Despite rapid advances in the vision language modeling, much of the progress of this field is shaped by models trained on proprietary data sets and often depend on distillation from closed source systems. This addiction creates barriers to scientific transparency and reproducibility, especially for tasks involving fine -grained image and video understanding. Benchmark performance may reflect training data and black-box model functions more than architectural or methodological improvements, making it difficult to assess true research progress.
To tackle these limitations, Meta AI has introduced Perception Language Model (PLM), a fully open and reproducible framework for vision language modeling. PLM is designed to support both image and video inputs and are trained without the use of proprietary model outputs. Instead, it draws from large -scale synthetic data and recently collected human labeled data sets, enabling a detailed evaluation of model behavior and training dynamics under transparent conditions.
PLM frame integrates a vision codes (Perception Encoder) with Llama 3 -Language Ecoders in different sizes -1B, 3B and 8B parameters. It uses a multi -stage training pipeline: Initial heating with low -resolution synthetic images, large -scale midtraining on different synthetic data sets and monitored fine tuning using high -resolution data with precise comments. This pipeline emphasizes exercise stability and scalability while maintaining control over data beverages and content.
A key contribution from the work is the release of two large -scale high -quality video data sets that address existing gaps in temporal and spatial understanding. The PLM – FGQA Data sets include 2.4 million question-response pairs that capture fine-grained details of human actions-such as object manipulation, direction of movement and spatial relationships-across different video domains. To supplement this is PLM – STCA dataset with 476,000 spatial-time captions linked to segmentation masks that track items across time, allowing models to resonate about “what” “where” and “when” in complex video scenes.
Technically, PLM uses a modular architecture that supports high-resolution image tiling (up to 36 tiles) and multi-frame video input (up to 32 images). A 2-layer MLP projector connects the visual codes to LLM, and both synthetic and human brand data are structured to support a wide range of tasks, including caption, visual questions answers and close region-based reasoning. The synthetic data engine, which is built entirely using Open Source models, generates ~ 64.7 million samples across natural images, charts, documents and videos-what makes diversity while avoiding dependence on proprietary sources.
META AI also introduces PLM – VideoBenchA new benchmark designed to evaluate aspects of video understanding not caught by existing benchmarks. It includes tasks such as fine-grained activity recognition (FGQA), Smart-Glasses Video QA (SGQA), Region-based close caption (RDCAP) and spatial-time location (RTLOC). These tasks require models to participate in temporarily grounded and spatial explicit reasoning.
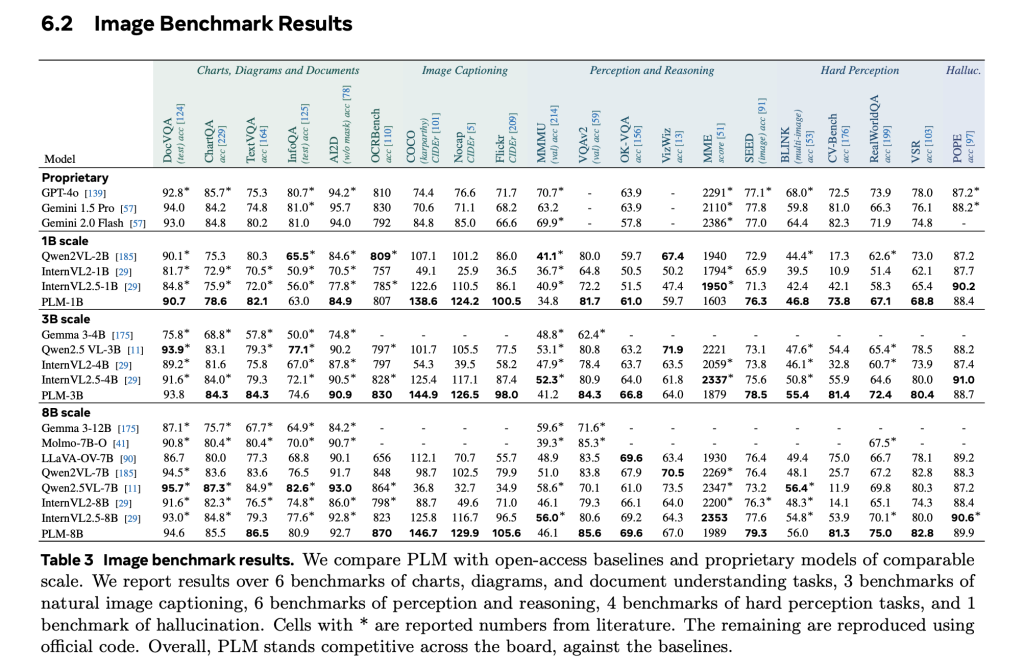
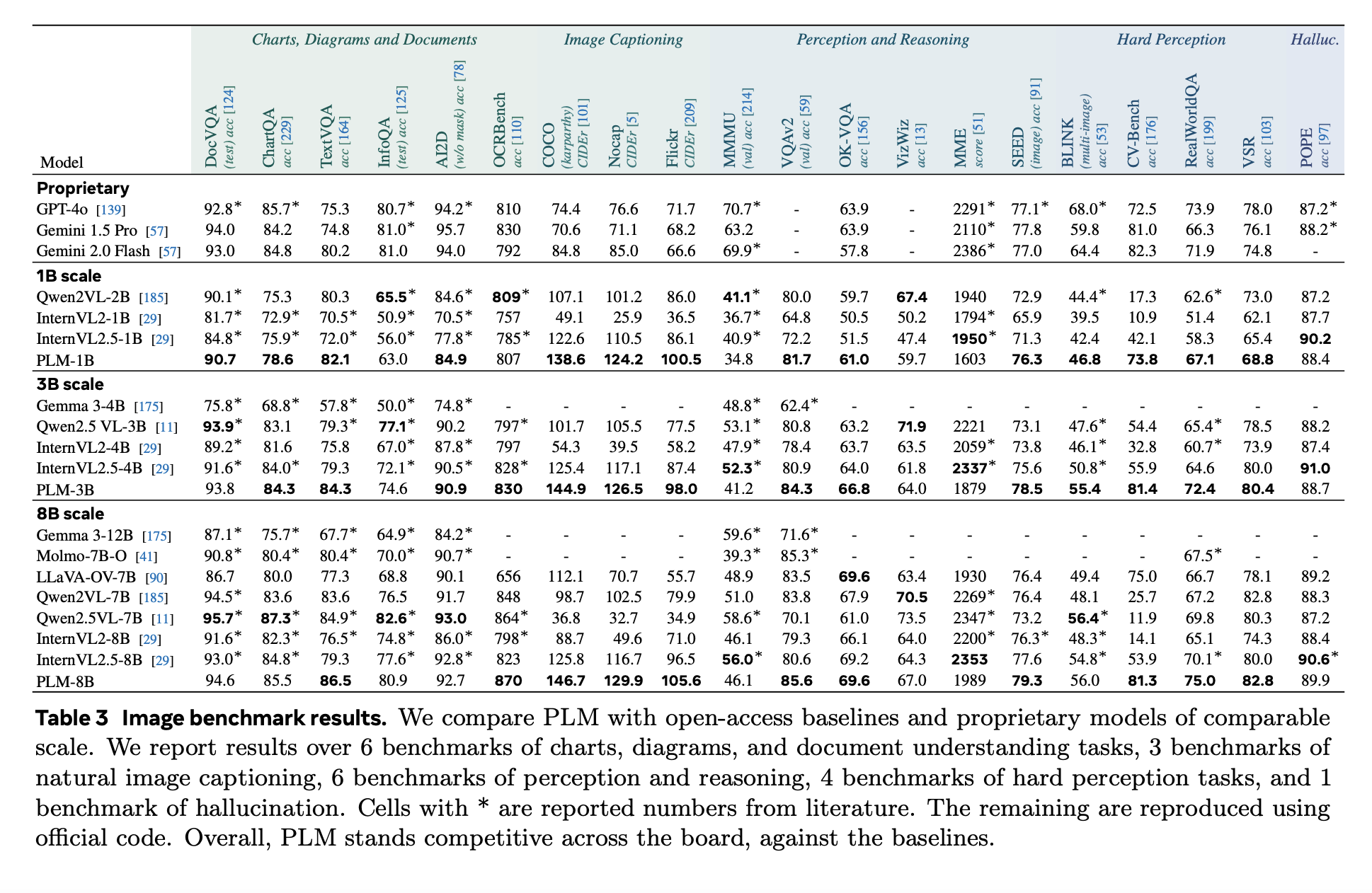
Empirical evaluations show that PLM models, especially in the 8B parameter scale, perform competitively over 40+ image and video benchmarks. In video images, PLM winnings of +39.8 cider achieve on average over open base lines. On PLM-Videobench, the 8B variant closes the gap with human performance in structured tasks, such as FGQA and shows improved results in spatial-time location and close caption. In particular, all results are obtained without distillation from closed models, which emphasizes the possibility of open, transparent VLM development.
In summary, PLM offers a methodological string and completely open framework for training and evaluation of vision -language models. Its release includes not only models and code, but also the largest curated data set for fine-grained video understanding and a benchmark suite that is targeted at previously under-explored capabilities. PLM is located to serve as a foundation for reproducible research in Multimodal AI and a resource for future work with detailed visual reasoning in open surroundings.
Here it is PaperAt Model and Code. Nor do not forget to follow us on Twitter and join in our Telegram Channel and LinkedIn GrOUP. Don’t forget to take part in our 90k+ ml subbreddit.
🔥 [Register Now] Minicon Virtual Conference On Agentic AI: Free Registration + Certificate for Participation + 4 Hours Short Event (21 May, 9- 13.00 pst) + Hands on Workshop
Asif Razzaq is CEO of Marketchpost Media Inc. His latest endeavor is the launch of an artificial intelligence media platform, market post that stands out for its in -depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts over 2 million monthly views and illustrates its popularity among the audience.
