Software maintenance is an integral part of the software development life cycle, where developers often visit existing code bases to resolve errors, implement new features and optimize the performance. A critical task in this phase is code localization that clarifies specific locations in a code base that needs to be changed. This process has been important with modern software projects’ increasing scale and complexity. The growing dependence on automation and AI-powered tools has led to integrating large language models (LLMs) into supporting tasks such as bug detection, code search and suggestions. However, despite the promotion of LLMs in language tasks, it is a technical challenge that researchers strive to overcome these models to understand the semantics and structures of complex code bases.
When we talk about the problems, one of the most persistent problems in software maintenance is accurately identifying the relevant parts of a code base that needs changes based on user -reported problems or functional requests. Often, edition descriptions in natural language mention symptoms, but not the actual root cause of code. This interruption makes it difficult for developers and automated tools to associate descriptions with the exact code elements that need updates. Furthermore, traditional methods of complex code addictions are struggling, especially when the relevant code spans multiple files or requires hierarchical reasoning. Poor code localization contributes to ineffective bug solution, incomplete patches and longer development cycles.
Previous methods of code location mostly depend on close retrieval models or agent -based approaches. Close retrieval requires embedding the entire code base in a searchable vector space, which is difficult to maintain and update to large depots. These systems often work poorly when publishing descriptions lack direct references to relevant code. On the other hand, some recent approaches use agent -based models that simulate a human -like exploration of the code base. However, they often depend on catalog through review and lack an understanding of deeper semantic links such as inheritance or functional call. This limits their ability to deal with complex relationships between code elements that are not explicitly attached.
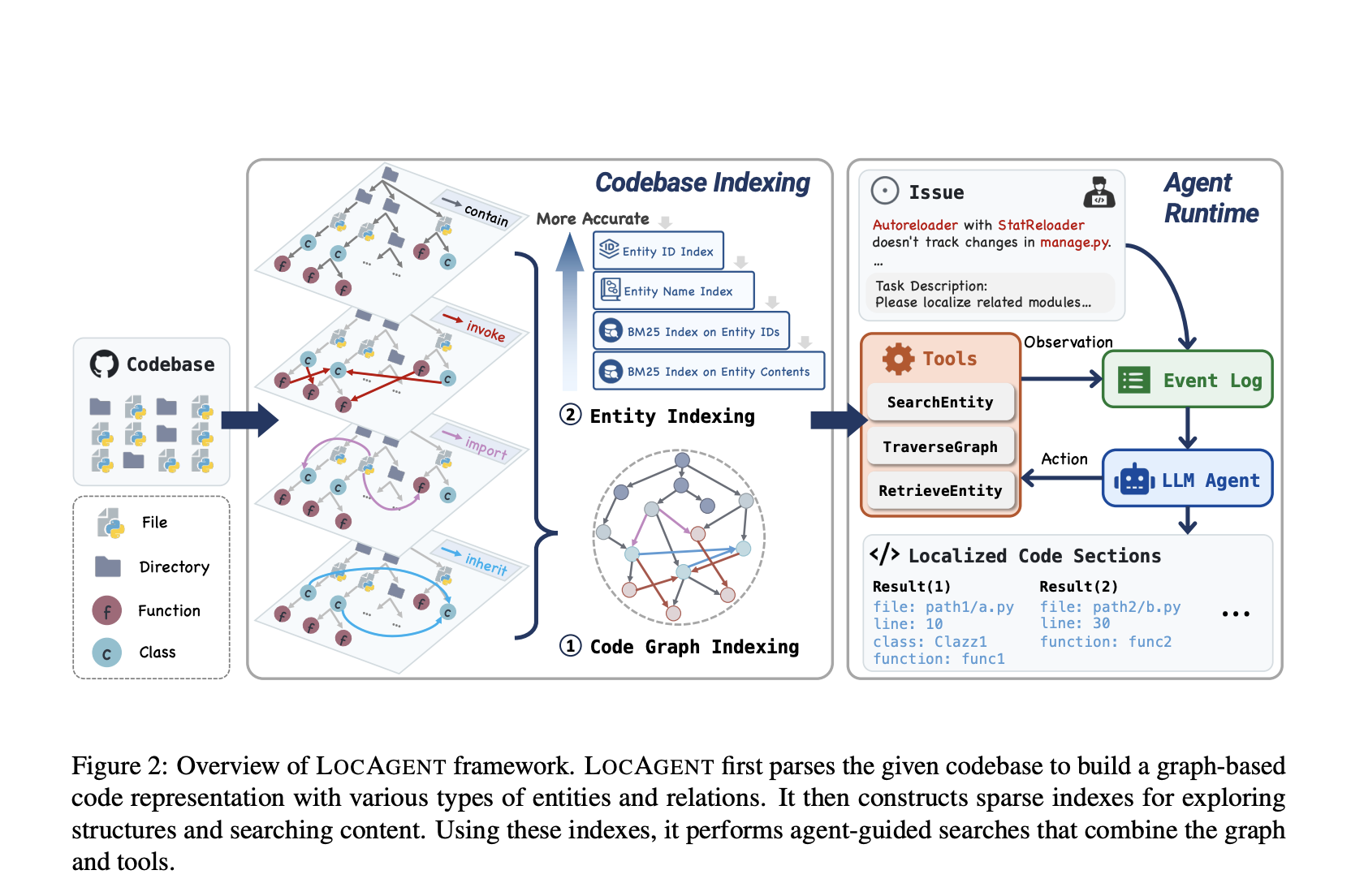
A team of researchers from Yale University, the University of Southern California, Stanford University, and all hands AI developed the local agent, a graphed agent frame to transform code location. Instead of depending on lexical matching or static embedders, the location converts entire code bases to corrected heterogeneous graphs. These graphs include nodes for folders, files, classes and features and edges to capture relationships such as functional calls, filimport and class heritage. This structure allows the agent to resonate across multiple levels of code abstraction. The system then uses tools such as Searchentity, Traversgraph and Interestity to allow LLMs to explore the system step by step. Using sparse hierarchical indexing ensures quick access to devices and graph designed supports multi-hop review, which is important to find connections across distant parts of the code base.
Locagent performs indexing within seconds and supports real -time use, making it convenient for developers and organizations. The researchers fine-tuned two open source models, QWEN2.5-7B, and QWEN2.5-32B, on a curated set of successful location courses. These models performed impressive on standard benchmarks. For example, on the SWE-BENCH-LITE DATA kit, Locagen obtained 92.7% file level accuracy using QWEN2.5-32B compared to 86.13% with Claude-3.5 and lower scores from other models. On the newly introduced LOC-Bench data set containing 660 examples across abdominal reports (282), functional requests (203), security questions (31) and benefit problems (144), Locagent again showed competitive results and achieved 84.59% ACC@5 and 87.06% ACC@10 on file level. Even the smaller QWEN2.5-7B model provided performance close to high cost-law models, while they only cost $ 0.05 per day. Example, a sharp contrast to $ 0.66 costs for Claude-3.5.
The core mechanism depends on a detailed graph -based indexing process. Each knot, whether represented a class or function, is uniquely identified with a fully qualified name and indexed using BM25 for flexible keyword search. The model allows agents to simulate a reasoning chain, beginning by extracting issuing keywords, continues through graphraversal and ends with code extraction for specific nodes. These actions are scored using a trusting method of trust based on prediction consistency over multiple iterations. Especially, when the researchers disabled tools such as Traversgraph or Searchentity, the benefit fell by up to 18%, which highlights their importance. Further, Multi-Hop Reasoning was critical; Fixing review jumps to a led to a decrease in the accuracy level of accuracy from 71.53% to 66.79%.
When used for downstream tasks such as GitHub issuing resolution, the locator increased the problem Pass Rate (Pass@10) from 33.58% in Baseline-Agentløse systems to 37.59% with the fine-tuned QWEN2.5-32B model. The modularity of the frame and open source nature makes it a compelling solution for organizations looking for internal alternatives to commercial LLMs. The introduction of LOC-Bench with its wider representation of maintenance tasks ensures a fair evaluation without pollution from pre-formation data.
Some important takeaways from the research at Locagent include the following:
- Locagenter converts code bases into heterogeneous graphs for reasoning on multiple levels.
- It achieved up to 92.7% file level accuracy on SWE-BENCH-LITE with QWEN2.5-32B.
- Reduced Code Localization Costs by approx. 86% compared to proprietary models. Introduced LOC-Bench data sets with 660 examples: 282 bugs, 203 functions, 31 security, 144 performance.
- Fine-tuned models (QWEN2.5-7B, QWEN2.5-32B) Performed comparable to Claude-3.5.
- Tools like Traversgraph and Searchentity turned out to be important with accuracy when they are disabled.
- Demonstrated applicability in the real world by improving the Github issuing resolution.
- It offers a scalable, cost-effective and effective alternative to proprietary LLM solutions.
Check out The paper and the github side. All credit for this research goes to the researchers in this project. You are also welcome to follow us on Twitter And don’t forget to join our 85k+ ml subbreddit.
Asif Razzaq is CEO of Marketchpost Media Inc. His latest endeavor is the launch of an artificial intelligence media platform, market post that stands out for its in -depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts over 2 million monthly views and illustrates its popularity among the audience.