularity among the audience.