Large language models are struggling to treat and resonate over long, complex texts without losing significant context. Traditional models often suffer from context loss, ineffective handling of long -range dependencies and difficulties in adapting to human preferences that affect the accuracy and effectiveness of their answers. Tencents Hunyuan-T1 directly tackles these challenges by integrating a new Mamba-driven architecture with advanced reinforcement learning and curriculum strategies, ensuring robust context catch and improved reasoning capacities.
The Hunyuan-T1 is the first model driven by the innovative Mamba architecture, a design that merges with hybrid transformer and mixing experts (MOE) technologies. The Hunyuan-T1 is built on TurboS Fast-Thinking Base and is specifically designed to optimize the treatment of long textual sequences, while the minimization of calculation costs. This allows the model to effectively capture extended context and control long -distance dependents, crucial for tasks that require deeply, coherent reasoning.
A central highlight of the Hunyuan-T1 is its heavy dependence on RL in the post-training phase. Tencent dedicated 96.7% of its computing power to this approach, enabling the model to refine its reasoning skills iteratively. Techniques such as data playback, periodic political reset and self-stressing feedback loops help improve the output quality, ensuring that the model’s answers are detailed, effective and close line with human expectations.
To further increase the reasoning skills, Tencent used a curriculum for learning curricula. This approach gradually increases the difficulty of educating data and at the same time expanding the model’s context length. As a result, Hunyuan-T1 is trained to use the tokens more effectively, and is adapted to seamlessly from solving basic mathematical problems to tackling complex scientific and logical challenges. Efficiency is another cornerstone of Hunyuan-T1’s design. The Turbos base’s ability to capture long-term information prevents context loss, a common problem in many language models and doubles the decoding speed compared to similar systems. This breakthrough means that users benefit from faster reactions of higher quality without compromising the benefit.
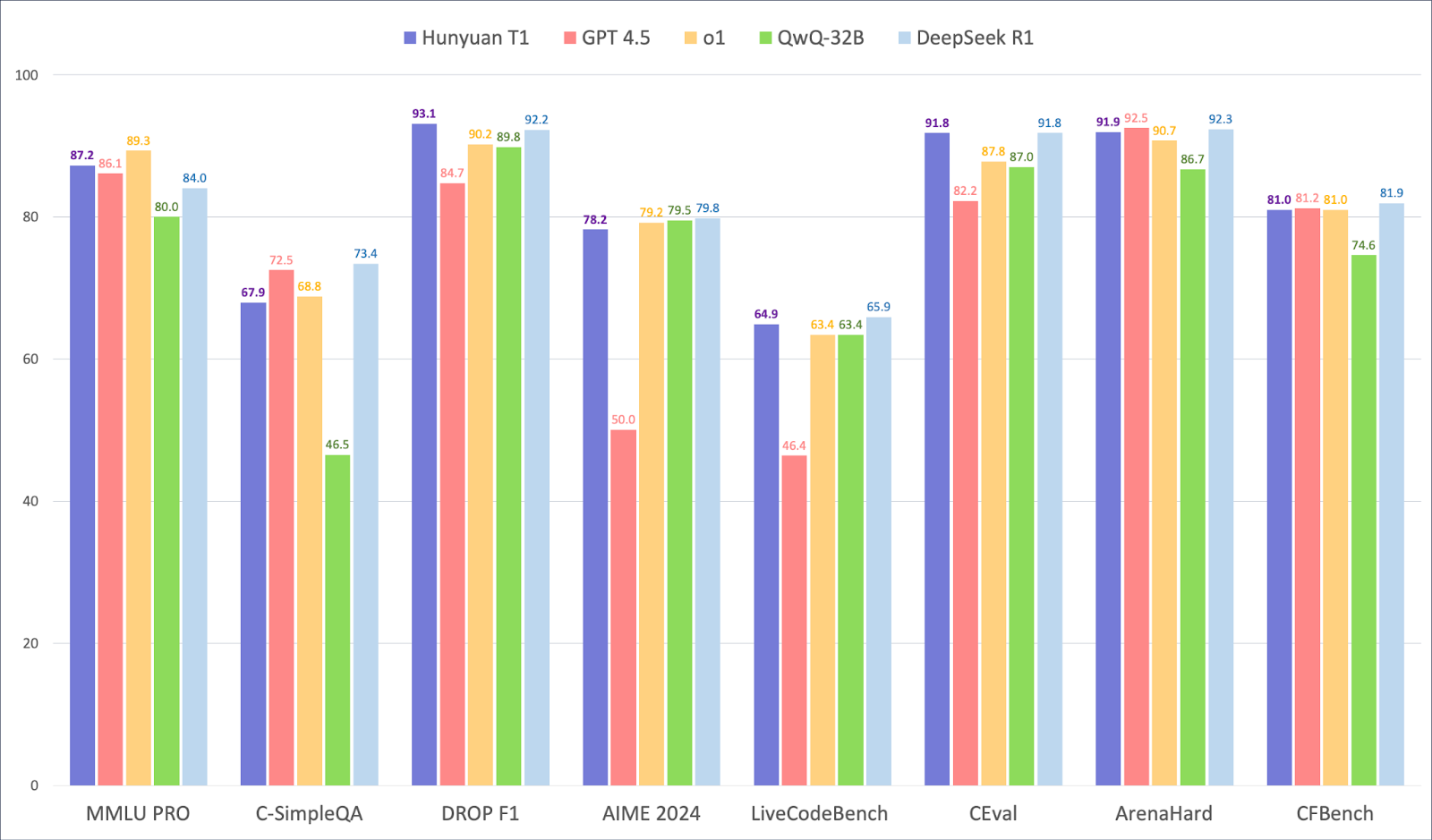
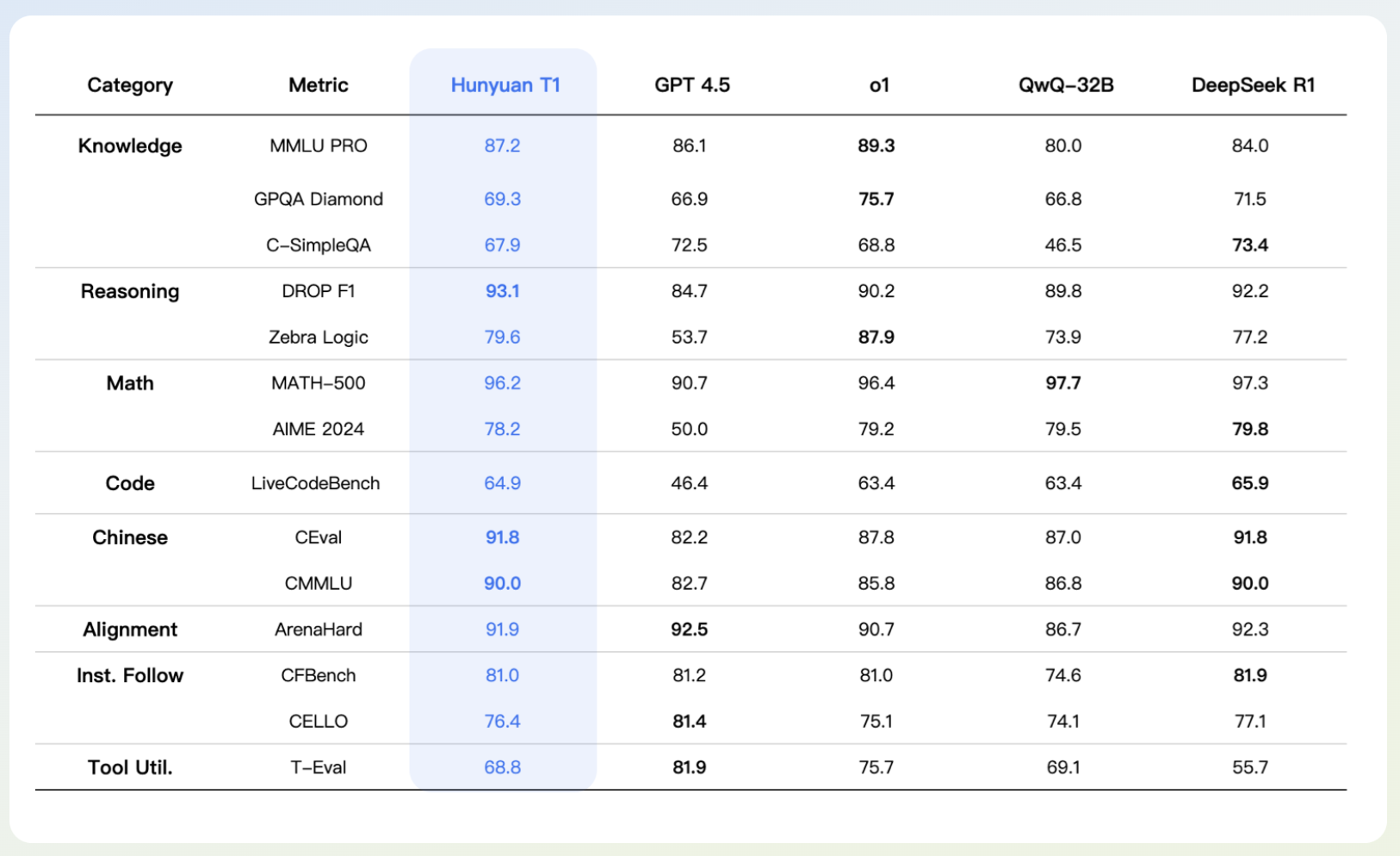
The model has achieved impressive scores on several benchmarks: 87.2 on MMLU-Pro, which tests various topics, including the humanities, social sciences and voice fields; 69.3 On GPQA diamond, a challenging evaluation with scientific problems at the doctoral level; 64.9 on LIVE CODEBENCH for coding tasks; And a remarkable 96.2 on Math-500-Benchmark for mathematical reasoning. These results emphasize Hunyuan-T1’s versatility and ability to handle high-effort tasks, professional quality across different areas. In addition to quantitative measurements, the Hunyuan-T1 is designed to provide output with human-like understanding and creativity. During its RL phase, the model underwent a comprehensive adjustment process that combined self-inflicting feedback with external reward models. This double approach ensures that its answer is accurate and exhibits rich details and natural flow.
Finally, Tencents Hunyuan-T1 combines an ultra-large scale, Mamba-driven architecture with advanced reinforcement learning and curriculum strategies. Hunyuan-T1 delivers high performance, improved reasoning and unique efficiency.
Check out The details, embracing face and github —side. All credit for this research goes to the researchers in this project. You are also welcome to follow us on Twitter And don’t forget to join our 85k+ ml subbreddit.
Asif Razzaq is CEO of Marketchpost Media Inc. His latest endeavor is the launch of an artificial intelligence media platform, market post that stands out for its in -depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts over 2 million monthly views and illustrates its popularity among the audience.