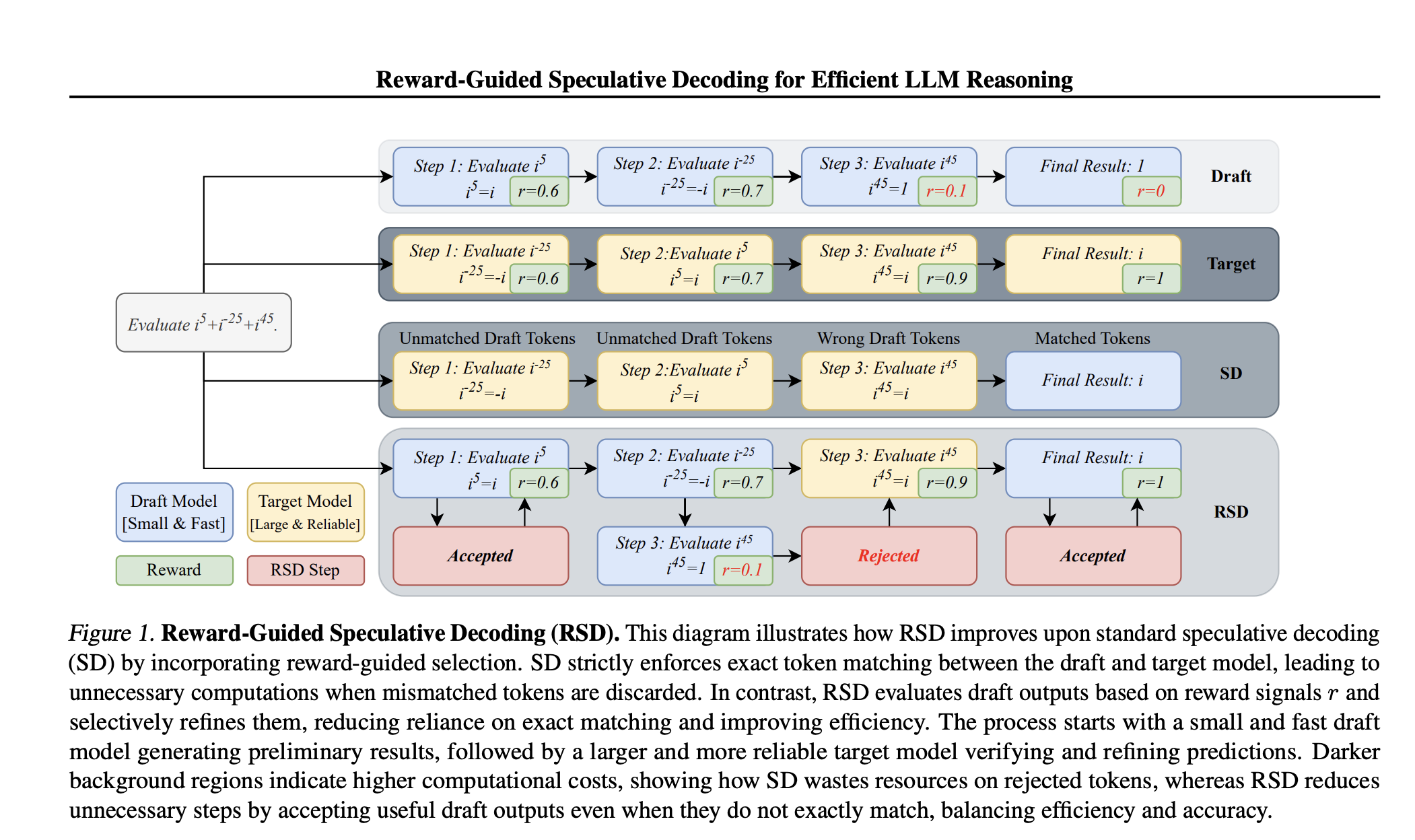
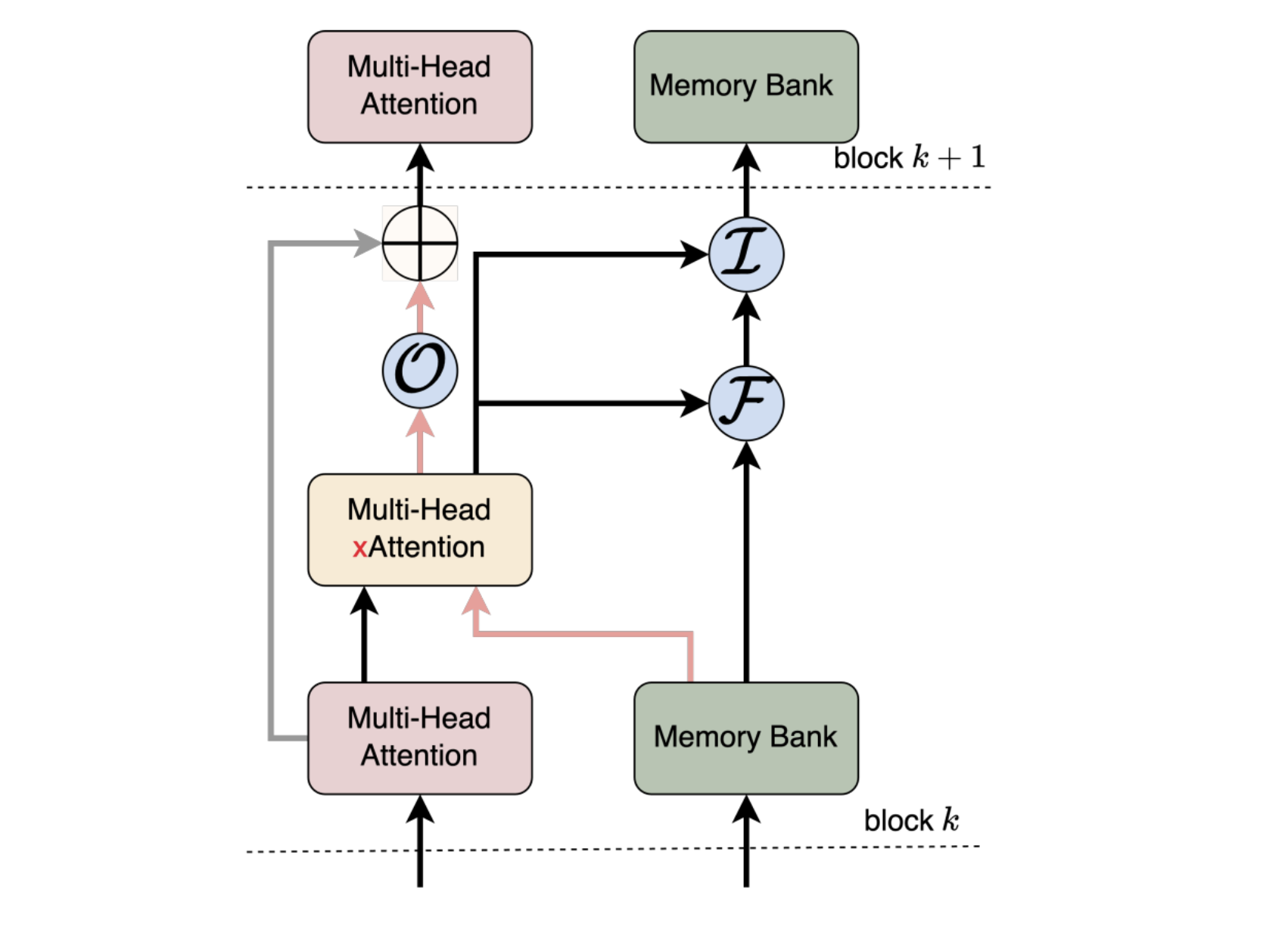
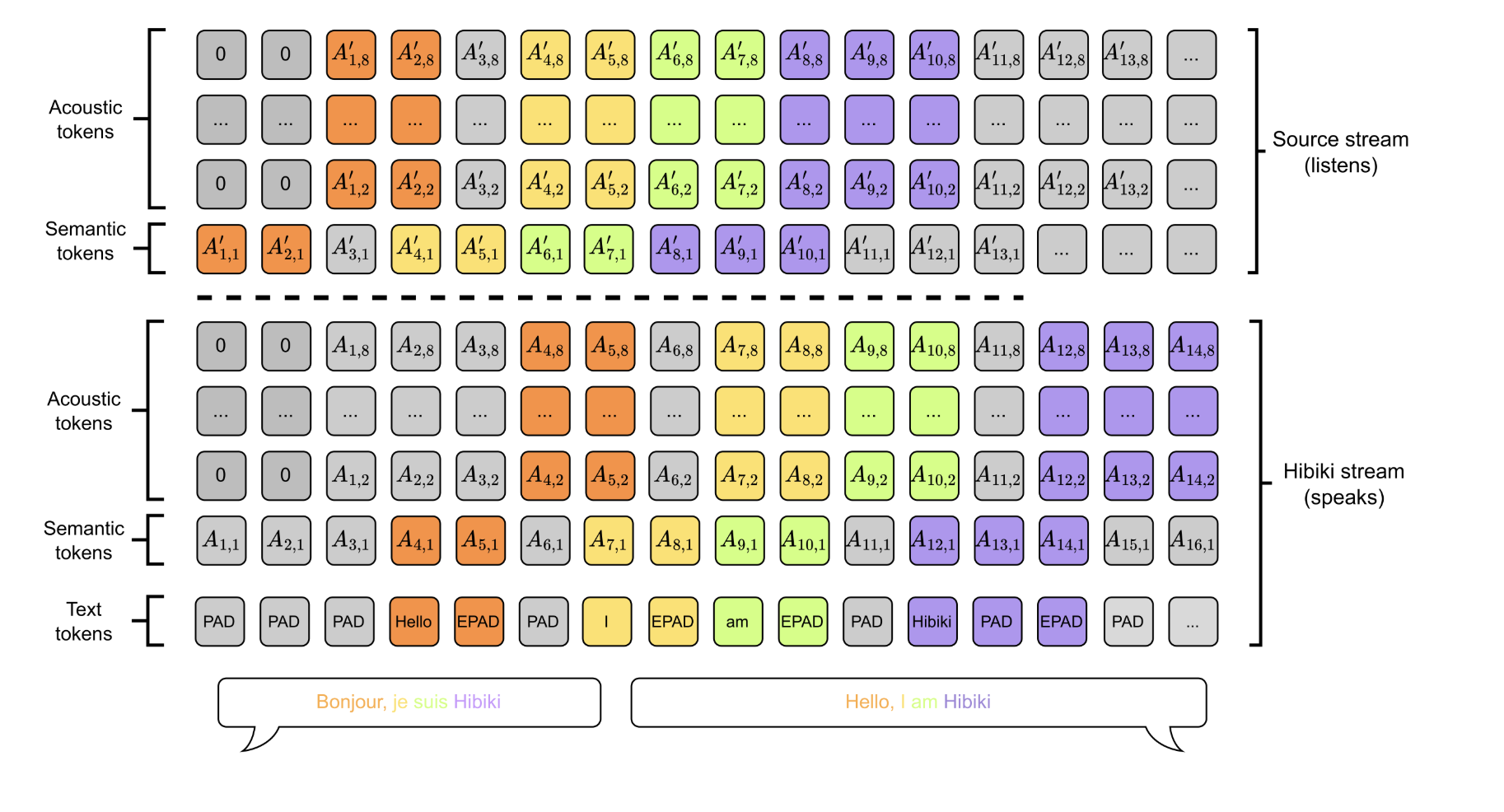
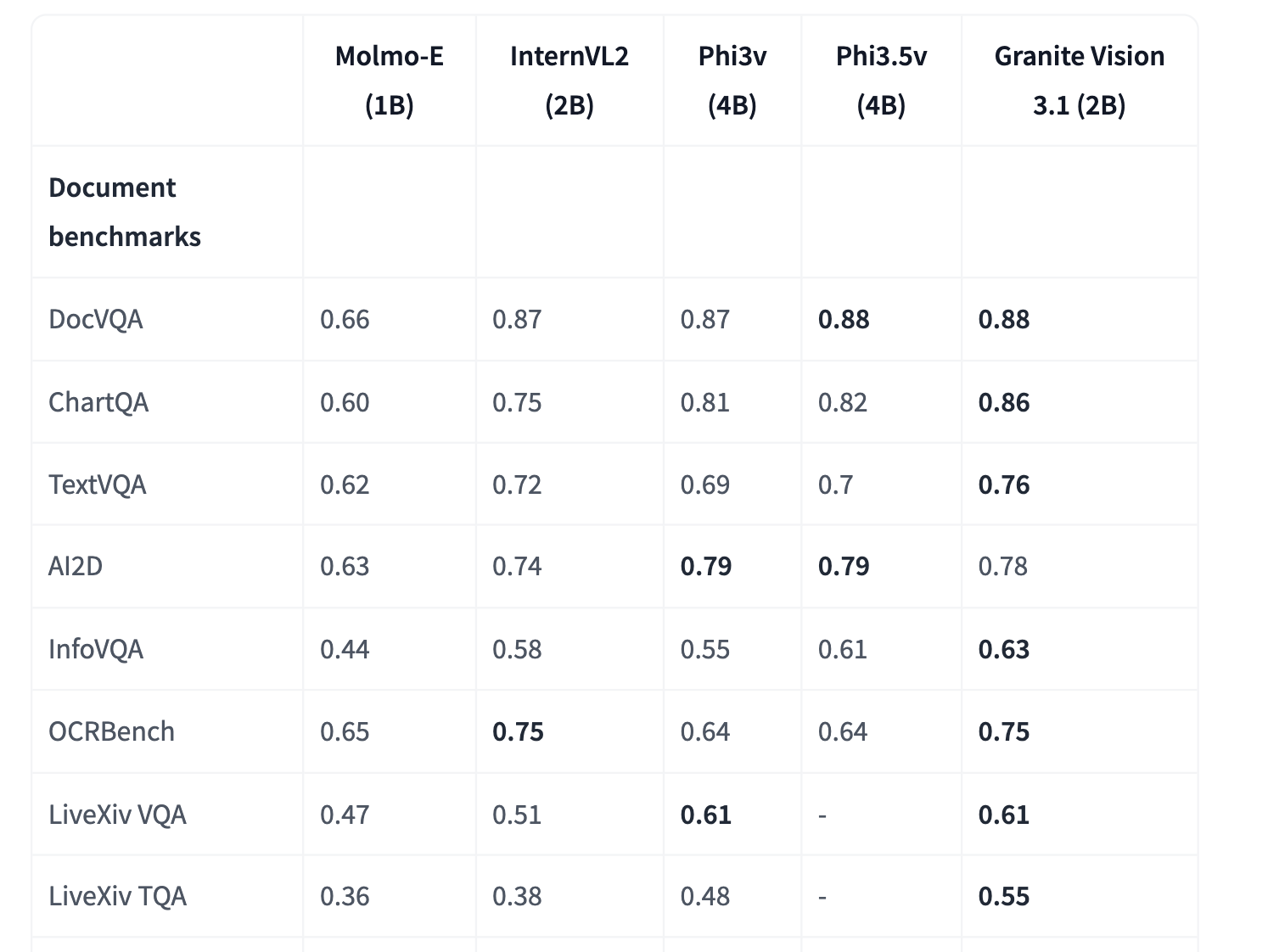
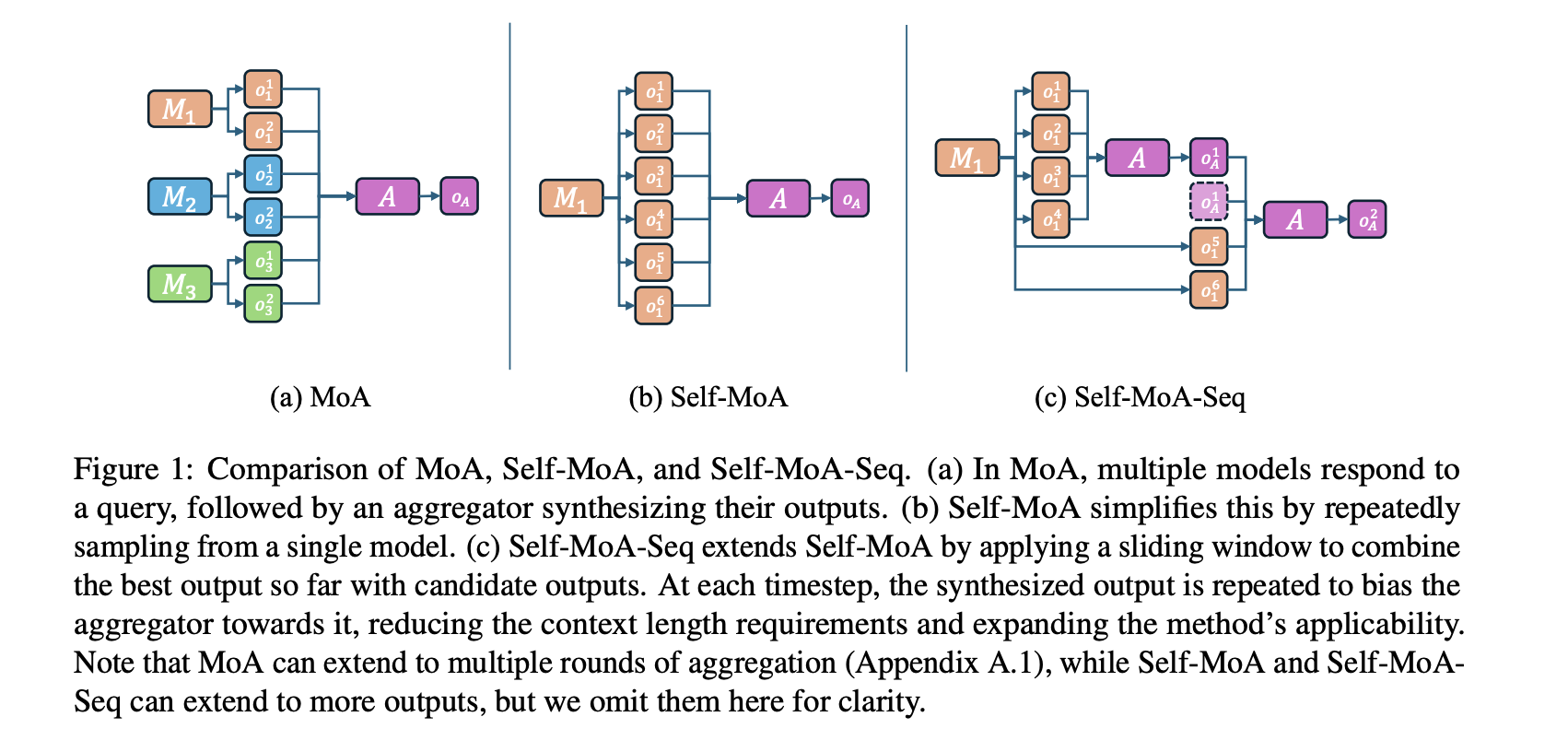
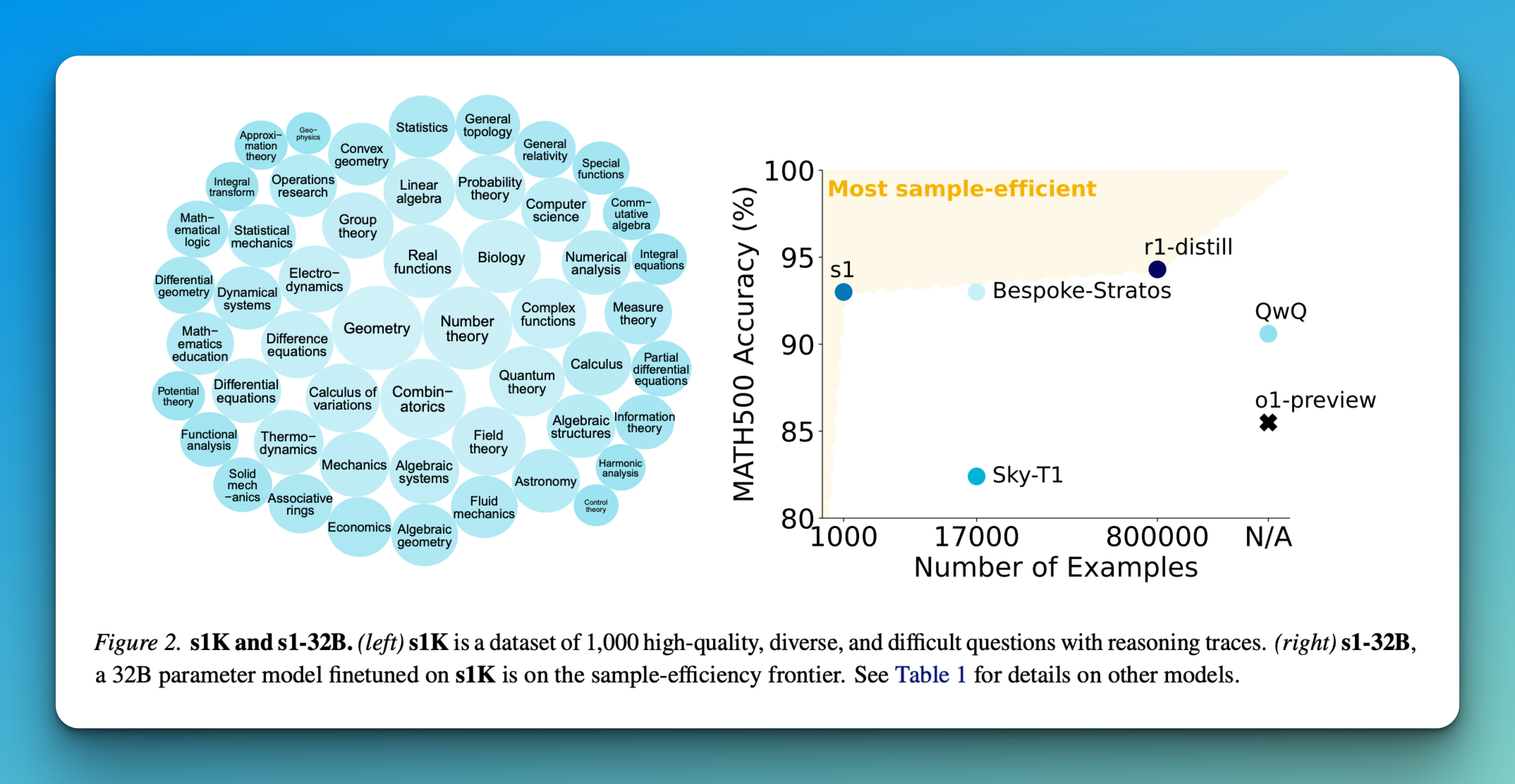
Google DeepMind scientists suggest matryoshka quantization: a technique to improve deep learning efficiency by optimizing multi-precision models without sacrificing accuracy
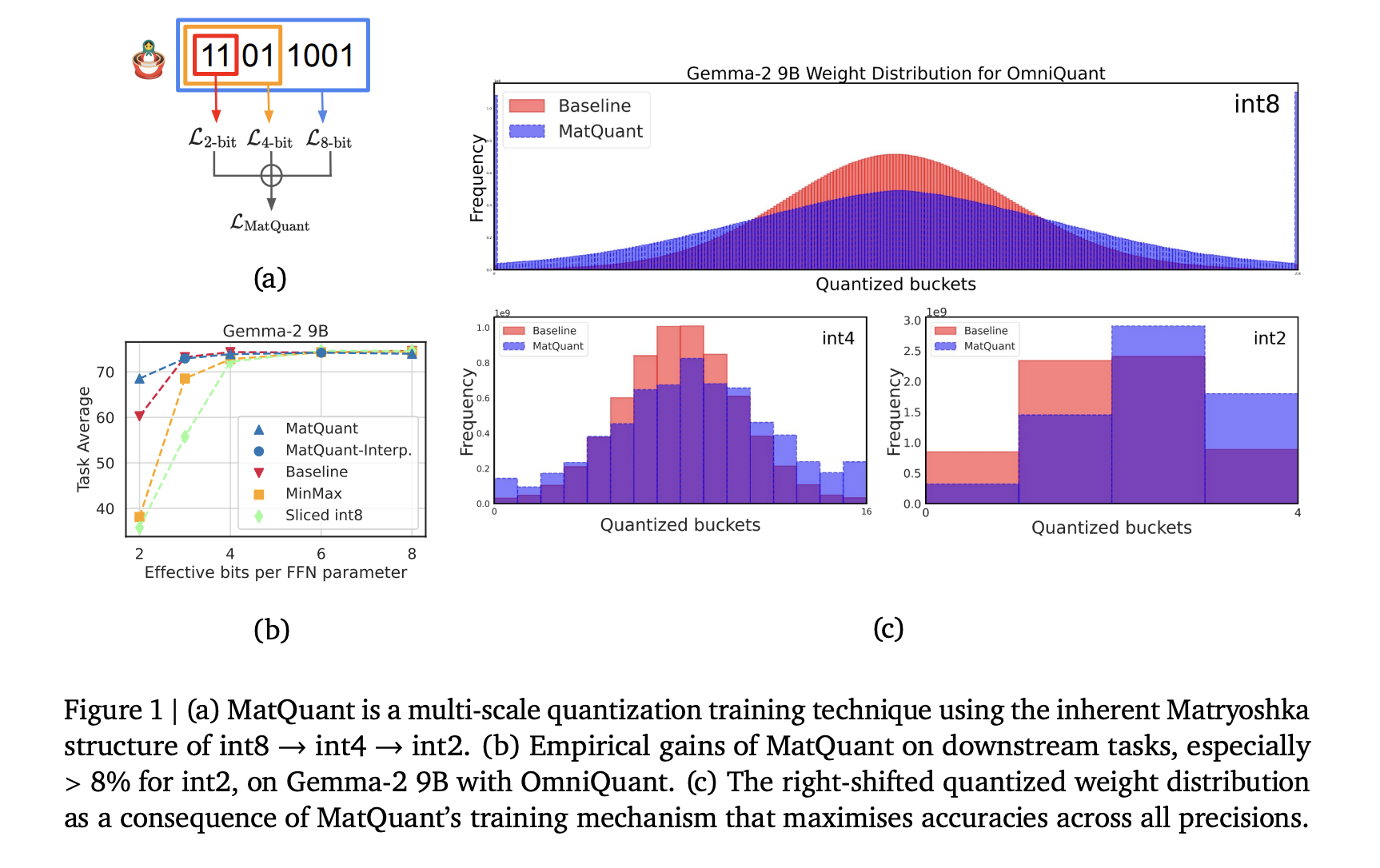
Quantization is a crucial technique for deep learning for reducing calculation costs and improving model efficiency. Large language models require significant treatment power, making quantization important to minimize memory consumption and improve the rate of inference. By converting high precision weights to lower bit formats, such as Int8, Int4 or InT2, quantization reduces storage requirements. … Read more