LLMs have shown strong general performance across different tasks, including mathematical reasoning and automation. However, they are struggling in domain -specific applications where specialized knowledge and nuanced reasoning are important. These challenges arise primarily from the difficulty of accurately representing knowledge of long-tailed domain within limited parameter budgets, leading to hallucinations and the lack of domain-specific reasoning skills. Conventional approaches to domain adaptation — such as fine-tuning or continuous predetermining-resorting often in unspecified knowledge and increased training costs. While it is useful for supplementing knowledge, RAG methods typically come to a short time in teaching models how to resonate with this information. An important research challenge is how to separate the learning of domain knowledge from reasoning, enabling models to prioritize cognitive skills development under limited resources.
Drawing parallels from educational theory, especially Bloom’s taxonomy, it becomes clear that building advanced reasoning skills requires more than just knowledge memory. Cognitive abilities with higher order-as analysis, evaluation and synthesis are often hindered when models are stressed to remember extensive domain facts. This observation raises the question of whether justification functions can be improved independently of large -scale knowledge internalization. In practice, many existing methods focus strongly on storing knowledge in model parameters, complicating updates and increasing the risk of outdated or wrong output. Even retrieval techniques processes retrieved documents such as input rather than tools for learning reasoning processes. The future of domain -specific intelligence may depend on approaches that reduce the dependence on internal memory and instead use external knowledge sources as scaffolding to resonate skills, which allows smaller models to solve complex tasks more effectively.
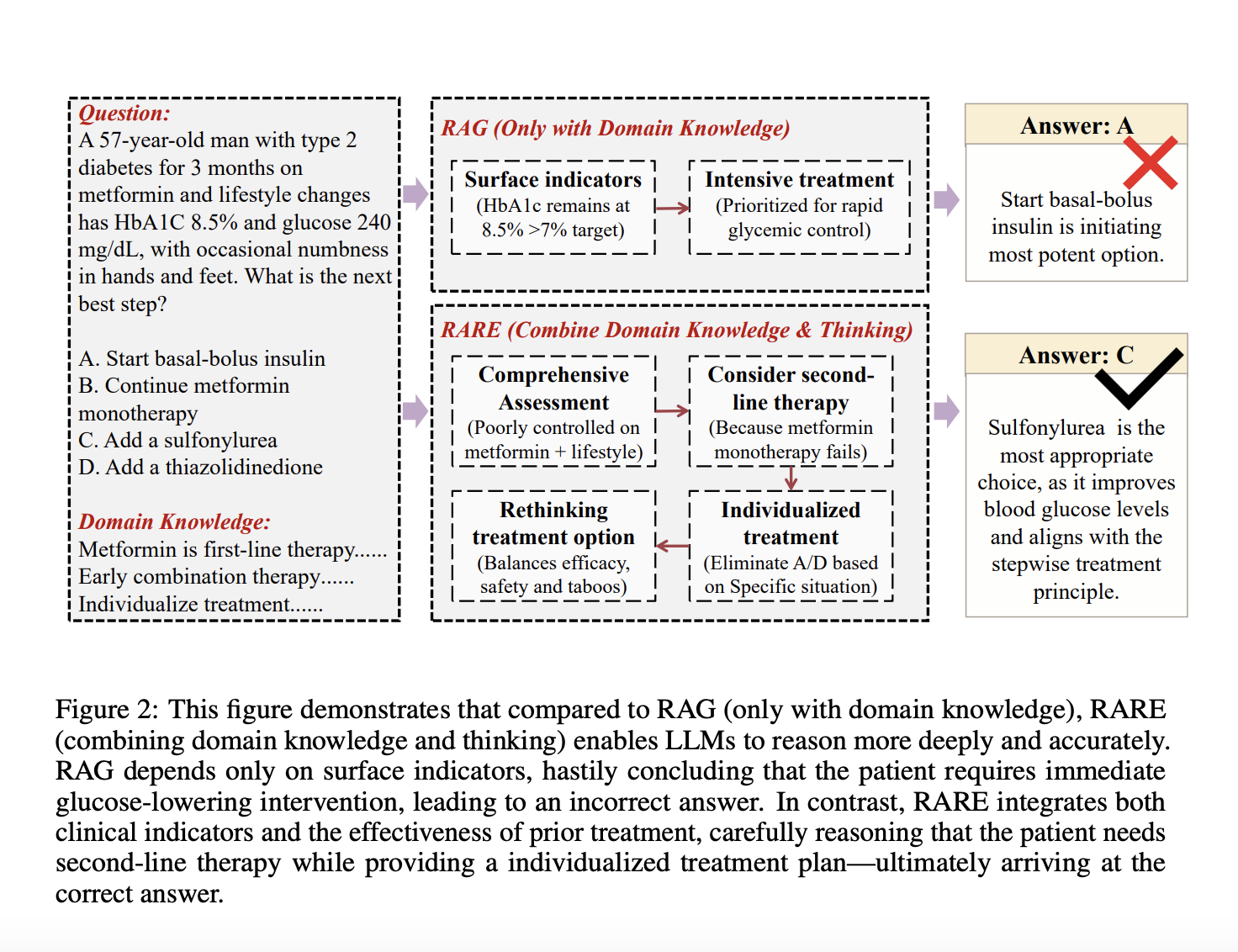
Researchers from Peking University, Shanghai Jiao Tong University, Northeastern University, Nankai University, Institute for Advanced Algorithms Research (Shanghai), Innerhub Technology, Memtensor and Shanghai Artificial Intelligence Laboratory have introduced a new paradigm called Retrecling-Augue Augue Modeling (rare). Inspired by Bloom’s taxonomy, weird knowledge storage separates reasoning using external databases for domain knowledge while training models to focus on contextual justification. This allows models to bypass memory -heavy factual learning and prioritize cognitive skills development. Experiments show that light rare trained models surpass larger models such as GPT-4 on benchmarks, offering a scalable and effective approach to domain-specific intelligence.
A proposed framework shifts the focus from remembering domain knowledge to the development of reasoning skills. By combining obtained external knowledge with step-by-step-Reasoning, models generate answers based on understanding and use rather than recall. The frameworks model answers as a number of knowledge and reasoning brands, optimization for integration of retrieved information and contextual inference. Using expert models for knowledge distillation, it builds high quality educational data and uses adaptive refinement for correctness. Founded in cognitive theories such as contextual learning, this approach allows easy models to achieve strong domain -specific performance through fine -tuning and reasoning centric training.
The study evaluates the effectiveness of the rare framework using five health-focused QA datasets that require multi-hop resonnection. Lightweight models such as Llama-3.1-8B, QWEN-2.5-7B and MISTRAL-7B were tested against COT, SFT and RAG Baselines. The results show that rarely consistently exceeds these baselines across all tasks with remarkable medical diagnosis and scientific reasoning gains. Compared to Deepseek-R1-Distill-Llama-8B and GPT-4, rare trained models obtained higher accuracy, which exceeded GPT-4 by over 20% on some tasks. These findings emphasize that training models for domain -specific reasoning through structured, contextual learning are more effective than simply increasing the model size or relying on retrieval.
Finally, the study rarely presents a new framework that improves domain -specific reasoning in LLMs by separating knowledge storage from reasoning development. Rarely from Bloom’s taxonomy avoids weird parameter -tongue memory by retrieving external knowledge during inference and integrating it into training staff and encouraging contextual justification. This shift allows lightweight models to surpass greater as GPT-4 on medical tasks and achieve up to 20% higher accuracy. Rare promotes a scalable approach to domain -specific intelligence by combining maintenance knowledge bases with effective, reasoning -focused models. The future work will explore reinforcement learning, data curation and applications across multimodal and open domain tasks.
Check out the paper. All credit for this research goes to the researchers in this project. You are also welcome to follow us on Twitter And don’t forget to join our 85k+ ml subbreddit.
🔥 [Register Now] Minicon Virtual Conference On Open Source AI: Free Registration + Certificate of Participation + 3 Hours Short Event (12 April, at [Sponsored]
Sana Hassan, a consultant intern at MarkTechpost and dual-degree students at IIT Madras, is passionate about using technology and AI to tackle challenges in the real world. With a great interest in solving practical problems, he brings a new perspective to the intersection of AI and real solutions.
