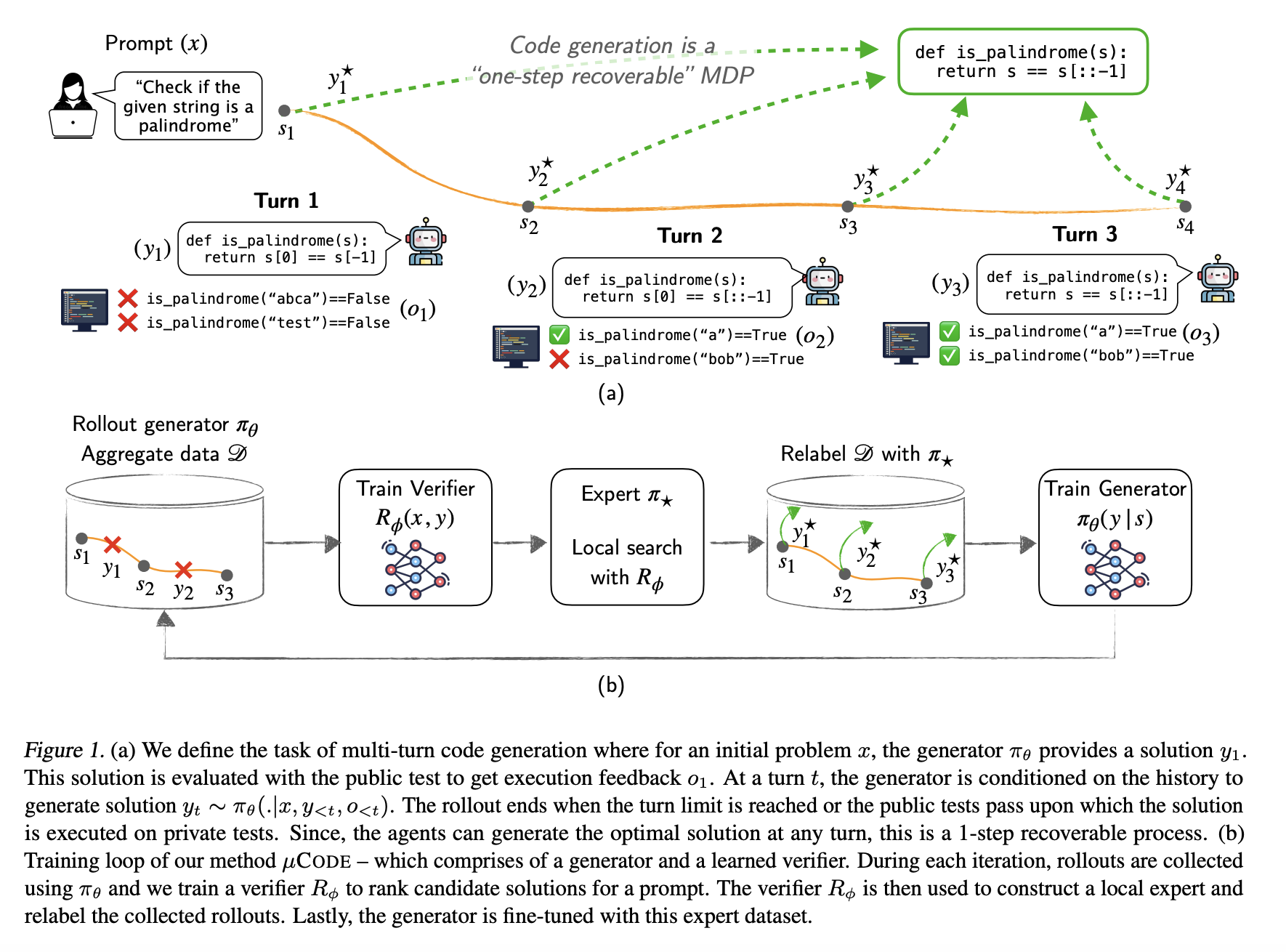
Generating code with Executive Feedback is difficult because errors often require multiple corrections and it is not easy to attach them in a structured way. Exercise models to learn from feedback in execution is necessary, but is approaching on the basis of challenges. Some methods try to correct errors in a single step, but fail when more improvements are needed. Others use complex learning techniques to optimize long -term improvements. These methods are still struggling with weak learning signals, making training slow and ineffective – the lack of an effective method of handling iterative corrections results in unstable learning and poor performance.
Currently asking for-based systems Try to solve multiple step tasks using self -debt, test generation and reflection, but improves little. Some methods train reward models as Coderl for fixing errors and ARCHER For structured decision -making while others are using Monte Carlo Tree Search (MCS) But requires too much calculation. Verifier-based approaches, like “Let’s verify step by step“And AlphacodeHelp finding errors or creating test cases, but some models are only dependent on syntaxcheck, which is not enough for proper training. Score limits training steps and Ladder Uses complex corrections, make learning ineffective. Finely tuned agents like FireactAt SKIP and feedback -based models that RL4VLM and Glam Try to improve performance. However, the current techniques either fail to refine the code correctly over several steps or are too unstable and ineffective.
In order to mitigate these questions suggested scientists µcodeA multi-turn coding generation method that improves using feedback with execution. Existing approaches face challenges with execution errors and reinforcement learning complexity, but µcode overcomes these by following an expert iteration frame with a local search expert. A verifier evaluates code quality, while a generator learns from the best solutions that refine its output of multiple iterations. Under inference, a Best-of-n Search strategy helps to generate and improve the code based on execution results, ensuring better performance.
The framework first trains a verifator through monitored learning to score code pieces, making evaluations more reliable. Binary cross -tropy Predicts correctness while Bradley-Terrry ranks solutions for better choices. The generator then learns iteratively by the fact that reversible earlier output with expert -selected solutions and improve accuracy. Several solutions are produced by inference and the verifier chooses the best, refining output until all tests exist. By treating code generation as an imitation learning problem, µcode eliminates complex exploration and enables effective optimization.
Researchers evaluated µcodes effectiveness by comparing it to advanced methods, analyzing the effect of the learned verifier during exercise and inference and assessing various loss functions for verifator training. The generator was initialized using Llama models and experiments were performed on MBPP and Human Revel datasets. The training was performed on MBPP’s training kits with evaluations of its test sets and human events. Comparisons included one-turn and multi-swing-base lines such as Star and Multi– –Starwhere fine tuning was based on properly generated solutions. Performance was measured using Best-of-N (Bon) Accuracy with verifier ranking candidate solutions at each turn.
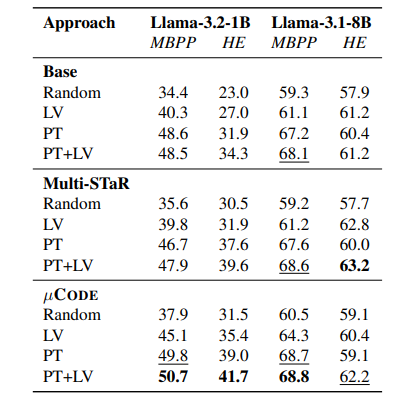
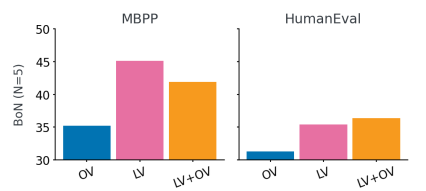
The results indicated that multi-swing approaches worked better than single-turn methods, which highlighted the benefits of feedback with execution. µcode surpassed Multi-Star and obtained a 1.9% Improving human events with one 1b model. BON SEARCH Further improved performance, with µcode showing one 12.8% Get over greedy decoding. The Teached Verifier (LV) Improved training results that surpass Oracle Verifiers (OV) alone. Further analysis showed that the learned verifier helped choose better solutions during inference, especially in the absence of public testing. Descaling of inference time revealed diminishing performance gains beyond a certain number of candidate solutions. A hierarchical verification strategy (PT+LV) Integrating public test results with learned verifier results provided the highest performance, showing the effectiveness of the verifier in eliminating erroneous solutions and making iterative predictions.
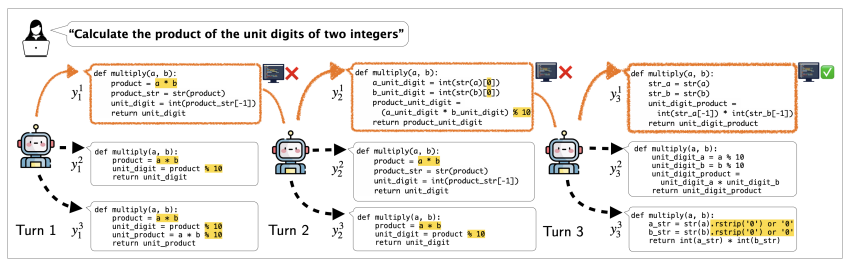
Finally, the suggested µcode frame gives a scalable approach to multi-sweeping coding generation using single-step rejections and a learned verifier for iterative improvement. The results indicate that µcode works better than Oracle-based approaches, producing a more accurate code. Although limited by model size, data set size and python focus, it can be a solid baseline for future work. Expanding training data, scaling to larger models and applying them to multiple programming languages can further improve its efficiency.
Check out The paper and the github side. All credit for this research goes to the researchers in this project. You are also welcome to follow us on Twitter And don’t forget to join our 80k+ ml subbreddit.
🚨 Meet Parlant: An LLM-First Conversation-IA frame designed to give developers the control and precision they need in relation to their AI Customer Service Agents, using behavioral guidelines and Runtime supervision. 🔧 🎛 It is operated using a user -friendly cli 📟 and native client SDKs in Python and Typescript 📦.
Divyesh is a consulting intern at MarkTechpost. He is pursuing a BTech in agricultural and food technology from the Indian Institute of Technology, Kharagpur. He is a data science and machine learning enthusiast who wants to integrate these leading technologies into the agricultural domain and solve challenges.
Parlant: Build Reliable AI customer facing agents with llms 💬 ✅ (promoted)