Quantization after training (PTQ) Focuses on reducing the size and improving the speed of large language models (LLMs) to make them more practical for use in the real world. Such models require large amounts of data, but highly crooked and very heterogeneous data distribution during quantization causes significant difficulties. This would inevitably expand the quantization area, which makes it a less accurate expression in most values and reduces the general performance of model precision. While PTQ methods aim to tackle these problems, challenges remain in effectively distributing data across the quantity room, limiting the potential of optimization and hindering broader implementation in resource-limited environments.
Current methods after training (PTQ) methods of large language models (LLMS) focus on only weight and weight activation quantization. Only methods of weight, such as GPTQAt Awqand OwqAttempts to reduce memory consumption by minimizing quantization errors or addressing activation outliners but not optimizing precision for all values in full. Techniques like Quip and Quip# Use random matrixes and vector quantization, but remain limited to handling extreme data distributions. Weight activation quantization aims to accelerate the inference by quantizing both weights and activations. Yet as methods like SmoothquantAt Zeroquantand Quarot Struggling to deal with the dominance of activation providers, causing errors in most values. In general, these methods depend on heuristic approaches and fail to optimize data distribution across the entire quantization room, which limits performance and efficiency.
To tackle the limitations of heuristic methods of quantization after training (PTQ) and the lack of a metric for assessing quantization efficiency, researchers from Houmo Ai, Nanjing University, and Southeast University suggested Quantization room utilization speed (QSUR) concept. QSUR measures how effective weight and activation distributions use the quantization room, offering a quantitative basis for evaluating and improving PTQ methods. The metric utilizes statistical properties such as self -value degradation and confidence ellipoids to calculate hyper -volumes of weight and activation distributions. QSUR analysis shows how linear and rotation transformations affect quantization efficiency, with specific techniques that reduce differences between the channel and minimize outliers to improve performance.
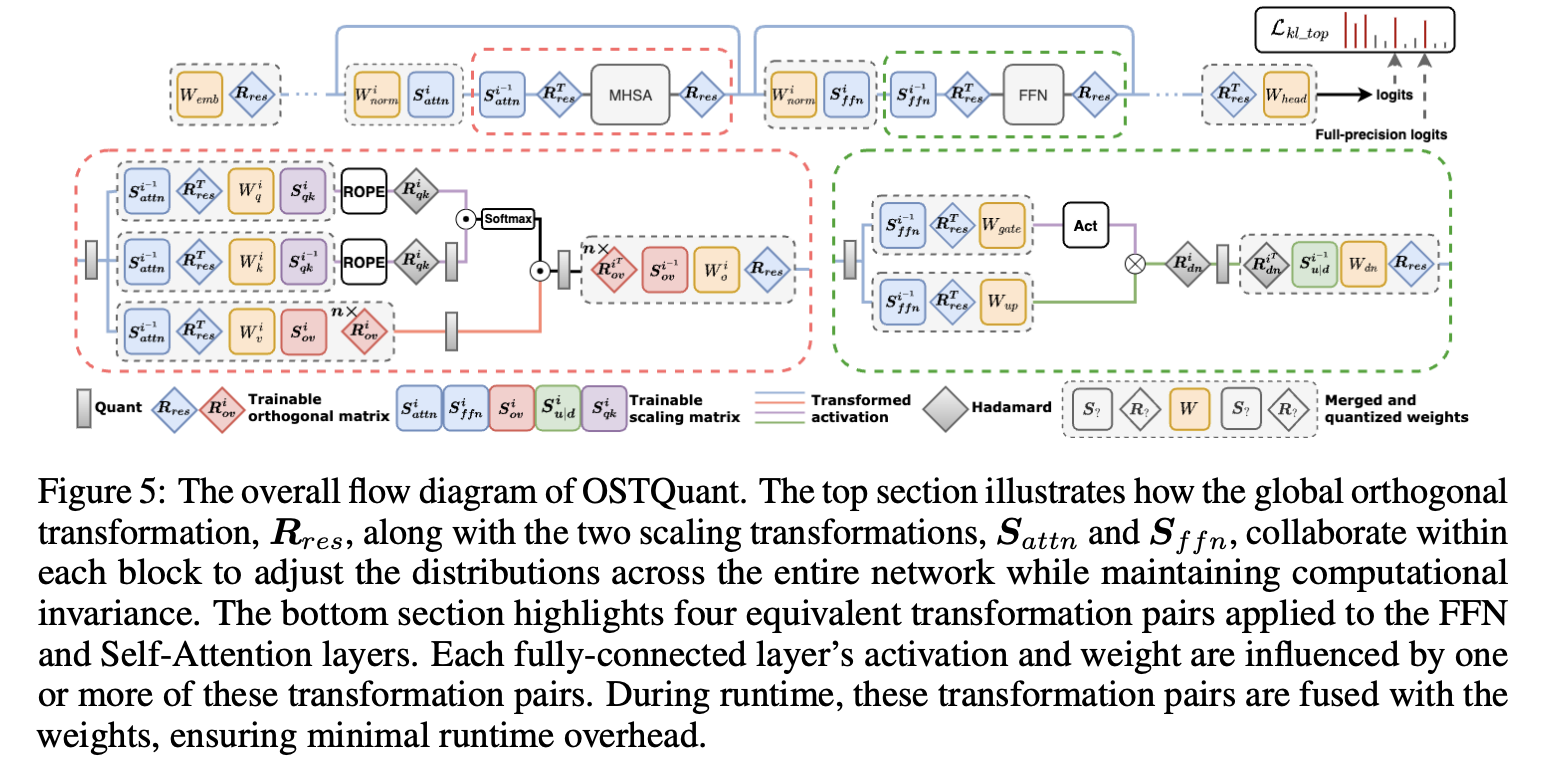
Scientists suggested Ostquant Frames that combine orthogonal and scaling transformations to optimize the weight and activation distribution of large language models. This procedure integrates educational equivalent transformation pairs of diagonal scaling and orthogonal matrixes, which guarantees calculation efficiency while retaining equivalence by quantization. It reduces overfitting without compromising output from the original network at the time of inference. Ostquant using inter-block learning to spread transformations globally across Llm blocks, use of techniques such as Weight Outlier Minimization Initialization (WOMI) For effective initialization. The method achieves higher QsurReduces Runtime -Overhead and improves quantization performance in LLMS.
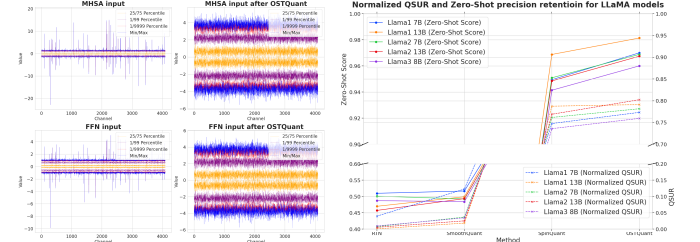
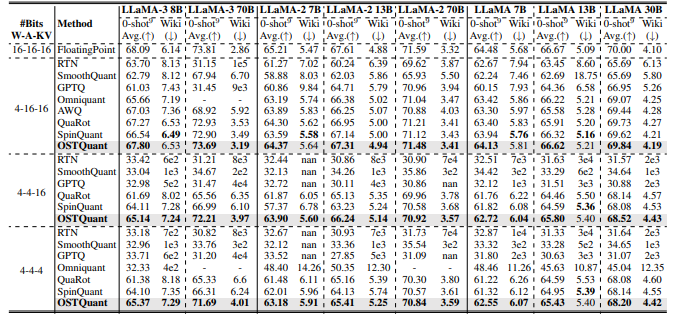
For evaluation purposes used researchers Ostquant to Llama family (Llama-1, llama-2, and Llama-3) and assessed performance using confusion at Wikitext2 and nine zero-shot tasks. Compared to methods that SmoothquantAt GPTQAt Quarotand SpinquantAt Ostquant surpassed them consistently and obtained the least 99.5% floating point accuracy below 4-16-16 Setup and marked narrowing of performance holes. Llama-3-8B only applied to one 0.29-point fall in Zero-shot tasksCompared to loss overrun 1.55 Points for others. In harder scenarios, ostquant was better than spinquant and achieved as much as 6.53 Points by Llama-2 7b In the 4-4-16 setup. The KL-Top Tab feature provided a better mounting of semantics and reduced noise, which improved performance and lower holes in W4A4KV4 by 32%. These results showed that Ostquant Is more effective in handling outlier and ensuring distributions is more objective.

Ultimately, the proposed method optimized the data distribution in the quantization room based on QSUR-metric and loss function, KL-Top, which improved the performance of large language models. With low calibration data, it reduced the noise and preserved semantic wealth compared to existing quantization techniques and achieved high performance in several benchmarks. This framework can serve as a basis for future work, start a process that will help to perfect quantization techniques and make models more efficient for applications that require high calculation efficiency in resource -limited settings.
Check out the paper. All credit for this research goes to the researchers in this project. Nor do not forget to follow us on Twitter and join in our Telegram Channel and LinkedIn GrOUP. Don’t forget to take part in our 70k+ ml subbreddit.
🚨 [Recommended Read] Nebius AI Studio is expanded with visual models, new language models, embedders and lora (Promoted)
Divyesh is a consulting intern at MarkTechpost. He is pursuing a BTech in agricultural and food technology from the Indian Institute of Technology, Kharagpur. He is a data science and machine learning enthusiast who wants to integrate these leading technologies into the agricultural domain and solve challenges.
✅ [Recommended] Join our Telegram -Canal