
AutoCoders and the latent space
Neural networks are designed to learn compressed representations of high -dimensional data, and autoCodere (AEs) is a widely used example of such models. These systems use a coder cod structure for project data for a low dimensional latent space and then reconstruct it back to its original form. In this latent space, patterns and functions of the input data become more interpretable, allowing for performance of different downstream tasks. AutoCoders have been extensive used in domains such as image classification, generative modeling and anomaly detection thanks to their ability to represent complex distributions through more manageable, structured representations.
Memorization vs. Generalization in neural models
A sustained problem with neural models, especially auto -coders, is to determine how they create a balance between remembering training data and generalizing to unseen examples. This balance is critical: If a model overfits, it may not be able to perform on new data; If it generalizes too much, it may lose useful details. Researchers are particularly interested in whether these models encoding knowledge in a way that can be revealed and measured, even in the absence of direct input data. Understanding this balance can help optimize model design and training strategies and provide insight into what neural models retain the data they process.
Existing probing methods and their limitations
Current techniques to examine this behavior often analyze performance metrics, such as reconstruction defects, but these only scratch the surface. Other approaches use changes to the model or input to gain insight into internal mechanisms. However, they usually do not reveal how model structure and exercise dynamics affect learning results. The need for a deeper representation has driven research into more inherent and interpretable methods of studying model behavior that goes beyond conventional measurements or architectural adjustments.
The latent vector field perspective: dynamic systems in latent space
Researchers from IST Austria and Sapienza University introduced a new way of interpreting autoCodere as dynamic systems operating in latent space. By repeatedly using the coding-decoding function at a latent point, they construct a latent vector field that reveals attractors-stable points in latent space where data presentations settle. This field is found in the nature of the case in any autoCoder and does not require changes in the model or additional training. Their method helps visualize how data moves through the model and how these movements relate to generalization and memory. They tested this across data sets and even foundation models that expanded their insights over synthetic benchmarks.
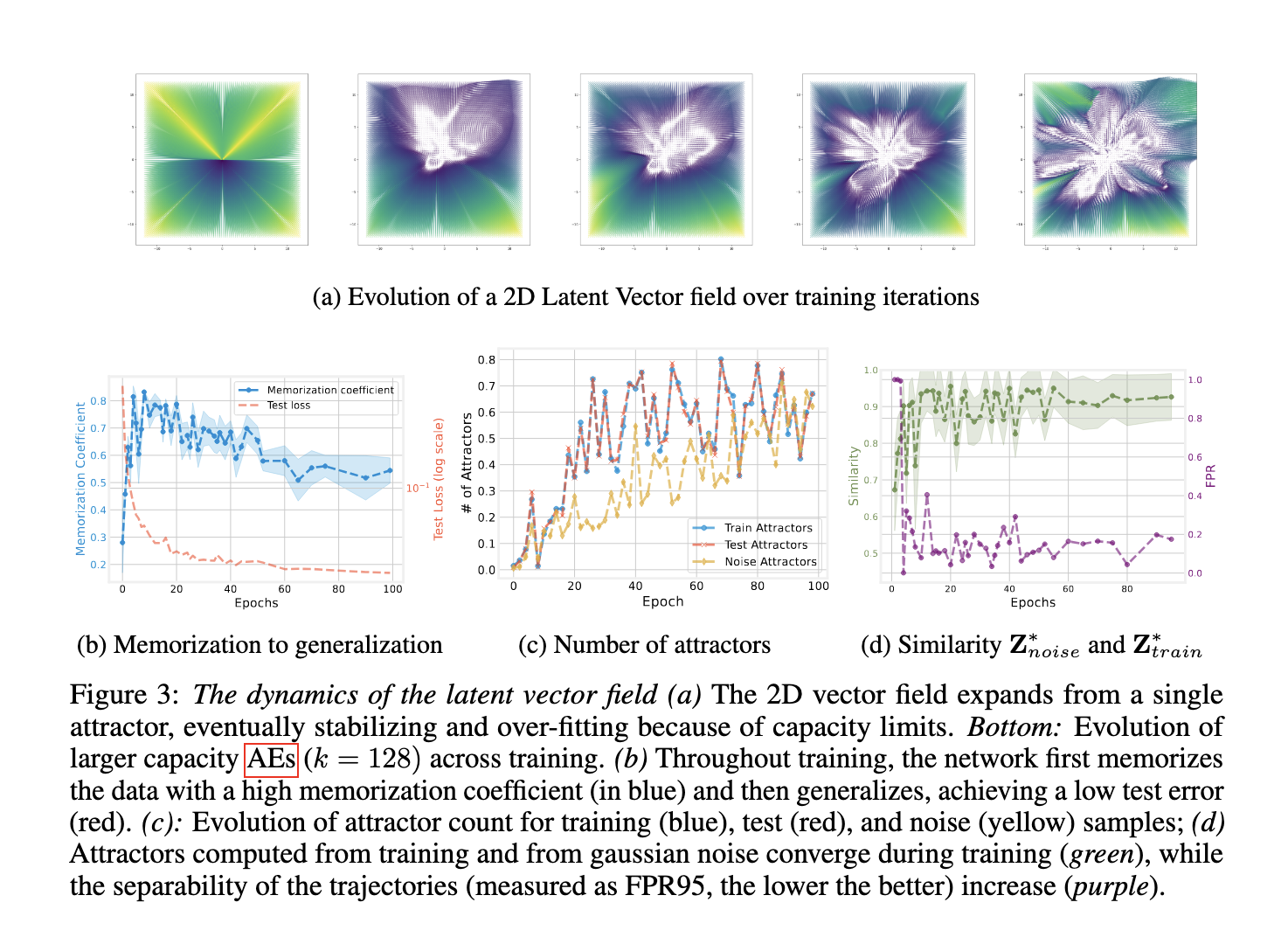
Iterative mapping and the role of contraction
The procedure involves the treatment of the repeated use of the mapping of codes codes as a discreet differential equation. In this formulation, every point is mapped in latent space iterative, forming a course defined by the remaining vector between each iteration and its input. If the mapping is contractual – which means each application shrinks the room – the system is stabilized to a fixed point or attract. The researchers demonstrated that ordinary design choices, such as weightfall, small bottleneck dimensions and augmentation-based training, of course promote this contraction. The latent vector field thus acts as an implicit summary of the training dynamics, which reveals how and where models learn to code data.
Empirical results: attractors codes for model behavior
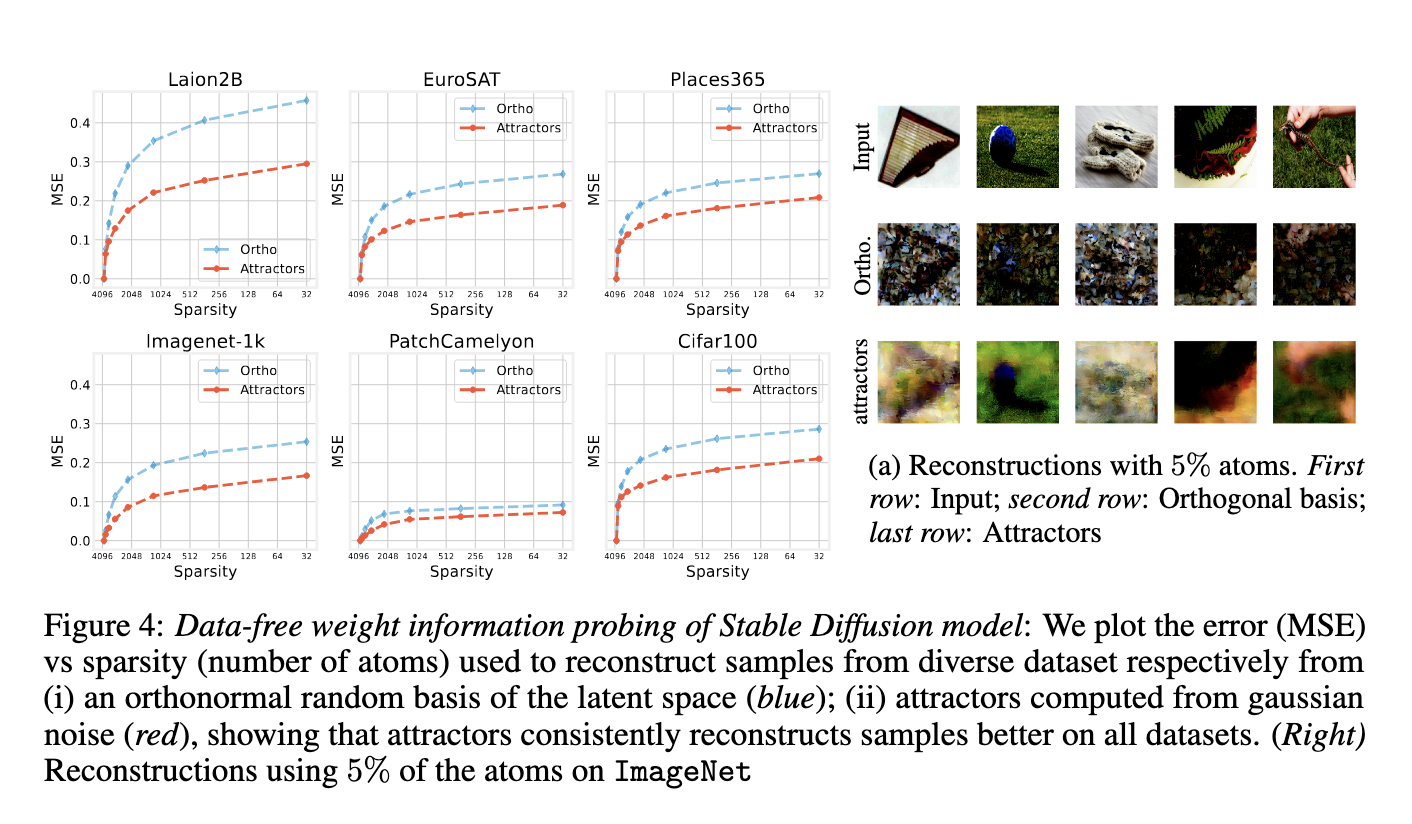
PERFORMANCE -TESTS demonstrated that these attractors codes for key properties in the behavior of the model. When training fluctuations on Mnist, Cifar10 and Fashionmnist, it was found that lower bottleneck dimensions (2 to 16) led to high memory coefficients over 0.8, whereas higher dimensions supported generalization by lowering test errors. The number of attractors increased by the number of exercise pools, starting from one and stabilization after training progressed. When exploring a Vision Foundation model, preceded by Laion2b, the researchers reconstructed data from six different data sets using attractors derived from Gaussian noise. At 5% sparsity, reconstructions were significantly better than those from a random orthogonal basis. The average square error was consistently lower, demonstrating that attractors form a compact and effective dictionary with representations.
Meaning: Promoting Model Comparability
This work highlights a new and powerful method of inspecting how neural models store and use information. The researchers from IST Austria and Sapienza revealed that attractors in latent vector fields provide a clear window to a model’s ability to generalize or remember. Their findings show that even without input data, latent dynamics can reveal the structure and limitations of complex models. This tool could significantly help the development of more interpretable, robust AI systems by revealing what these models are learning and how they behave during and after training.
Check Paper. All credit for this research goes to the researchers in this project. You are also welcome to follow us on Twitter And don’t forget to join our 100k+ ml subbreddit and subscribe to Our newsletter.
Nikhil is an internal consultant at MarkTechpost. He is pursuing an integrated double degree in materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who always examines applications in fields such as biomaterials and biomedical science. With a strong background in material science, he explores new progress and creates opportunities to contribute.
