Authorous (AR) models have made significant progress in language generation and are increasingly being investigated for image synthesis. However, scaling of AR models for high-resolution images remains a persistent challenge. Unlike text where relatively few symbols are required, high -resolution images require thousands of tokens, leading to square growth in calculation costs. As a result, most AR-based multimodal models are limited to low or medium-sized solutions, limiting their applicability to detailed image generation. While diffusion models have shown strong performance at high solutions, they come with their own restrictions, including complex sampling procedures and slower inference. Addressing token efficiency bottleneck of AR models remains an important open problem to enable scalable and practical synthesis with high resolution.
META AI introduces token-shuffle
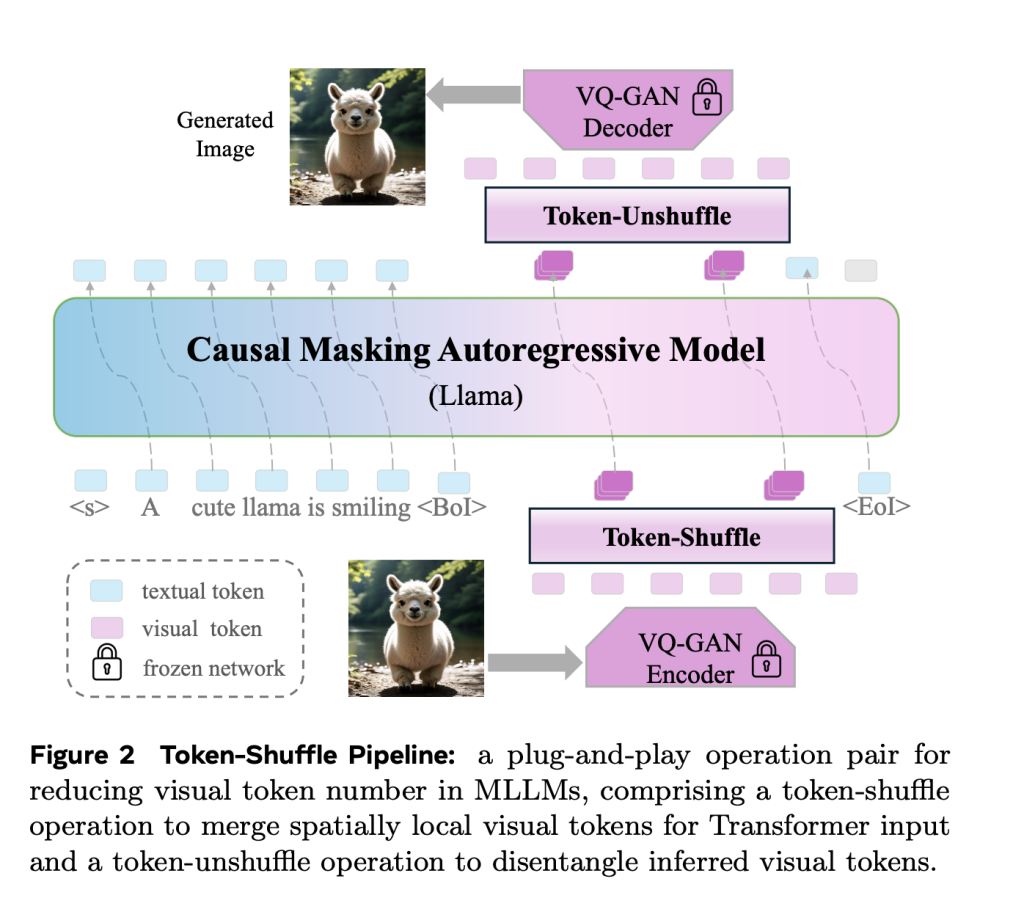
META AI introduces Token-shuffleA method designed to reduce the number of image tokens treated by transformers without changing the basic token prediction range. The most important insight underlying token-shuffle is the recognition of dimensional redundancy in visual vocabulary used by multimodal large language models (MLLMS). Visual tokens, typically derived from vector quantization models (VQ), occupy high -dimensional spaces, but bears a lower inherent information density compared to text token. Token-Shuffle utilizes this by merging spatially local visual tokens along the duct dimension before transformer therapy and then restoring the original spatial structure after inference. This token fusion mechanism allows AR models to handle higher solutions with significantly reduced calculation costs while maintaining visual faith.
Technical details and benefits
Token-shuffle consists of two operations: Token-shuffle and Token-Hushuffle. During input preparation, spatially nearby tokens merges using an MLP to form a compressed token that retains important local information. For a mixture of blend window, the number of tokens is reduced by a factor of S2S^2S2, leading to a significant reduction in transformer flops. After the transformer layers, token-replacement operation reconstructs the original spatial arrangement, again assisted by lightweight MLPs.
By compressing token sequences during transformer calculation, token-shuffle enables the effective generation of high resolution images, including them in the 2048 × 2048 resolution. It is important that this approach does not require changes to the transformer architecture itself, nor does it introduce help staff functions or prior coders.
In addition, the method integrates one Classification -Free Guidance (CFG) SCHEDULER Specifically adapted to autorgressive generation. Instead of using a fixed guidance scale across all symbols, the planner gradually adjusts guidance, minimizing early token artefacts and improving the text image adjustment.
Results and empirical insight
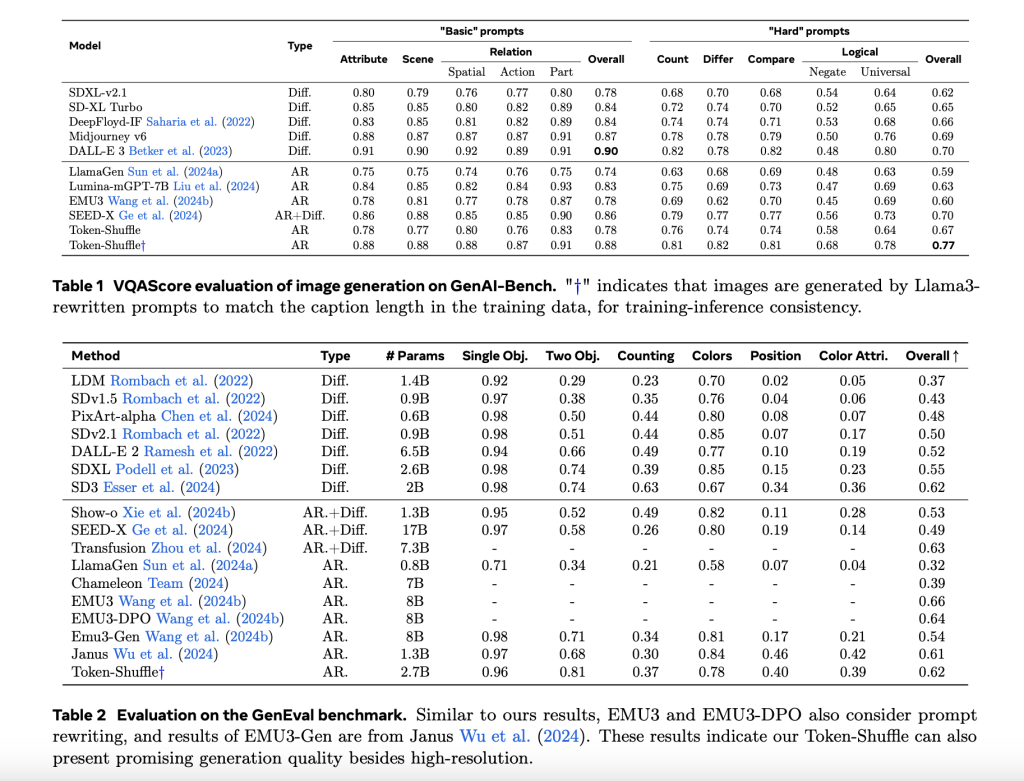
Token-Shuffle was evaluated on two large benchmarks: Genai-Bench and Genval. On Genai-Bench, using a 2.7B parameter llama-based model, token-shuffle obtained a Vqascore at 0.77 on “hard” promptBetter than other Authorous Models, such as the Lamage with a margin of +0.18 and diffusion models such as LDM with +0.15. In the Genval Benchmark it achieved an overall score on 0.62Setting a new baseline for AR models operating in the discreet token regime.
Large -scale human evaluation further supported these findings. Compared to the lamage, lumina-mgpt and diffusion base lines showed token-shuffle improved adaptation with textual PROMPS, reduced visual deficiencies and higher subjective image quality in most cases. However, less degradation in logical consistency was observed in relation to diffusion models, which suggests options for additional refinement.
With regard to visual quality, token-shuffle demonstrated the ability to produce detailed and coherent 1024 × 1024 and 2048 × 2048 images. Ablation studies revealed that smaller Shuffle window sizes (eg 2 × 2) offered the best compromise between calculation efficiency and output quality. Larger window sizes provided additional speedups, but introduced less loss in fine -grained detail.
Conclusion
Token-Shuffle presents a straightforward and effective method of tackling scalability limits for authentic image generation. By utilizing the inherent redundancy in visual vocabulary, it achieves significant reductions in calculation costs while preserving and in some cases improving generational quality. The method remains fully compatible with existing next token prediction frames, making it easy to integrate into standard AR-based multimodal systems.
The results show that token shuffle can push AR models in addition to prior resolution limits, making generation of high faith, high solution more practical and accessible. As research continues to promote scalable multimodal generation, token-shuffle provides a promising foundation for effective, total models capable of handling text and image methods in large scales.
Check Paper. Nor do not forget to follow us on Twitter and join in our Telegram Channel and LinkedIn GrOUP. Don’t forget to take part in our 90k+ ml subbreddit.
🔥 [Register Now] Minicon Virtual Conference On Agentic AI: Free Registration + Certificate for Participation + 4 Hours Short Event (21 May, 9- 13.00 pst) + Hands on Workshop
Asif Razzaq is CEO of Marketchpost Media Inc. His latest endeavor is the launch of an artificial intelligence media platform, market post that stands out for its in -depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts over 2 million monthly views and illustrates its popularity among the audience.
