In recent years, the rapid scaling of large language models (LLMs) has led to extraordinary improvements in natural language understanding and reasoning. However, this progress comes with a significant warning: the inference process – generating response one token at a time – supports a calculation bottleneck. As LLMS grows in size and complexity, latency and energy requirements for sequential token generation become significant. These challenges are especially acute in implementations in the real world, where costs, speed and scalability are critical. Traditional decoding methods, such as greedy or beam search methods, often require repeated evaluations of large models, leading to a highly computational overhead. Even with parallel decoding techniques, maintaining both the efficiency and the quality of generated output can also be evasive. This scenario has spurred a search for new techniques that can reduce inference costs without sacrificing accuracy. Researchers have therefore examined hybrid methods that combine lightweight models with more powerful counterparts, strive for an optimal balance between speed and performance-a balance that is important for real-time applications, interactive systems and large-scale implementation in cloud environments.
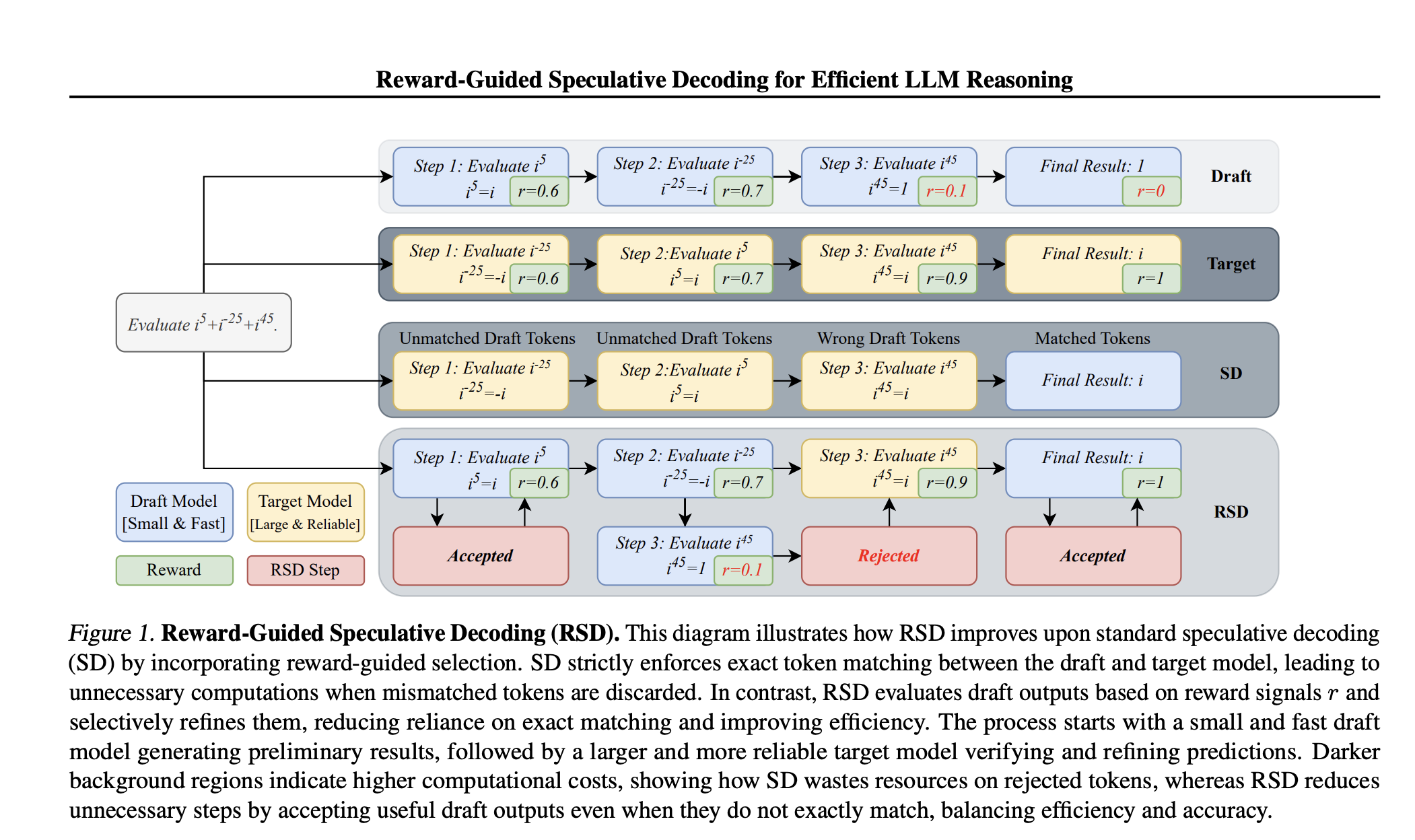
Salesforce AI research introduces the reward-controlled speculative decoding (RSD), a new framework aimed at improving the effectiveness of inference in large language models (LLMS). In its core, RSD utilizes a double model strategy: a quick, light “draft” model works in tandem with a more robust “target” model. The draft model generates preliminary candidate outputs quickly, while a process rewarding model (PRM) evaluates the quality of these output in real time. Unlike traditional speculative decoding that insists on strictly impartial token -matching between the draft and the target models, RSD introduces a controlled bias. This bias is carefully constructed to favor high reward outputs, which is considered more likely to be correct or contextually relevant — what is significantly reducing unnecessary calculations. The procedure is based on a mathematically derived threshold strategy that determines when the target model should intervene. By dynamically mixing output from both models based on a reward function, the RSD not only accelerates the inference process, but also improves the overall quality of the generated responses. In detail in the associated paper, this breakthrough methodology represents a significant leap forward in tackling the inherent inefficiency of sequential token generation in LLMS.
Technical details and benefits of RSD
RSD covers the technical aspects of integrating two models into a sequential, yet collaborative way. Originally producing the draft of model candidate -tokens or reasoning steps at a low calculation cost. Each candidate is then evaluated using a reward function that acts as a quality sport. If a candidate -token’s reward exceeds a predetermined threshold, output is accepted; If not, the system calls for the more calculation intensive target model to generate a refined token. This process is controlled by a weighting function – typically a binary step function – that adjusts the dependence on the draft against the target model. The dynamic quality control provided by the Process Relium model (PRM) ensures that only the most promising outputs bypass the target model and thereby save when calculating. One of the prominent advantages of this approach is “Partical Acceleration” where the controlled bias is not an injury, but rather a strategic choice to prioritize high -rewarding results. This results in two key advantages: First, the overall inference process can be up to 4.4 × faster compared to running the target model alone; Secondly, it often provides a +3.5 average accuracy improvement in relation to conventional parallel decoding of base lines. Essentially, RSD effectiveness with the accuracy-which provides a significant reduction in the number of fluid dot operations (flops) while still providing output that meets or even exceeds the target model performance. The theoretical submissions and algorithmic details, such as the mixing distribution defined by PRSD and the adaptive acceptance criterion, provide a robust framework for practical implementation in various reasoning tasks.
Insight
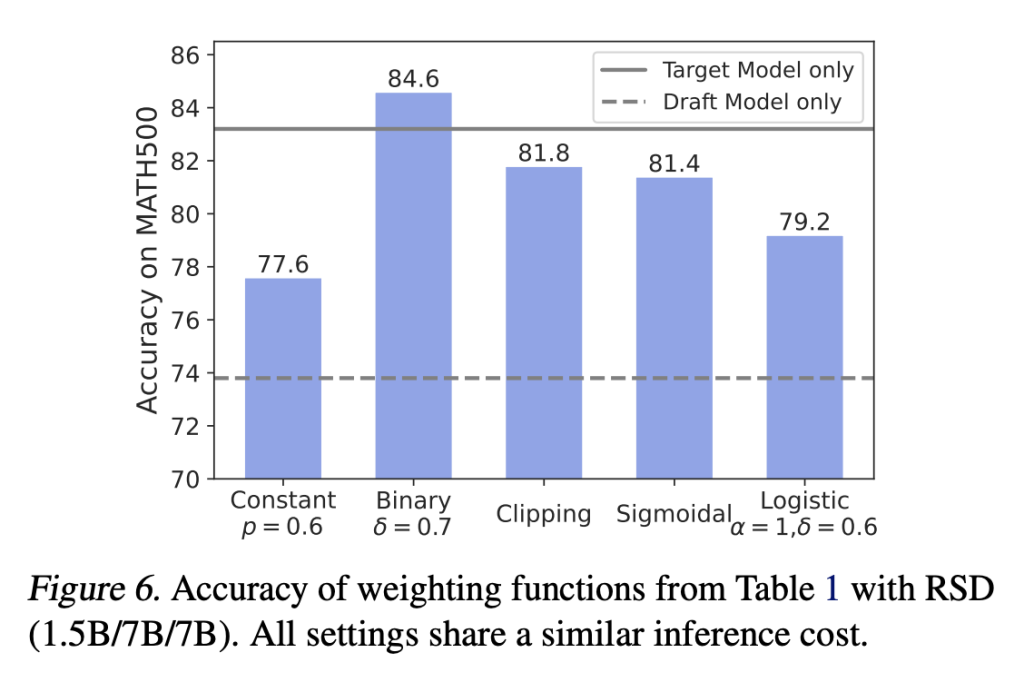
The empirical validation of RSD is compelling. Experiments that are detailed in the paper show that Olympiadbench and GPQA consistently provide superior performance. For example, on the Math500 -Bnchmark – a data set designed to test mathematical reasoning – RSD achieved an accuracy of 88.0 when configured with a 72B minimum and a 7B PRM, compared to 85.6 for the target model running alone alone . Not only does this configuration reduce the calculation load by almost 4.4 × fewer flops, but it also improves reasoning accuracy. The results emphasize the potential of RSD to surpass traditional methods, such as speculative decoding (SD) and even advanced search-based techniques such as beam search or best-n strategies.
Conclusion: A new paradigm for effective LLM -inferens
Finally, the reward-controlled speculative decoding (RSD) marks a significant milestone in the search for more effective LLM inference. By intelligently combining a light draft model with a powerful target model and by introducing a reward -based acceptance criterion, RSD effectively addresses the double challenges of calculation costs and output quality. The innovative approach to partial acceleration allows the system to selectively circumvent expensive calculations for high -rewarding outputs and thereby streamline the inference process. The dynamic quality control mechanism – anchored by a process rewarding model – is to be assigned calculation resources assigned to mentioned, which is only included in the target model when needed. With empirical results that appear up to 4.4 × faster inference and an average accuracy improvement of +3.5 compared to traditional methods, RSD not only pages the way for more scalable LLM implementations, but also sets a new standard in design of Hybrid decoding frames.
Check out The paper and the github side. All credit for this research goes to the researchers in this project. You are also welcome to follow us on Twitter And don’t forget to join our 75k+ ml subbreddit.
🚨 Recommended Open Source AI platform: ‘Intellagent is an open source multi-agent framework for evaluation of complex conversation-a-system‘ (Promoted)
Asif Razzaq is CEO of Marketchpost Media Inc. His latest endeavor is the launch of an artificial intelligence media platform, market post that stands out for its in -depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts over 2 million monthly views and illustrates its popularity among the audience.
✅ [Recommended] Join our Telegram -Canal