LLMs quickly go across multiple domains, but their effectiveness in tackling complex financial problems is still an area of active study. The iterative development of LLMs has significantly driven the development of artificial intelligence to artificial general intelligence (AGI). Openai’s O1 series and similar models such as QWQ and Marco-O1 have improved complex reasoning features by expanding “chain-of-tank” reasoning through an iterative “Investment Reflection” approach. In financing, models such as Xuanyuan-Finx1 front and Fino1 have shown the potential for LLMs in cognitive reasoning tasks. Meanwhile, Deepseekr1 adopts another strategy that depends solely on RL with multi -stage training to improve reasoning and infernity skills. By combining thousands of unattended RL training steps with a small cold start data set, Deepsekr1 demonstrates strong new reasoning performance and readability, highlighting the effectiveness of RL-based methods for improving large language models.
Despite these progress, general LLMs are struggling to adapt to specialized financial reasoning tasks. Financial decision-making requires interdisciplinary knowledge, including legal rules, financial indicators and mathematical modeling, while requiring logical, step-by-step reason. More challenges arise when implementing LLMs in financial applications. First, fragmented financial data complicates knowledge integration, leading to discrepancies that hinder extensive understanding. Secondly, the LLM’s black-box makes LLMS make their reasoning difficult to interpret, in conflict with regulatory requirements for transparency and accountability. Finally, LLMs often struggle with generalization across economic scenarios and produce unreliable output in high -risk applications. These restrictions constitute significant barriers to their adoption in the real world’s financial systems, where accuracy and traceability are critical.
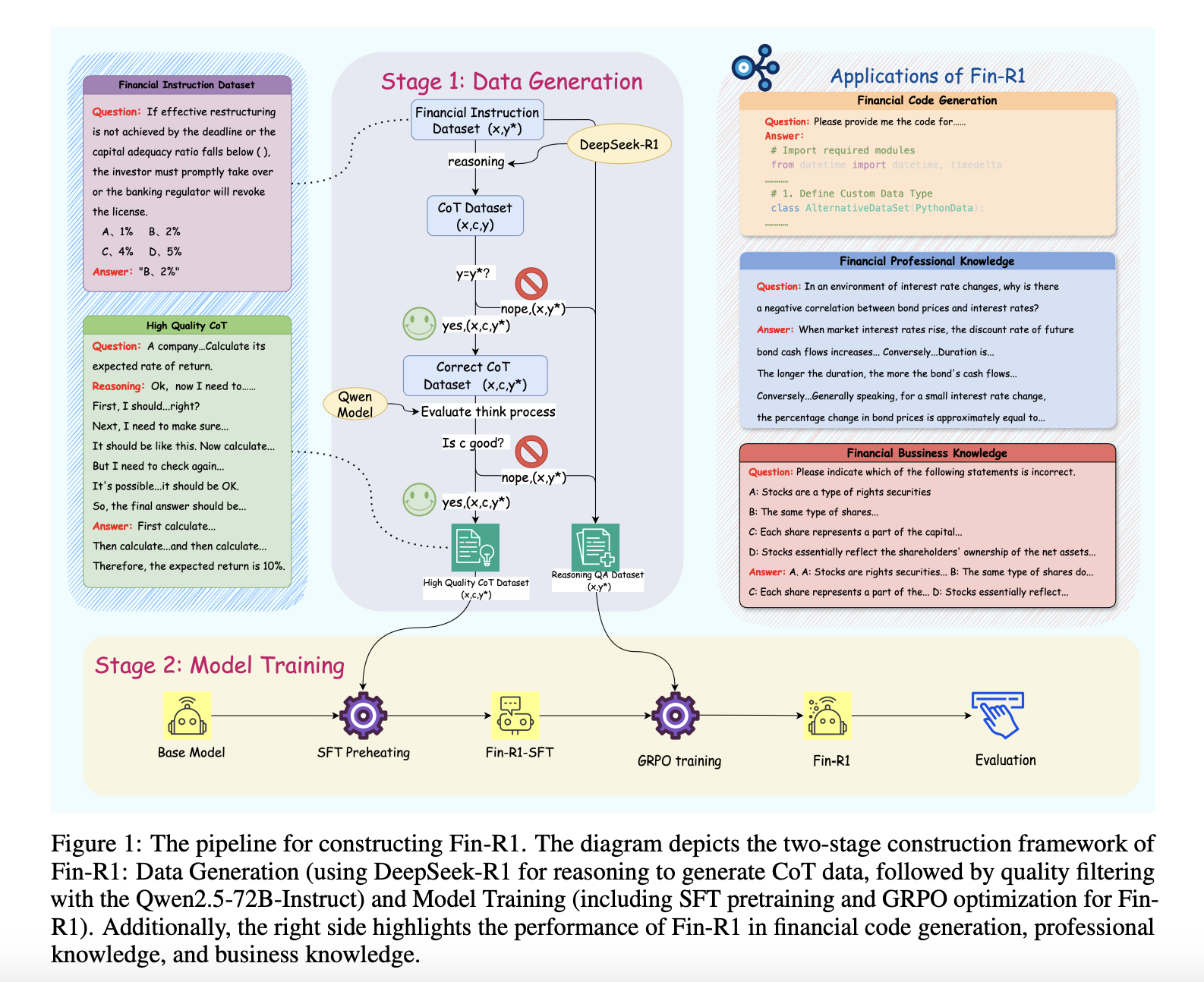
Researchers from Shanghai University of Finance & Economics, Fudan University and Finstep have developed Fin-R1, a specialized LLM for financial reasoning. With a compact architecture of 7 billion parameters, FIN-R1 reduces implementation costs, while addressing important financial challenges: fragmented data, non-reasoning control and weak generalization. It is trained on fine-R1 data, a high-quality data set containing 60,091 COT that is taken from authoritative financial data. A two-stage training method-monitored fine-tuning (SFT) followed by RL-FIN-R1 improves accuracy and interpretability. It works well in financial benchmarks, which stand out in financial compliance and robo-advisory applications.
The study presents a two-stage frame for the construction of FIN-R1. The data rating phase involves creating a financial reasoning data set, fine-R1 data, through data still with Deepseek-R1 and filtration using an LLM-AS-judge approach. In the model training phase, Fin-R1 is fine-R1 on QWEN2.5-7B instructions using SFT and group Relative political optimization (GRPO) to improve reasoning and output consistency. The data set combines open source and proprietary financial data, refined through strict filtration. Education integrates monitored learning and reinforcement learning, incorporation of structured prompt and reward mechanisms to improve financial reasoning accuracy and standardization.
FIN-R1’s reasons for financial scenarios were evaluated through a comparative analysis against several advanced models, including Deepseek-R1, Fin-R1-SFT and various Qwen and Llama-based architectures. Despite its compact 7B parameter size, Fin-R1 achieved a remarkable average score of 75.2 that ranked second overall. It surpassed all models on a similar scale and exceeded Deepseek-R1-Distill-Llama-70b by 8.7 points. FIN-R1 ranked highest in Finqa and Convfinqa with scores of 76.0 and 85.0 respectively, demonstrating strong economic reasoning and cross-cutting task generalization, especially in benchmarks such as ant_finance, TFNs and financing instructions-500K.
Finally, Fin-R1 is a large economic reasoning language model designed to tackle the most important challenges in financially AI, including fragmented data, inconsistent reasoning logic and limited business generalization. It delivers advanced performance by using a two-step workout process flock and RL-on high quality fine-R1 data set. With a compact 7B parameter scale, it achieves scores of 85.0 in Convfinqa and 76.0 in Finqa that surpass larger models. Future Work aims to improve economic multimodal capabilities, strengthen regulatory compliance and expand applications in the real world, drive innovation in fintech and at the same time ensure effective and intelligent financial decision -making.
Check out The paper and the model on embraced face. All credit for this research goes to the researchers in this project. You are also welcome to follow us on Twitter And don’t forget to join our 85k+ ml subbreddit.
Sana Hassan, a consultant intern at MarkTechpost and dual-degree students at IIT Madras, is passionate about using technology and AI to tackle challenges in the real world. With a great interest in solving practical problems, he brings a new perspective to the intersection of AI and real solutions.