In today’s rapidly evolving technological landscape, developers and organizations often struggle with a number of practical challenges. One of the most significant obstacles is effective processing of different data types – text, speech and vision – within a single system. Traditional approaches have typically required separate pipelines for each modality, leading to increased complexity, higher latency and greater calculation costs. In many uses – from health diagnosis to financial analysis – these limitations can prevent the development of responsive and adaptive AI solutions. The need for models that balancing robustness with efficiency is more urgent than ever. In this context, Microsoft’s recent work with small language models (SLMs) provides a promising approach by striving to consolidate capabilities into a compact, versatile package.
Microsoft AI has recently introduced Phi-4-Multimodal and Phi-4-mini, the latest additions to its Phi family of SLMs. These models have been developed with a clear focus on streamlining multimodal treatment. Phi-4-Multimodal is designed to handle text, speech and visual input simultaneously, all within a unified architecture. This integrated approach means that a single model can now interpret and generate answers based on different data types without the need for separate, specialized systems.
In contrast, the Phi-4-MINI is tailored specifically for text-based tasks. Despite being more compact, it has been constructed to excel in reasoning, coding and instruction after. Both models are made available via platforms such as Azure AI foundry and embraced face, ensuring that developers from a number of industries can experiment with and integrate these models into their applications. This balanced release represents a thoughtful step toward making advanced AI more practical and accessible.
Technical details and benefits
At the technical level, Phi-4-Multimodal is a 5.6 billion parameter model that incorporates a mixture of Loras-one method that allows the integration of speech, vision and text into a single representation room. This design significantly simplifies architecture by removing the need for separate treatment pipes. As a result, the model not only reduces calculation overhead, but also achieves lower latency, which is especially advantageous for real -time applications.
Phi-4-mini, with its 3.8 billion parameters, is built as a dense, only decoding transformer. It contains grouped attention and boasts a vocabulary of 200,000 tokens, enabling it to handle sequences of up to 128,000 tokens. Despite its smaller size, Phi-4-mini works remarkably well in tasks that require deep reasoning and language understanding. One of its prominent features is the capacity of the functional call-what gives it to interact with external tools and APIs, thus expanding its practical tools without requiring a larger, more resource-intensive model.
Both models have been optimized for performing devices. This optimization is especially important for applications in environments with limited calculation resources or in edge calculation scenarios. The reduced calculation requirements of the models make them a cost-effective choice, ensuring that advanced AI functionalities can be implemented even on devices that do not have extensive treatment functions.
Performance Insights and Benchmark Data
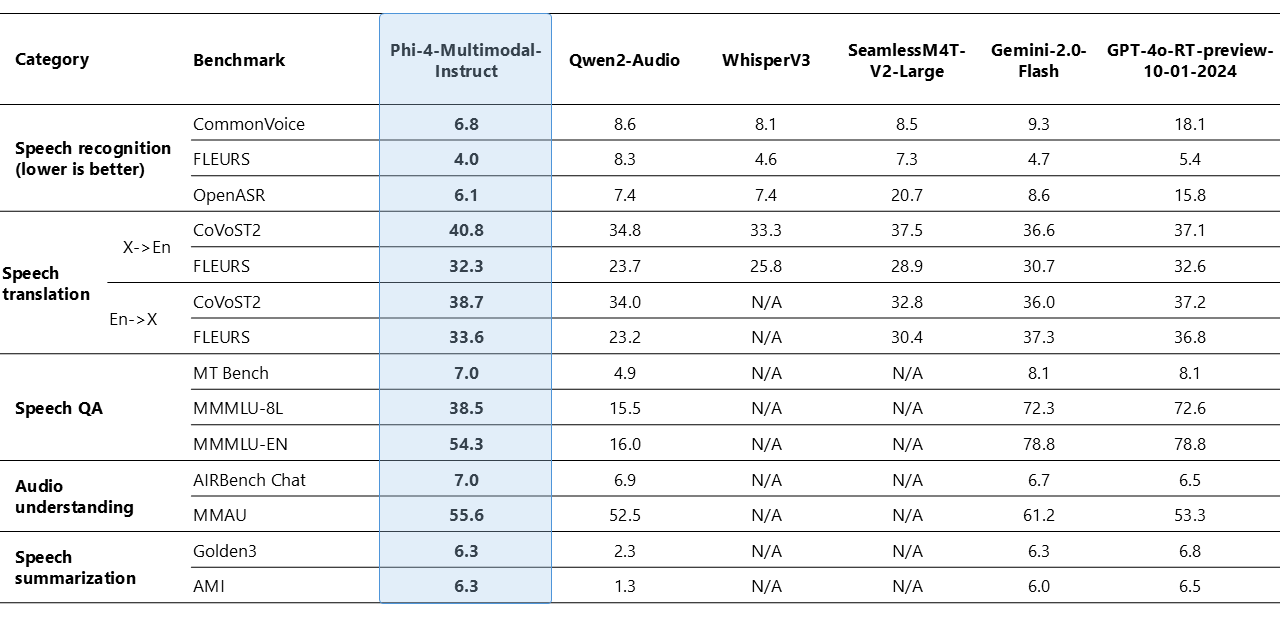
Benchmark results provide a clear overview of how these models work in practical scenarios. E.g. Has Phi-4-Multimodal shown an impressive word error speed (WER) of 6.14% in Automatic Speech Recognition (ASR) tasks. This is a modest improvement over previous models such as Whisperv3 reporting a WER of 6.5%. Such improvements are especially important in applications where accuracy in speech recognition is critical.
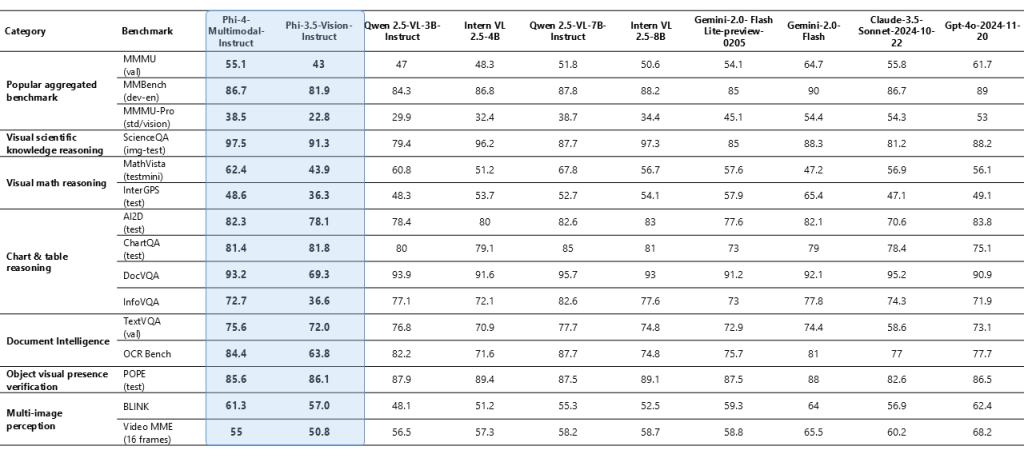
In addition to ASR, Phi-4-Multimodal also shows robust performance in tasks such as speech translation and summary. Its ability to process visual input is remarkable in tasks such as documents, short understanding and optical character recognition (OCR). In several benchmarks, synthetic speech interpretation on visual data to document analysis voices the model’s performance consistently with or exceeds the models for larger, more resource-intensive models.
Similarly, Phi-4-mini has been evaluated in a number of languages benchmarks where it keeps its own despite its more compact design. Its ability to resonate, deal with complex mathematical problems and coding tasks emphasize its versatility in text -based applications. The inclusion of a functional mechanism further enriches its potential, enabling the model to draw on external data and tools seamlessly. These results emphasize a measured and thought -provoking improvement of multimodal and language processing functions, providing clear advantages without exaggerating its performance.
Conclusion
The introduction of Phi-4-Multimodal and Phi-4-mini of Microsoft marks an important development within AI. Instead of relying on voluminous, resource-demanding architectures, these models offer a refined balance between efficiency and performance. By integrating multiple modalities into a single, coherent framework, the phi-4-multimet modal complexity, which is associated with multimodal treatment. Meanwhile, Phi-4-MINI provides a robust solution for text-intensive tasks, proving that smaller models can actually offer significant capabilities.
Check out The technical details and model on the hug face. All credit for this research goes to the researchers in this project. You are also welcome to follow us on Twitter And don’t forget to join our 80k+ ml subbreddit.
🚨 Recommended Reading AI Research Release Nexus: An Advanced System Integrating Agent AI system and Data Processing Standards To Tackle Legal Concerns In Ai Data Set
Aswin AK is a consulting intern at MarkTechpost. He is pursuing his double degree at the Indian Institute of Technology, Kharagpur. He is passionate about data science and machine learning, which brings a strong academic background and practical experience in solving real life challenges across domains.
🚨 Recommended Open Source AI platform: ‘Intellagent is an open source multi-agent framework for evaluating complex conversation-ai system’ (promoted)