Large language models (LLMS) have been given prominent role in their ability to handle complex reasoning tasks, transformer applications from chatbots to code generation tools. These models are known to take advantage of scaling their calculation during inference, which often produces higher accuracy by dedicating more resources to harsh problems. However, this approach brings significant disadvantages. Longer treatment times and higher computer costs make it challenging to scale such solutions in the real world environment where responsiveness and affordable prices are crucial. As the technology progresses towards more intelligent systems, there is a growing need to explore how LLMs can not only become smarter but also more effective, especially when working in repeated or well -known contexts.
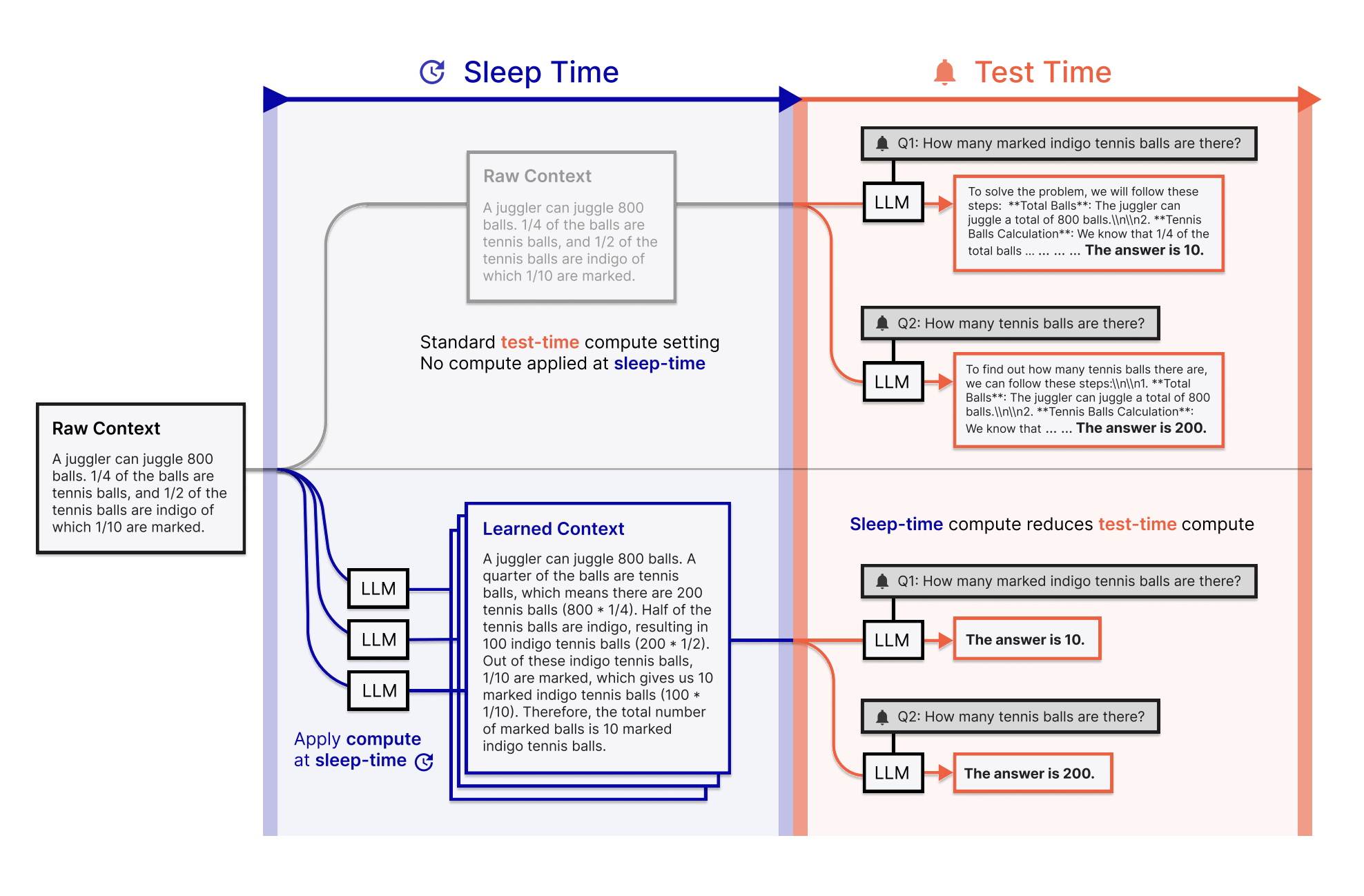
One of the largest inefficiencies of the current LLM implementation occurs during query resolution. When a user asks a question, the model typically addresses it at the same time as the necessary background context. This test-time calculation assumes that the context and the question always arrive together. But in real scenarios, such as document Q&A or Troubleshooting Code, context is usually sustained and can be accessed well before a specific question is asked. Still, the model treats everything from scratch for each inquiry, even if it has seen the context before. This redundancy results in increased calculation costs and response delays, especially in scenarios involving multiple queries within a single context.
To deal with this inefficiency, different methods have been developed. Sequential and parallel test time calculation are two main strategies. Sequential approaches expand the model’s reasoning path so that it can consider more options, while parallel approaches involve sampling more output simultaneously, known as pass@K. Techniques such as speculative decoding aim to cut delay by making early guesses, but their utility is limited when the model still has to think from scratch. Although useful, these methods do not eliminate the need to deal with context with each new question repeatedly. They also typically require test time conditions that are not always possible, such as access to an oracle or ideal verifier.
Researchers from LETTA and the University of California, Berkeley, introduced a new solution they call sleep-time calculation. The method involves the use of idle time between user interactions to increase productivity. Instead of waiting for a user question, the model begins to analyze the context in advance. It expects possible future queries and builds a new version of the context enriched with relevant conclusions. When a user finally asks a question, the model can simply refer to this pre -treated context. Since much of the mindset is already done, it requires less calculation effort to produce accurate answers. This approach becomes even more effective when more questions relate to the same context, enabling shared conclusions and distributed calculation costs.
The implementation of Sleep-Time Compute is dependent on breaking down the traditional prompt into two parts: a static context and a dynamic inquiry. During the sleep time window, only the context is used to generate a pre-treated version. This improved context, called C ′, is built using Test Time Compute Techniques such as reasoning chains or summary. When this enriched version is stored, it replaces the raw context under real -time questions. The last answers are then generated using much fewer resources. This system not only minimizes superfluous reasoning, but also paves the way for more proactive LLMs that can think ahead and be better prepared.
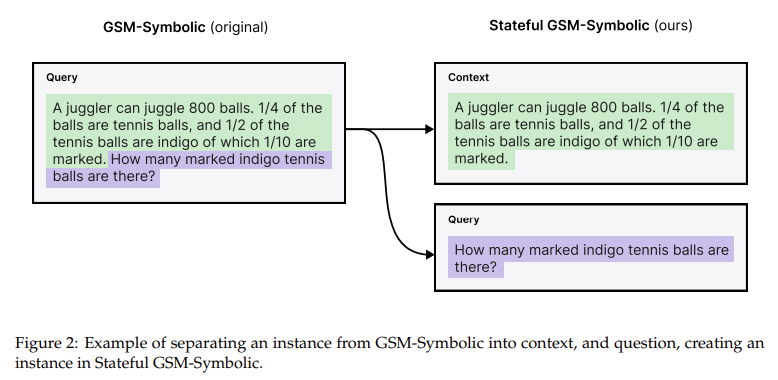
To evaluate the effectiveness of sleep-time calculation, the research team tested it using two specially designed benchmarks: Stateful GSM symbolic and state AIME. Both data sets are derived from the division of existing problem sets into separate contexts and questions. In experiments that used models such as GPT-4O and GPT-4o-mini, researchers observed a 5 × reduction in test time computing for similar accuracy levels. In particular, the accuracy improved by up to 13% for GSM symbolic P2 datasets and with 18% on Stateful AIME when sleep time calculated was scaled. Multi-Query GSM symbol, a new data set introduced to this evaluation, helped demonstrate that costs per Inquiry could be reduced by 2.5 × when 10 queries shared the same context.
When they were pitted against popular strategies such as Pass@K, Compute with sleep time consistently surpassed them. Unlike Pass@K, which assumes access to a perfect evaluator, Sleep-Time Compute works under more realistic conditions. The results show that even at low test time computer budgets produced sleep time calculation comparable or better accuracy while consuming fewer symbols. E.g. The GPT-4o-mini model achieved higher accuracy with fewer than 200 test time roofs using sleep-time calculation compared to over 500 tokens needed in baseline. Even when models such as Claude Sonnet 3.7 and Deepseek R1 were evaluated, similar improvements were observed.
Scaling of the amount of calculated dedicated to sleep time improved the results further. By running five parallel generations in sleep time on complex tasks, scientists pushed the pareto curve further. However, they noticed diminishing returns beyond this point. It is important that the results showed that stronger models that handled more difficult tasks benefited more of further sleep time. Amortization of sleep time calculation also became very cost -effective when contexts earned several related queries. When weighting the test time tokens as ten times more expensive than the sleep time tokens, which is adapted to the industry’s latency-time cost conditions, the researchers confirmed a reduction of up to 2.5 times in the average costs per year. Query.
Another interesting finding was that the calculation of sleep time worked best when user queries were predictable. Using Llama2-70b, researchers scored the predictability of each inquiry considering its context and found a strong correlation: the more predictable the query, the greater the advantage. In examples where the question logically followed from the given context, sleep time gave higher gains. Conversely, less predictable or abstract queries experienced reduced efficiency, though they still showed benefits compared to traditional test time methods.
In all, this research presents a smart and scalable technique to improve the effectiveness of LLMs without compromising accuracy. By utilizing otherwise inactive time, sleep-time calculation reduces the burden of real-time systems, lowers operating costs and improves response time. The clear quantitative improvements, such as a 5 × reduction in calculation, 13-18% accuracy gains and a drop up to 2.5 × in costs per Inquiry shows that forward -thinking approaches like this could shape the next generation of intelligent, context -conscious assistants.
Several important takeaways from the research are as follows:
- Sleep time calculation allows models to anticipate questions by resonating on context before the query arrives.
- Accuracy improved by 13% on GSM symbolic and 18% on AIME data sets when calculation of sleep time was scaled.
- Test-time calculation requirements fell by about 5 times for similar benefit levels.
- When sharing context across 10 related queries, the average query costs fell by a factor of 2.5.
- Compiled Pass@K strategy in parallel calculated settings on equivalent budgets.
- More effective on predictable queries identified via log-probe scoring.
- Dispination of returns noted beyond five parallel generations for calculating sleep time.
Check Paper. Nor do not forget to follow us on Twitter and join in our Telegram Channel and LinkedIn GrOUP. Don’t forget to take part in our 90k+ ml subbreddit.
🔥 [Register Now] Minicon Virtual Conference On Agentic AI: Free Registration + Certificate for Participation + 4 Hours Short Event (21 May, 9- 13.00 pst) + Hands on Workshop
Nikhil is an internal consultant at MarkTechpost. He is pursuing an integrated double degree in materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who always examines applications in fields such as biomaterials and biomedical science. With a strong background in material science, he explores new progress and creates opportunities to contribute.
