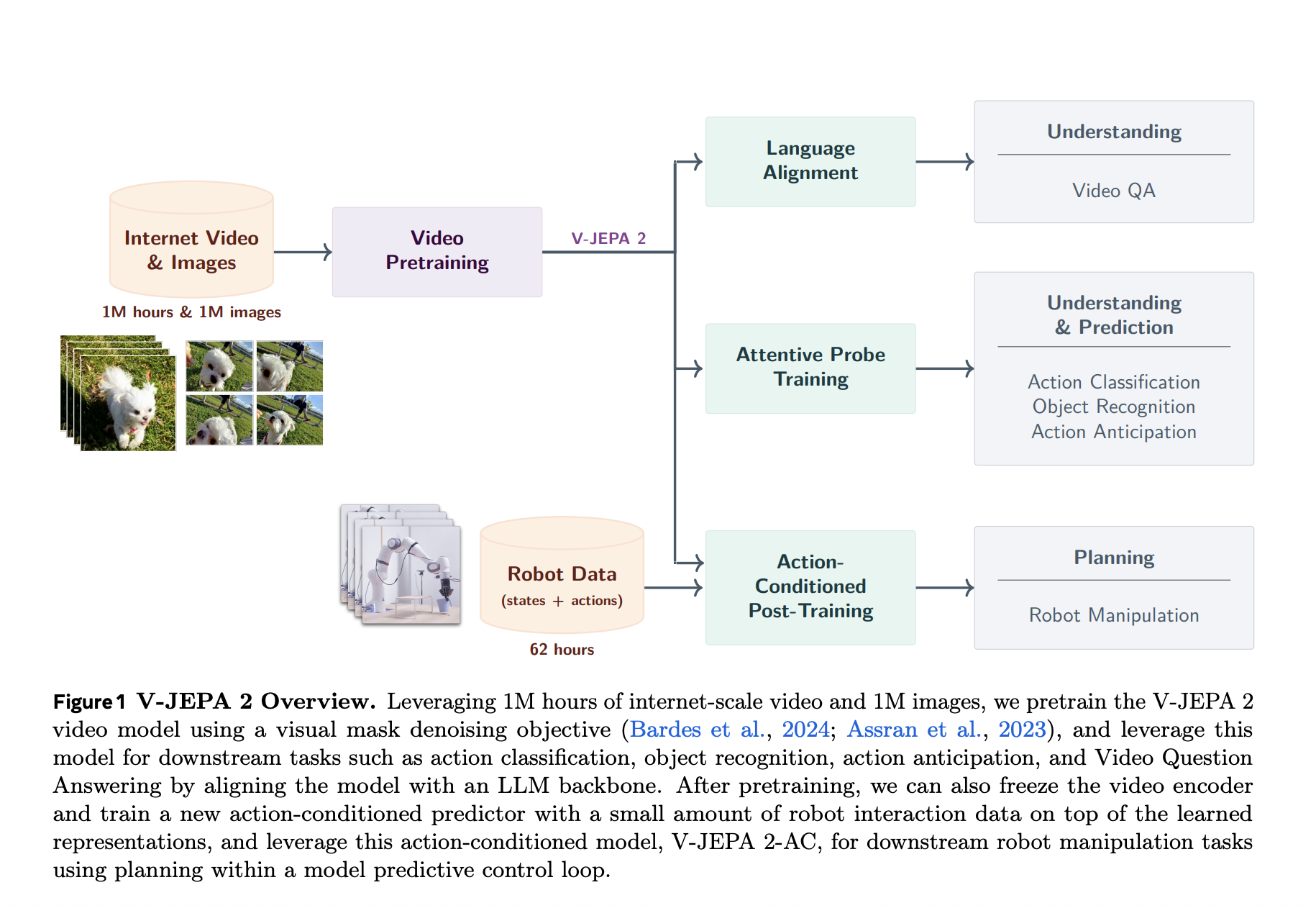
Meta AI has introduced V-JEPA 2, a scalable open source world model designed to learn from video in internet scale and enables robust visual understanding, future state propagation and zero-shot planning. Building on the common embedding prediction architecture (JEPA) shows V-JEPA 2 how self-monitored learning from passive internet video combined with minimal robotic interaction data can provide a modular foundation for intelligent physical agents.
Scalable self -experienced prior prior from 1 m hours of video
V-JEPA 2 is prior to 1 million hours of internet-scale video combined with 1 million images. Using a visual mask that can denoize target, the model learns to reconstruct masked spatiotemporal patch in a latent representation room. This approach avoids the inefficiency of predicting pixel level by focusing on predictable stage dynamics while ignoring irrelevant noise.
To scale the JEPA pre -elucing to this level, metaphects introduced four key techniques:
- Data Salation: Constructed a 22-test dataset (Videox22m) from public sources such as SSV2, Kinetics, HowTo100m, YT-Temporal-1B and Image.
- Model scaling: Expanded code capacity to over 1b parameters using Vit-G.
- Educational Plan: Adopted a progressive resolution strategy and expanded prior to 252K iterations.
- Spatial-time magnification: Trained on gradually longer and higher resolution clips and reaches 64 images at 384 × 384 resolution.
These design selections led to an average accuracy of 88.2% across six benchmark assignments-Inclusive SSV2, Diving-48, Jester, Kinetics, Coin and Imaget-there are previous basic lines.
Understanding through masked representation learning
V-JEPA 2 exhibits strong movement understanding functions. On the somewhat-something V2-benchmark, it achieves 77.3% Top-1 accuracy that surpasses models such as internal video and VideoMaev2. For understanding the appearance, it is still competitive with advanced caption-Pretraining models such as Dinov2 and Pecoreg.
Cod’s representations were evaluated using attentive probes, which confirmed that self-monitored learning alone can provide transferable and domain-embarrassing visual functions that apply across different classification tasks.
Temporal Reasoning via Video Questions Answer
To assess temporal reasoning, the V-JEPA 2 coder is in line with a multimodal large language model and evaluated on several video-matched tasks. Despite a lack of language monitoring under the prior, the model achieves:
- 84.0% on perception test
- 76.9% on Temp Compass
- 44.5% on MVP
- 36.7% on Temporalbench
- 40.3% on tomato
These results challenge the assumption that the visual language adaptation requires co-training from the start, which shows that a prior video codes can be adjusted according to HOC with strong generalization.
V-JEPA 2-AC: Learning Latent World Models for Robot Planning
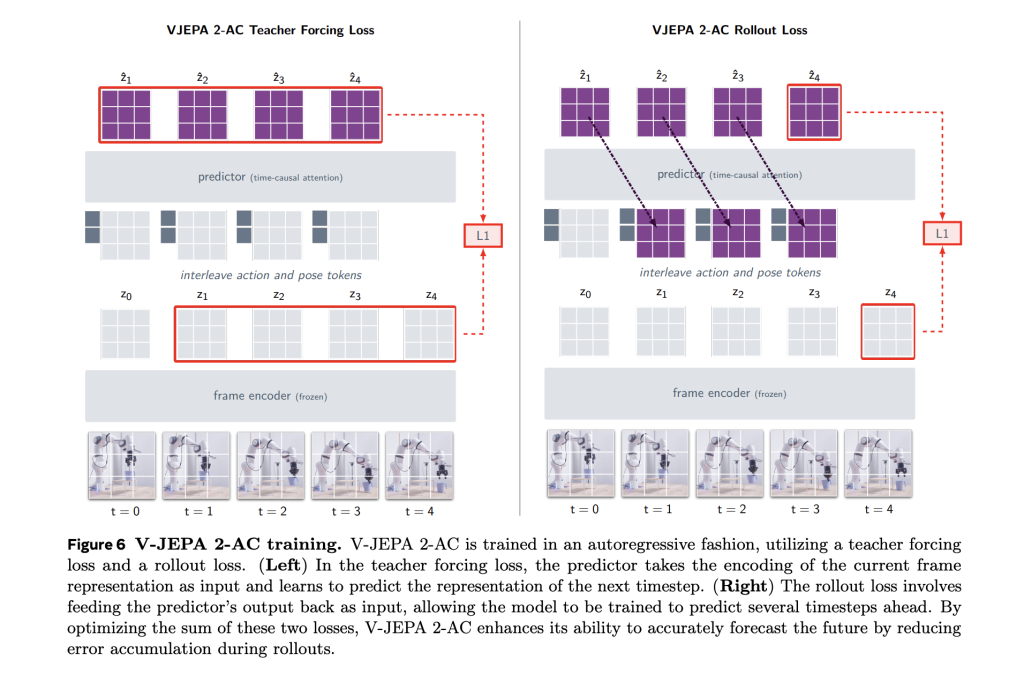
An important innovation in this release is V-JEPA 2-AC, an action-conditioned variant of the previous codes. Fine tuned by spending only 62 hours unmarked robotic video from the DROID data set, V-JEPA 2-AC learns to predict future video deposits conditioned by robot actions and poses. Architecture is a 300 m parameter transformer with block-causal attention trained using a teacher-double and roll-out target.
This allows zero-shot planning through model-predictable control. The model provides action sequences by minimizing the distance between imagined future conditions and visual goals using cross -border entropim method (CEM). It achieves great success in tasks such as reaching, grabbing and picking-and-place on unseen robotic arms in various laboratories-without reward supervision or additional data collection.
Benchmarks: Robust performance and planning efficiency
Compared to basic lines such as octo (behavior cloning) and cosmos (latent diffusion world models), V-JEPA 2-AC:
- Performs plans of ~ 16 seconds per Steps (towards 4 minutes for cosmos).
- Reach a 100% success rate on REACH tasks.
- Surpass others in grip and manipulation tasks across object types.
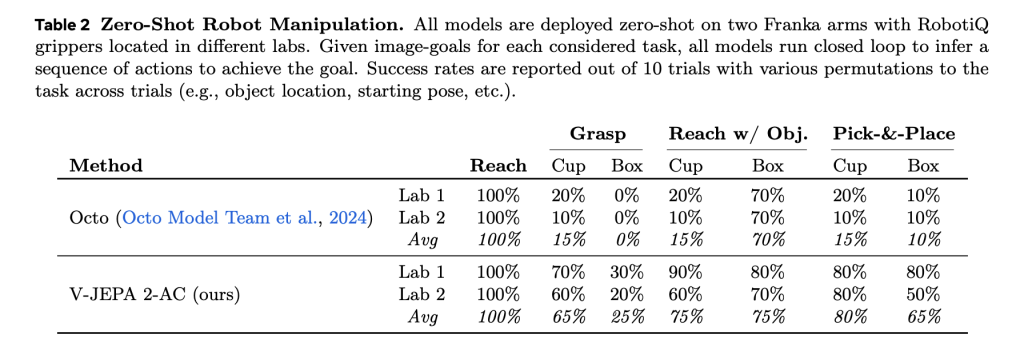
In particular, it works with the help of a monocular RGB camera without calibration or environmentally specific fine tuning, which strengthens the learned world model.
Conclusion
Meta’s V-JEPA 2 represents a significant progress in scalable self-overwritten learning for physical intelligence. By decoupling observation learning from action conditioning and utilizing the large passive video on a large scale, V-JEPA 2 shows that general visual representations can be exploited for both perception and control in the real world.
Check PaperAt Models about hug face and GitHub Page. All credit for this research goes to the researchers in this project. You are also welcome to follow us on Twitter And don’t forget to join our 99k+ ml subbreddit and subscribe to Our newsletter.
Asif Razzaq is CEO of Marketchpost Media Inc. His latest endeavor is the launch of an artificial intelligence media platform, market post that stands out for its in -depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts over 2 million monthly views and illustrates its popularity among the audience.
