Transformer-based models have significantly advanced Natural Language Processing (NLP), which is distinguished in different tasks. However, they are struggling with reasoning for long contexts, multi-stage inference and numeric reasoning. These challenges arise from their square complexity in self -perception, making them ineffective for expanded sequences and their lack of explicit memory, limiting their ability to synthesize scattered information effectively. Existing solutions, such as recurring memory transformers (RMT) and fetch-augmented generation (RAG), partly provide improvements, but often sacrifice either efficiency or generalization.
Introduction of the large memory model (LM2)
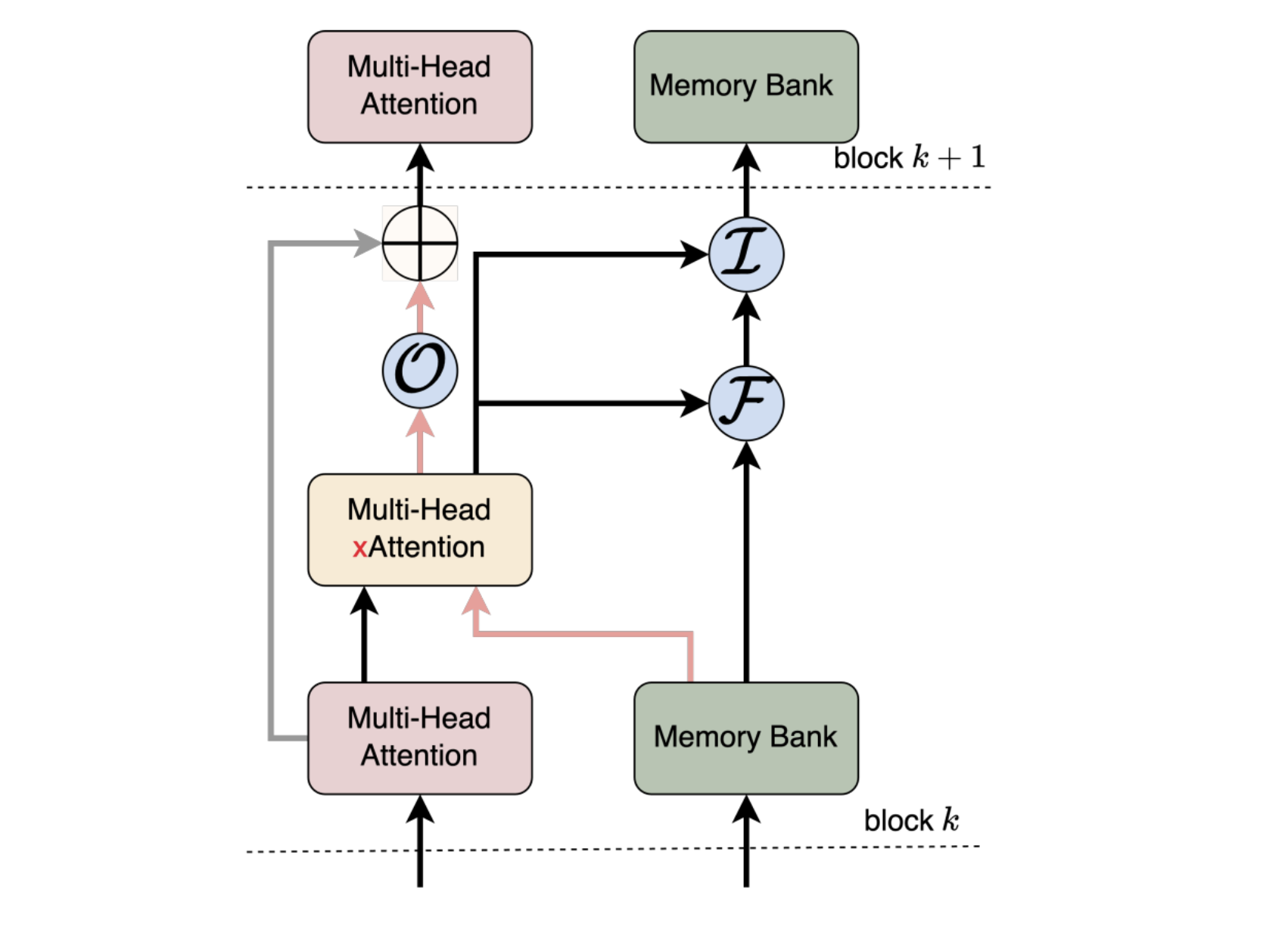
Convergence laboratories introduce the large memory model (LM2), a decoding-only transformer architecture improved with an auxiliary module to tackle the deficiencies of conventional models in long context resonance. Contrary to standard transformers that rely only on attention mechanisms, the LM2 incorporates a structured memory system that interacts with input enlivenings through transverse attention. The model’s memory updates are regulated by port mechanisms, allowing it to selectively maintain relevant information while retaining generalization functions. This design allows LM2 to maintain coherence across long sequences, which facilitates improved relational reasoning and inference.
Technical Overview and Benefits
LM2 is based on standard transformer architecture by introducing three key innovations:
- Memory Increased Transformer: A dedicated memory bank acts as an explicit long -term storage system that retrieves relevant information through transverse attention.
- Hybrid Memory Road: Unlike previous models that change the transformer’s core structure, LM2 maintains the original information stream while integrating a help memory path.
- Dynamic memory updates: The memory module selectively updates its stored information using tutable input, forget and output ports, ensuring prolonged detention without unnecessary accumulation of irrelevant data.
These improvements allow LM2 to treat long sequences more efficiently, while the calculation efficiency maintains calculation efficiency. Selectively to incorporate relevant memory content reduces the gradual performance decrease that is often observed in traditional architectures over expanded contexts.
Experimental results and insights
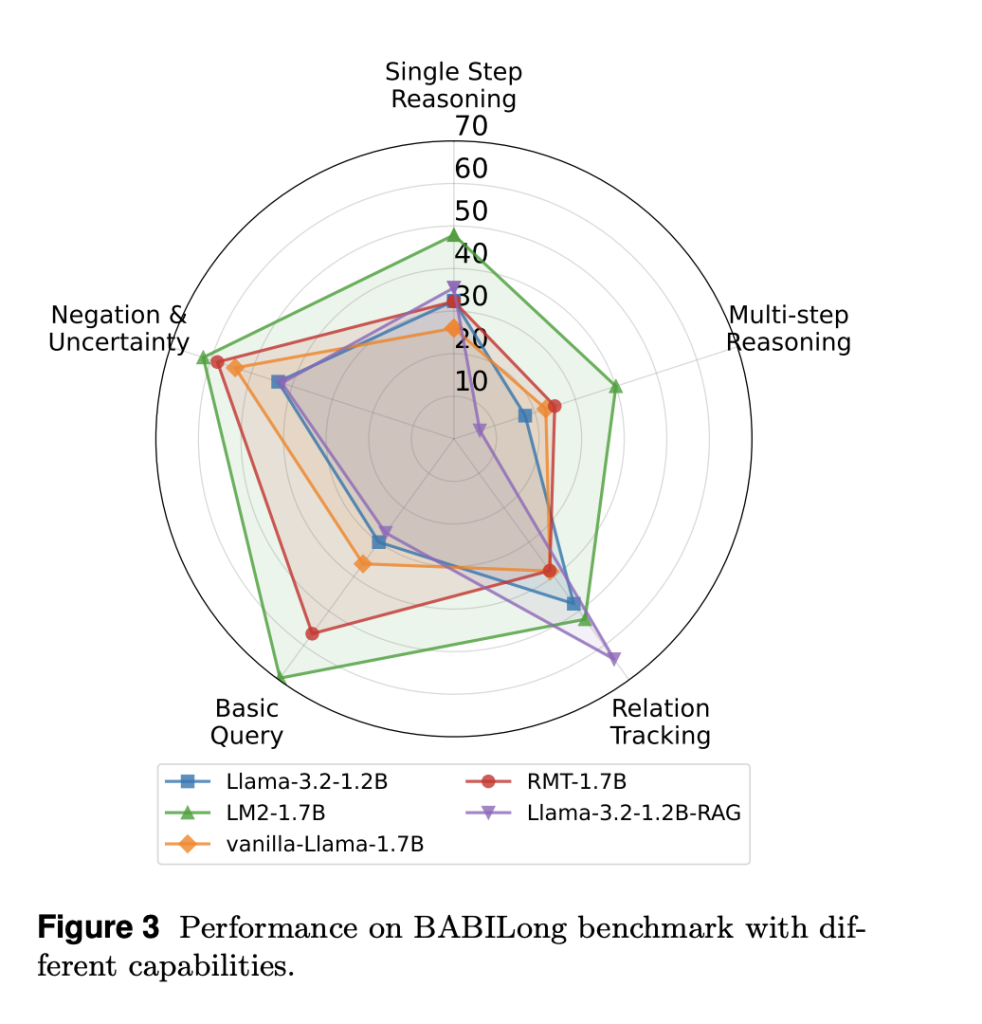
To evaluate LM2’s efficiency, it was tested on the Babilong data set, designed to assess memory-intensive reasoning features. The results indicate significant improvements:
- Card context performance (0K context length): LM2 achieves an accuracy of 92.5%surpass RMT (76.4%) and Vanilla Llama-3.2 (40.7%).
- Long context performance (1K-4K context length): As the context length increases, all models experience some degradation, but LM2 maintains a higher accuracy. On 4K context lengthLM2 achieves 55.9%Compared to 48.4% for RMT and 36.8% for Llama-3.2.
- Extremely long context performance (≥8k context length): While all models fall into accuracy, LM2 remains more stable and surpasses RMT in multi-step inference and relational argumentation.
In addition to memory-specific benchmarks, the LM2 was tested on the MMLU data set, covering a wide range of academic topics. The model demonstrated one 5.0% improvement over a pre -formed vanilla transformerEspecially excellent in the humanities and social sciences, where contextual reasoning is crucial. These results indicate that LM2’s memory module improves the reasoning features without compromising on the general task benefit.

Conclusion
The introduction of LM2 offers a thought-provoking approach to tackle the restrictions in standard transformers in long context-resonance. By integrating an explicit memory module, LM2 multi-step improves inference, relational argumentation and numeric reasoning while maintaining efficiency and adaptability. Experimental results show its benefits over existing architectures, especially in tasks that require expanded context storage. Furthermore, LM2 works well in general justification of benchmarks, which suggests that memory integration does not hinder versatility. As memory-added models continue to develop, LM2 represents a step towards more effective long context-resonance in language models.
Check out the paper. All credit for this research goes to the researchers in this project. You are also welcome to follow us on Twitter And don’t forget to join our 75k+ ml subbreddit.
🚨 Recommended Open Source AI platform: ‘Intellagent is an open source multi-agent framework for evaluation of complex conversation-a-system‘ (Promoted)
Asif Razzaq is CEO of Marketchpost Media Inc. His latest endeavor is the launch of an artificial intelligence media platform, market post that stands out for its in -depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts over 2 million monthly views and illustrates its popularity among the audience.
✅ [Recommended] Join our Telegram -Canal