The rapid development of artificial intelligence (AI) has launched a new era with large language models (LLMs) capable of understanding and generating human -like text. However, the proprietary nature of many of these models constitutes challenges for accessibility, collaboration and transparency within the research community. In addition, the significant calculation resources required to educate such models often restrict participation in well -funded organizations, thereby hindering broader innovation.
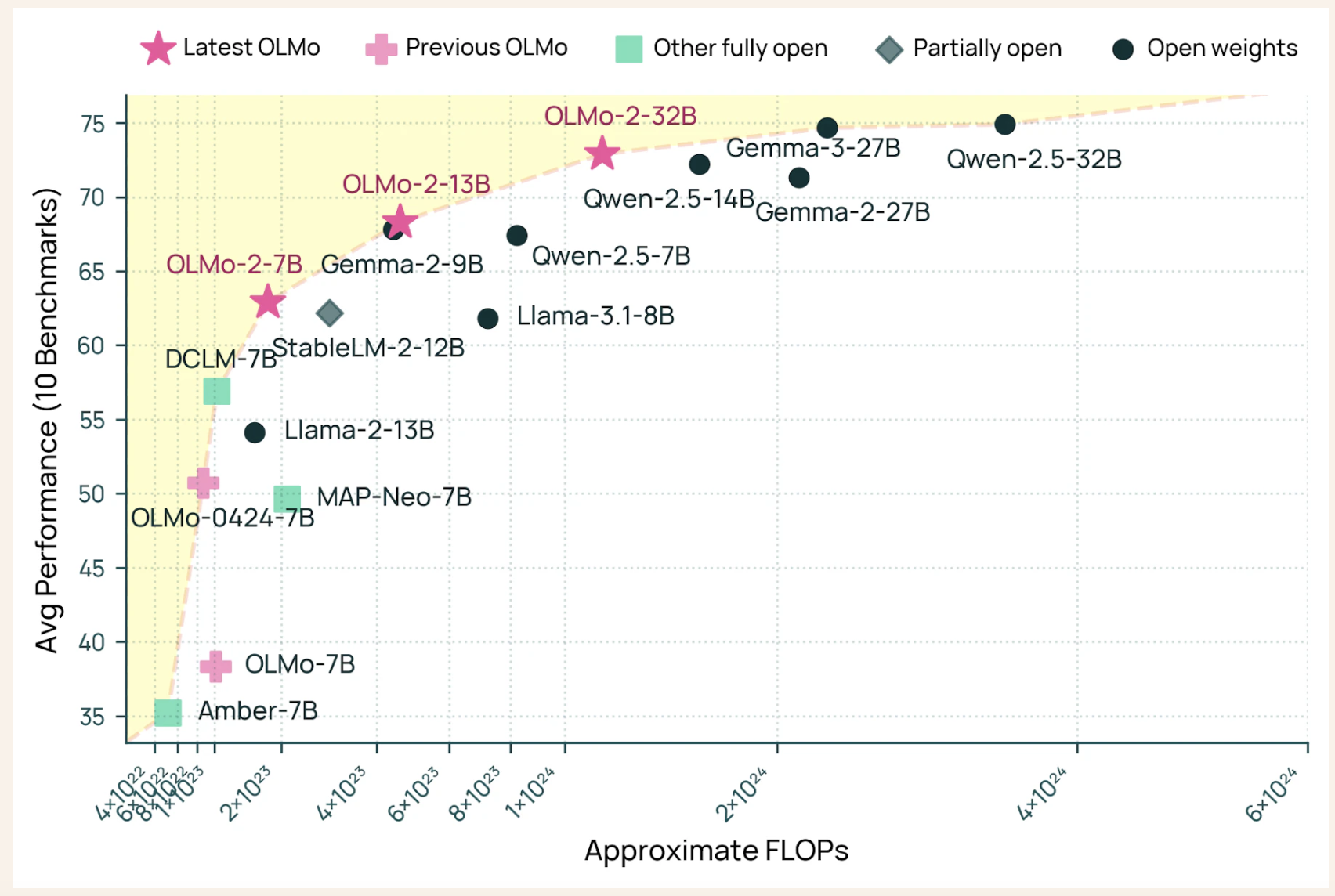
By tackling these concerns, Allen Institute for AI (AI2) has introduced Olmo 2 32B, the latest and most advanced model in the Olmo 2 series. This model differs as the first fully open model that surpasses the GPT-3.5 Turbo and GPT-4o Mini over a package of widely recognized academic benchmarks with multiple skills. By making all data, code, weights and training details that are freely available, AI2 promotes a culture of openness and collaboration, enabling researchers around the world to build on this work.
Olmo 2 32B’s architecture includes 32 billion parameters, reflecting a significant scaling from its predecessors. The educational process was carefully structured in two primary stages: prior and mid -training. Under the prior, the model was exposed to approx. 3.9 trillion tokens from various sources, including DCLM, Dolma, Starcoder and Proof Pile II, ensuring a comprehensive understanding of language patterns. The mid-training phase used the Dolmino data set, which consists of 843 billion tokens curated for quality, which includes educational, mathematical and academic content. This phase approach ensured that Olmo 2 32B developed a robust and nuanced grip on language.
A remarkable aspect of Olmo 2 32B is its exercise efficiency. The model achieved benefit levels comparable to leading open-weight models, while it used only a fraction of calculation resources. Specifically, it required approximately one-third of the training calculation compared to models such as QWEN 2.5 32B, which highlighted AI2’s commitment to resource-efficient AI development.
In Benchmark evaluations, OLMO 2 32B demonstrated impressive results. It matched or exceeded the performance of models such as GPT-3.5 Turbo, GPT-4o Mini, Qwen 2.5 32B and Mistral 24b. In addition, it approached the performance levels for larger models such as Qwen 2.5 72B and Llama 3.1 and 3.3 70b. These assessments span various tasks, including massive multitask language understanding (MMLU), math problem (mathematics) and instructional evaluations (ifeval), which emphasizes the model’s versatility and competence across different linguistic challenges.
The release of Olmo 2 32B denotes a central progress in the pursuit of open and accessible AI. By providing a completely open model that not only competes with but also exceeds certain proprietary models, AI2 exceeds how thought -provoking scaling and effective training methods can lead to significant breakthroughs. This openness promotes a more inclusive and collaborative environment that allows researchers and developers to engage in and contribute to the evolving landscape of artificial intelligence.
Check out The technical details, HF project and GitHub side. All credit for this research goes to the researchers in this project. You are also welcome to follow us on Twitter And don’t forget to join our 80k+ ml subbreddit.
Asif Razzaq is CEO of Marketchpost Media Inc. His latest endeavor is the launch of an artificial intelligence media platform, market post that stands out for its in -depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts over 2 million monthly views and illustrates its popularity among the audience.
Parlant: Build Reliable AI customer facing agents with llms 💬 ✅ (promoted)