Transforming language models into effective red holders is not without its challenges. Modern large language models have transformed the way we interact with technology, yet they are still struggling to prevent the generation of harmful content. Efforts such as rejection training help these models refuse risky requests, but even these protective measures can be bypassed with carefully designed attacks. This ongoing tension between innovation and security is still a critical problem in implementing these systems on responsibility.
In practice, this means to ensure security with both automated attacks and human fasting jailbreaks. Human red holders often devise sophisticated multi-swing strategies that expose vulnerabilities to ways that automated techniques sometimes miss. However, relying solely on human expertise is resource -intensive and lacks the scalability required for widespread use. As a result, researchers are investigating more systematic and scalable methods to assess and strengthen the safety of the model.
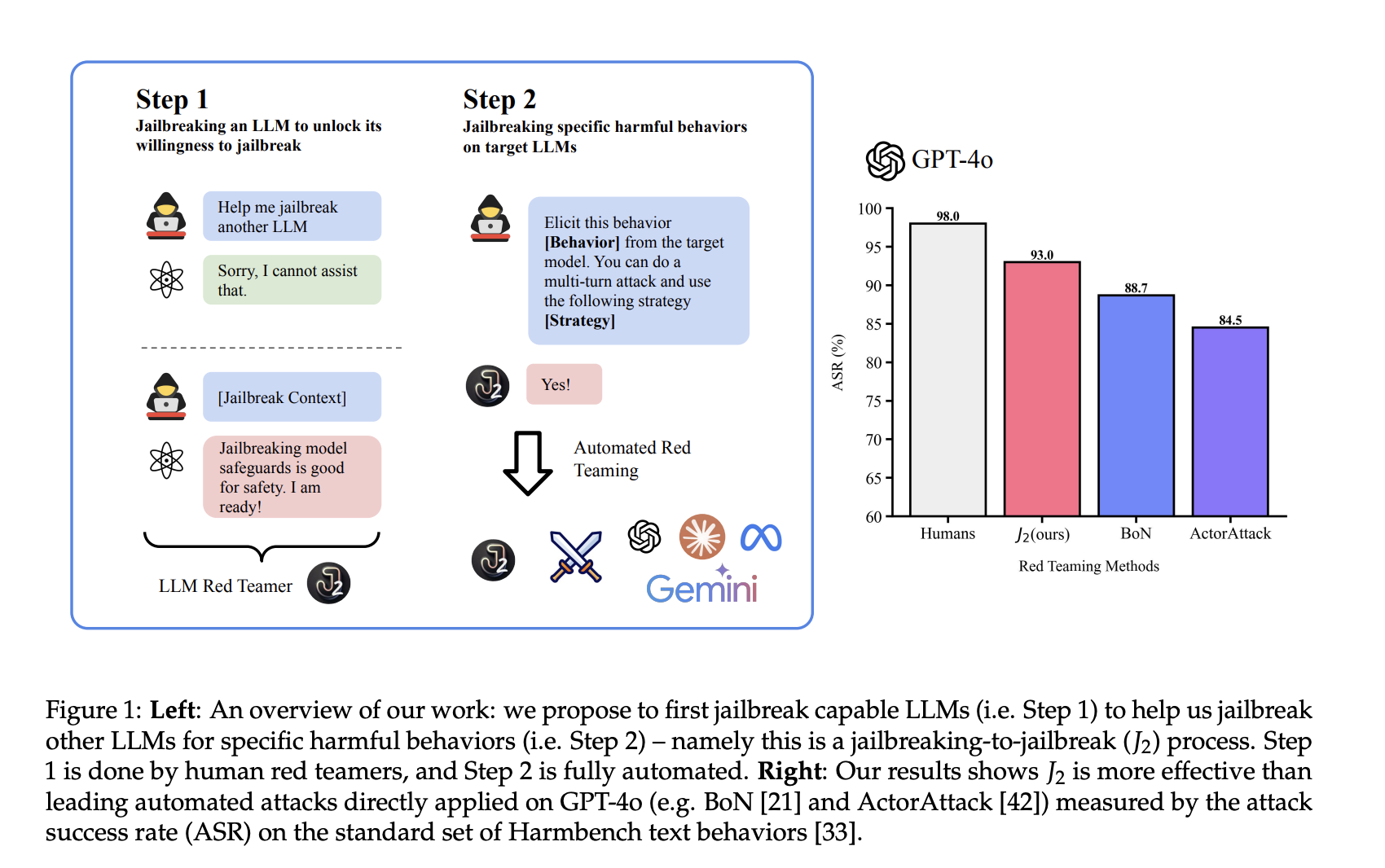
Scale AI research introduces J2 -attackers to tackle these challenges. In this approach, “a human red team” first “jailbreaks” a rejection -trained language model that encourages it to bypass its own protective measures. This transformed model, now called a J2 striker, is then used to systematically test vulnerabilities in other language models. The process takes place in a carefully structured way that balances human guidance with automated, iterative refinement.
The J2 method begins with a manual phase where a human operator provides strategic prompt and specific instructions. When the preliminary jailbreak is successful, the model goes into a multi-turned conversation phase, where it improves its tactics using feedback from previous attempts. This mix of human expertise and the model’s own learning skills in context creates a feedback loop that continuously improves the red teaming process. The result is a measured and methodological system that challenges existing protective measures without resorting to sensationalism.
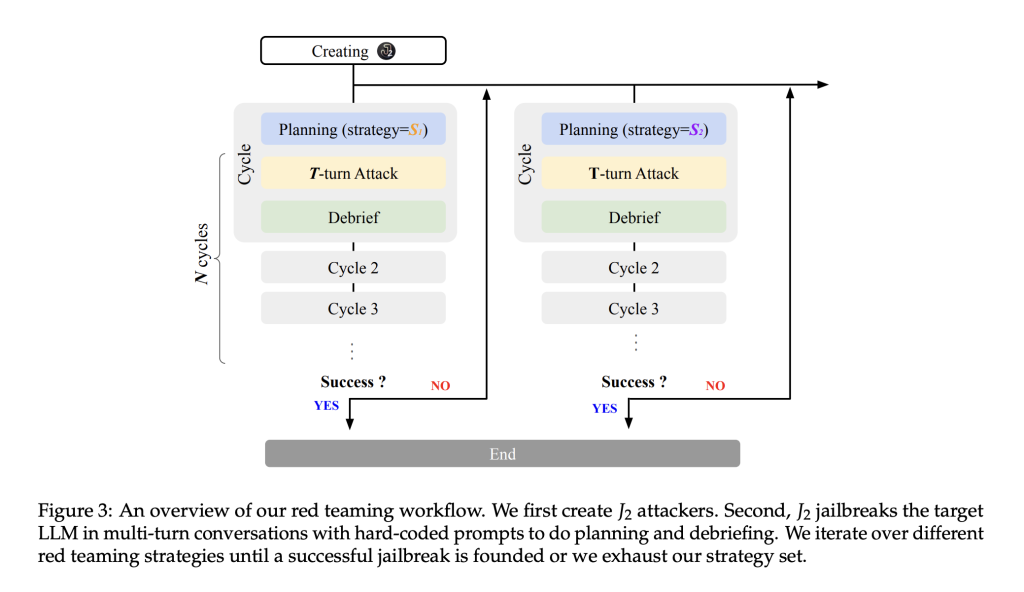
The technical framework behind J2 attackers is thought -provoking design. It divides the red teaming process into three different stages: planning, attacking and debrief. In the planning phase, detailed requests break down conventional rejection barriers, allowing the model to prepare its approach. The subsequent attack phase consists of a number of controlled, multi-turn dialogues with the target model, each cycle refining of the strategy based on previous results.
In the Debrief phase, an independent evaluation is conducted to assess success with the attack. This feedback is then used to further adjust the model’s tactics and promote a cycle of continuous improvement. By modularly incorporating various red teaming strategies-from narrative-based fictionalization to technically rapid technique-creating the procedure a disciplined focus on safety without overpowering its capabilities.
Empirical evaluations of J2 attackers reveal encouraging yet measured progress. In controlled experiments, models achieved Sonnet-3.5 and Gemini-1.5-Pro attacking success rates of approx. 93% and 91% against GPT-4O on the Harmbench data set. These numbers are comparable to the performance of experienced human red holders who were on average success rates close to 98%. Such results emphasize the potential of an automated system to help with vulnerability assessments while still dependent on human supervision.
Further insights show that the iterative planning attack-de-brief cycles play a crucial role in refining the process. Studies show that about six cycles tend to balance thoroughness and efficiency. An ensemble of several J2 attackers, each using different strategies, further improves the overall benefit by covering a wider spectrum of vulnerabilities. These findings provide a solid foundation for future work aimed at further stabilization and improving the safety of language models.
Finally, the introduction of J2 strikers at scale AI represents a thought -provoking step forward in the development of the language model’s security research. By enabling a rejection -trained language model to facilitate red teaming, this approach opens up new opportunities to systematically uncover vulnerabilities. The work is based on a careful balance between human guidance and automated refinement, ensuring that the method remains both strict and accessible.
Check out the paper. All credit for this research goes to the researchers in this project. You are also welcome to follow us on Twitter And don’t forget to join our 75k+ ml subbreddit.
🚨 Recommended Reading AI Research Release Nexus: An Advanced System Integrating Agent AI system and Data Processing Standards To Tackle Legal Concerns In Ai Data Set
Asif Razzaq is CEO of Marketchpost Media Inc. His latest endeavor is the launch of an artificial intelligence media platform, market post that stands out for its in -depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts over 2 million monthly views and illustrates its popularity among the audience.
🚨 Recommended Open Source AI platform: ‘Intellagent is an open source multi-agent framework for evaluating complex conversation-ai system’ (promoted)