
Authoric image generation is shaped by progress in sequential modeling, originally in natural language processing. This field focuses on generating images one token at a time, similar to how phrases are constructed in language models. The appeal to this approach lies in its ability to maintain structural correlation across the image, while enabling high control levels during the generation process. When researchers began using these techniques for visual data, they found that structured prediction not only preserved spatial integrity, but also supported tasks such as image manipulation and multimodal translation effectively.
Despite these benefits, generation of high -resolution images remains calculated expensive and slow. A primary problem is the number of tokens needed to represent complex visuals. Raster-scan methods that flat 2D images to linear sequences require thousands of tokens for detailed images, resulting in long in-free times and high memory consumption. Models like Infinity need over 10,000 tokens for a 1024 × 1024 image. This becomes unsustainable for real -time applications or when scaled to more comprehensive data sets. Reducing the token burden while retaining or improving the output quality has become an urgent challenge.
The efforts to mitigate the token inflation has led to innovations as the next scale prediction seen in Var and Flexvar. These models create images by predicting gradually finer scales, mimicking the human tendency to draw rough contours before adding details. However, they still depend on hundreds of tokens – 680 in case of VAR and Flexvar to 256 × 256 images. In addition, approaches like Titok and Flextok 1D use tookenization to compress spatial redundancy, but they often fail to scale effectively. E.g. Says Flextoks GFID from 1.9 at 32 tokens to 2.5 at 256 tokens, which highlights a degradation in output quality as the token number grows.
Researchers from Bytedance introduced details flow, a 1D autorgressive image generation frame. This method arranges token sequences from Global to Fine Details using a process called prediction of the next detail. Unlike traditional 2D-raster-scan or scale-based techniques, retail flow uses a 1D-tokenizer trained in gradually degraded images. This design allows the model to prioritize basic image structures before refined visual details. By mapping tokens directly to resolution levels, retail flow significantly reduces the requirements for token, which makes it possible to generate images in a semantically ordered, coarse to fine way.
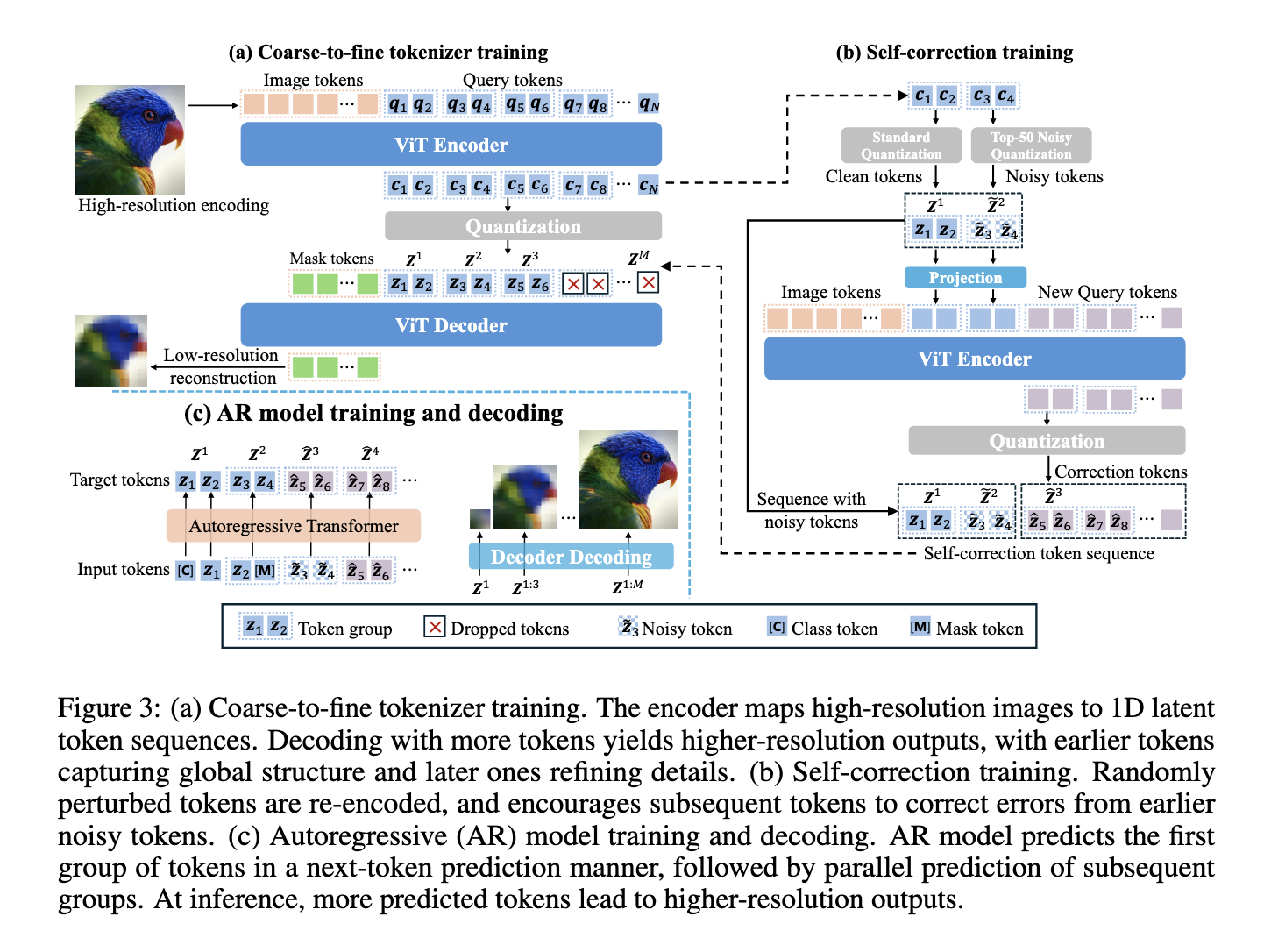
The mechanism of retail flow centers on a 1D -latent space, with each token contributing step -by -step more detailed. Former tokens codes for global features, while later token’s refining specific visual aspects. To train this, the researchers created a resolution card feature that connects token counting with the target resolution. During training, the model is exposed to images of different quality levels and learns to predict gradual output in higher resolution when more tokens are introduced. It also implements parallel token prediction by grouping sequences and predicting the entire set at once. As parallel prediction can introduce sampling errors, a self -correction mechanism was integrated. This system interferes with certain tokens during training and teaches to the tokens to compensate, ensuring that the final images maintain structural and visual integrity.
The results of the experiments on the image of 256 × 256 benchmark were remarkable. Detail flow achieved a 2.96 GFID score using only 128 tokens that surpassed was 3.3 and flexvar of 3.05, both used 680 tokens. Even more impressive, the retail flow-64 reached a GFID of 2.62 using 512 tokens. In terms of speed, it delivered almost twice as much inference speed for VAR and Flexvar. A further ablation study confirmed that self -correction training and semantic order of the token’s significantly improved output quality. For example, activation of self -correction GFID fell from 4.11 to 3.68 in a setting. These measurements demonstrate both higher quality and faster generation compared to established models.
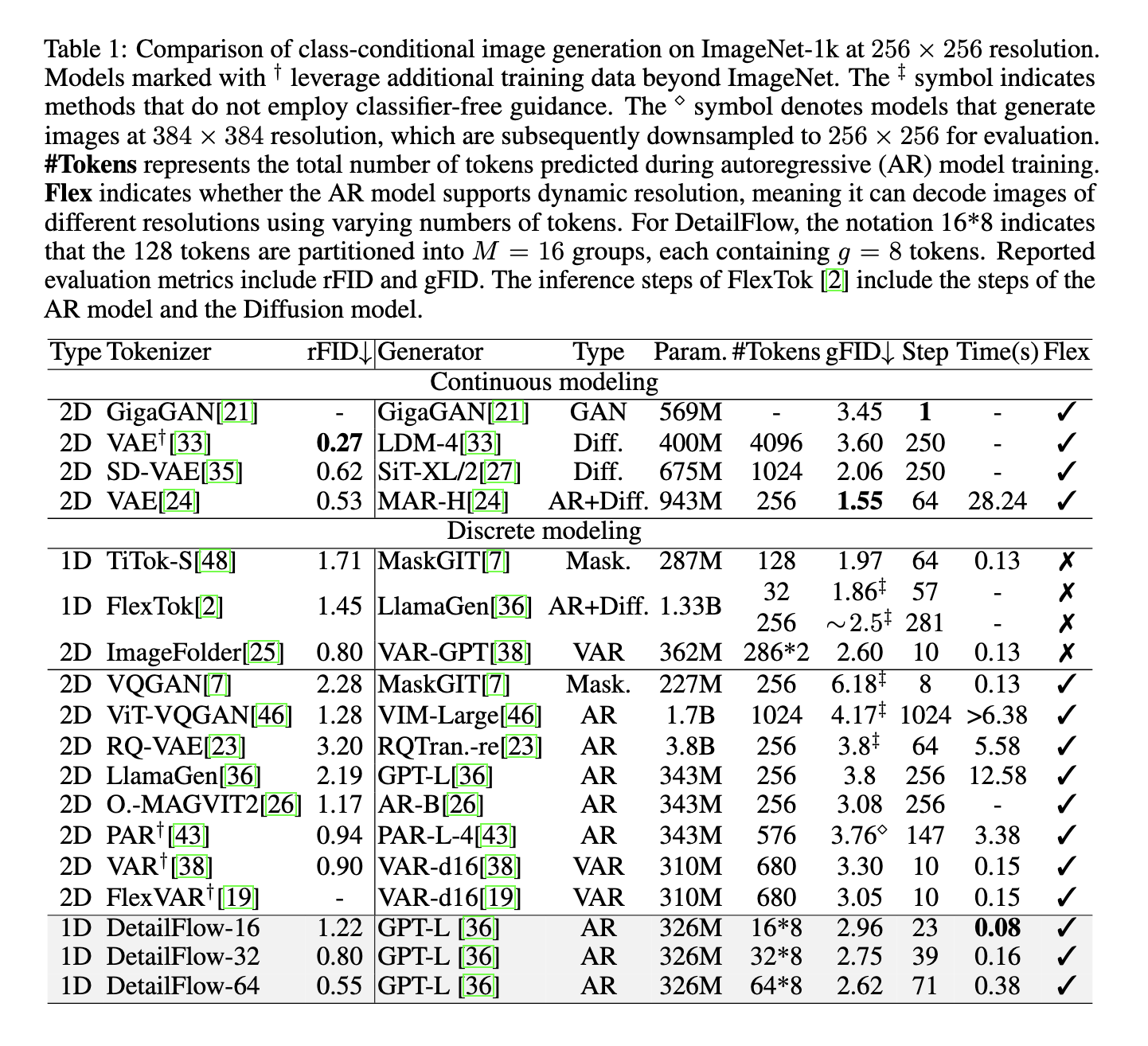
By focusing on semantic structure and reducing redundancy, retail flow presents a viable solution to long -term problems in authentic image generation. The gross of the method for fine approach, effective parallel decoding and the ability to self-correction to emphasize how architectural innovations can tackle performance and scalability restrictions. Through their structured use of 1D tookens, the researchers from Bytedance have demonstrated a model that maintains high image fidelity while reducing the calculation load, making it a valuable addition to image synthesis research.
Check the page paper and github. All credit for this research goes to the researchers in this project. You are also welcome to follow us on Twitter And don’t forget to join our 95k+ ml subbreddit and subscribe to Our newsletter.
Nikhil is an internal consultant at MarkTechpost. He is pursuing an integrated double degree in materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who always examines applications in fields such as biomaterials and biomedical science. With a strong background in material science, he explores new progress and creates opportunities to contribute.