Large language models (LLMS) work by predicting the next token based on input data, but their performance suggests that they process information in addition to simply predictions at token level. This raises questions about whether LLMs participate in implicit planning before generating complete answers. Understanding this phenomenon can lead to more transparent AI systems, improve efficiency and make output generation more predictable.
One challenge of working with LLMS is to predict how they will structure answers. These models generate text sequentially, making control of the total response length, reasoning depth and actual accuracy challenging. The lack of explicit planning mechanisms means that although LLMs generate human -like answers, their internal decision making remains opaque. As a result, users often depend on quick technique to guide output, but this method lacks precision and does not provide insight into the model’s inherent response formulation.
Existing techniques for refining LLM output include reinforcement learning, fine tuning and structured encouragement. Researchers have also experimented with decision trees and external logic -based frameworks to impose structure. However, these methods do not fully capture how LLMs internally process information.
Shanghai Artificial Intelligence Laboratory Research Team has introduced a new approach by analyzing hidden representations to reveal latent response planning behavior. Their findings suggest that LLMs cod for key properties for their answers even before the first token is generated. The research team examined their hidden representations and investigated whether LLMs are participating in planning new answers. They introduced simple exploration models trained on quick embedders to predict upcoming response attributes. The study categorized response planning in three main areas: structural attributes, such as response length and reasoning steps, content properties including character choices in history-writing tasks and behavioral properties, such as trust in multiple choices responses. By analyzing patterns in hidden layers, the researchers found that these planning skills scale of model size and evolving throughout the generation process.
To quantify response planning, the researchers carried out a number of probe sex periments. The trained models to predict the response attributes using hidden condition representations extracted before output generation. The experiments showed that probes could precisely predict upcoming text properties. The results indicated that LLMS coded response triplets in their quick representations, with planning skills that peaked at the beginning and end of the answers. The study also demonstrated that models of different sizes share similar planning behavior, with larger models that exhibit more significant predictable capabilities.
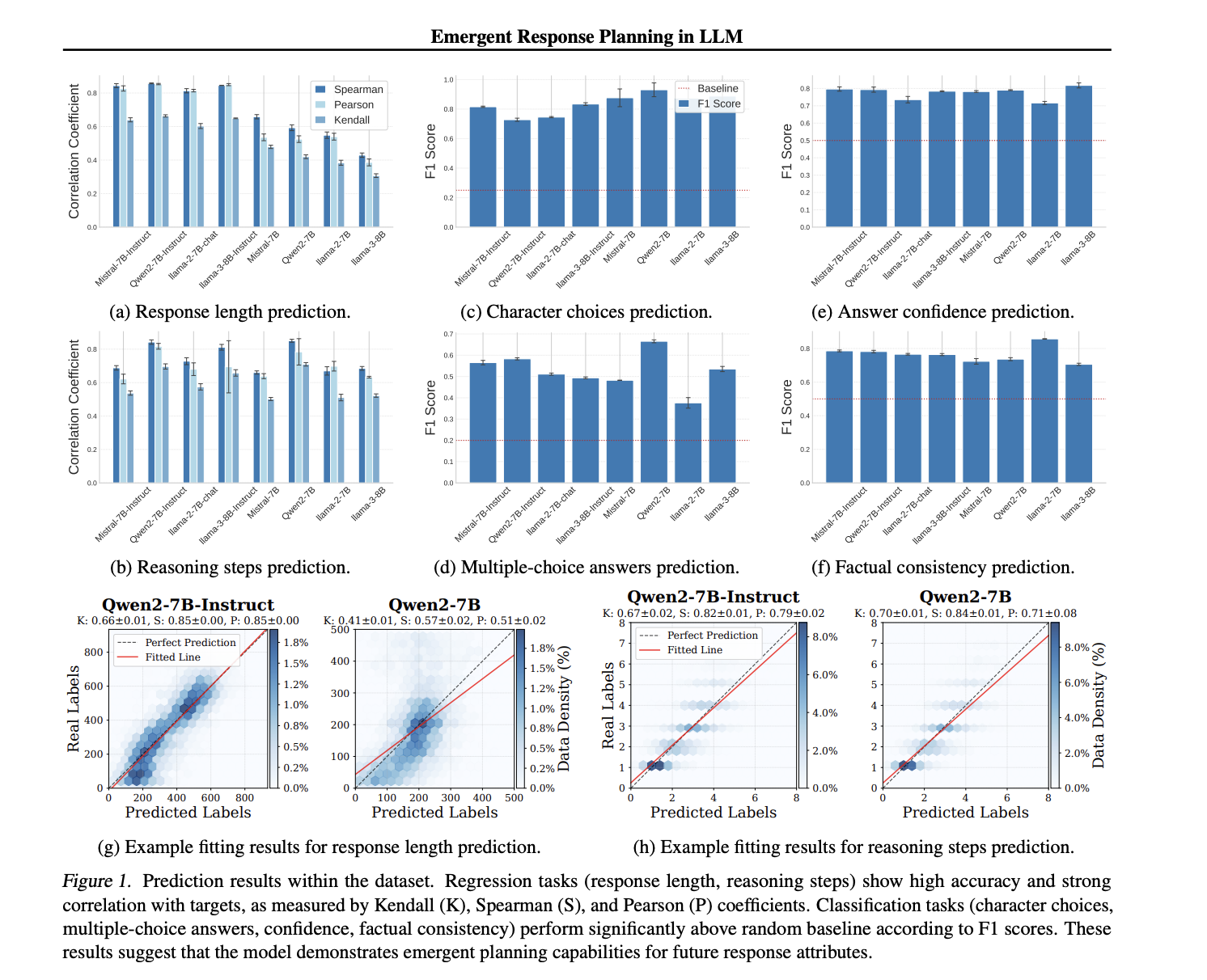
The experiments revealed significant differences in planning ability between base and fine -tuned models. Fine -tuned models showed better prediction accuracy in structural and behavioral attributes, confirming that planning behavior is reinforced through optimization. E.g. Viewed prediction of response length high correlation coefficients across models where Spearance correlation reached 0.84 in some cases. Similarly, justification stage predictions showed strong adaptation to soil sandy values. Classification assignments such as character choices in history’s writing and multiple-choice replacement selection are performed significantly over random basic lines, which further supports the notion that LLMs internal codes for elements in response planning.
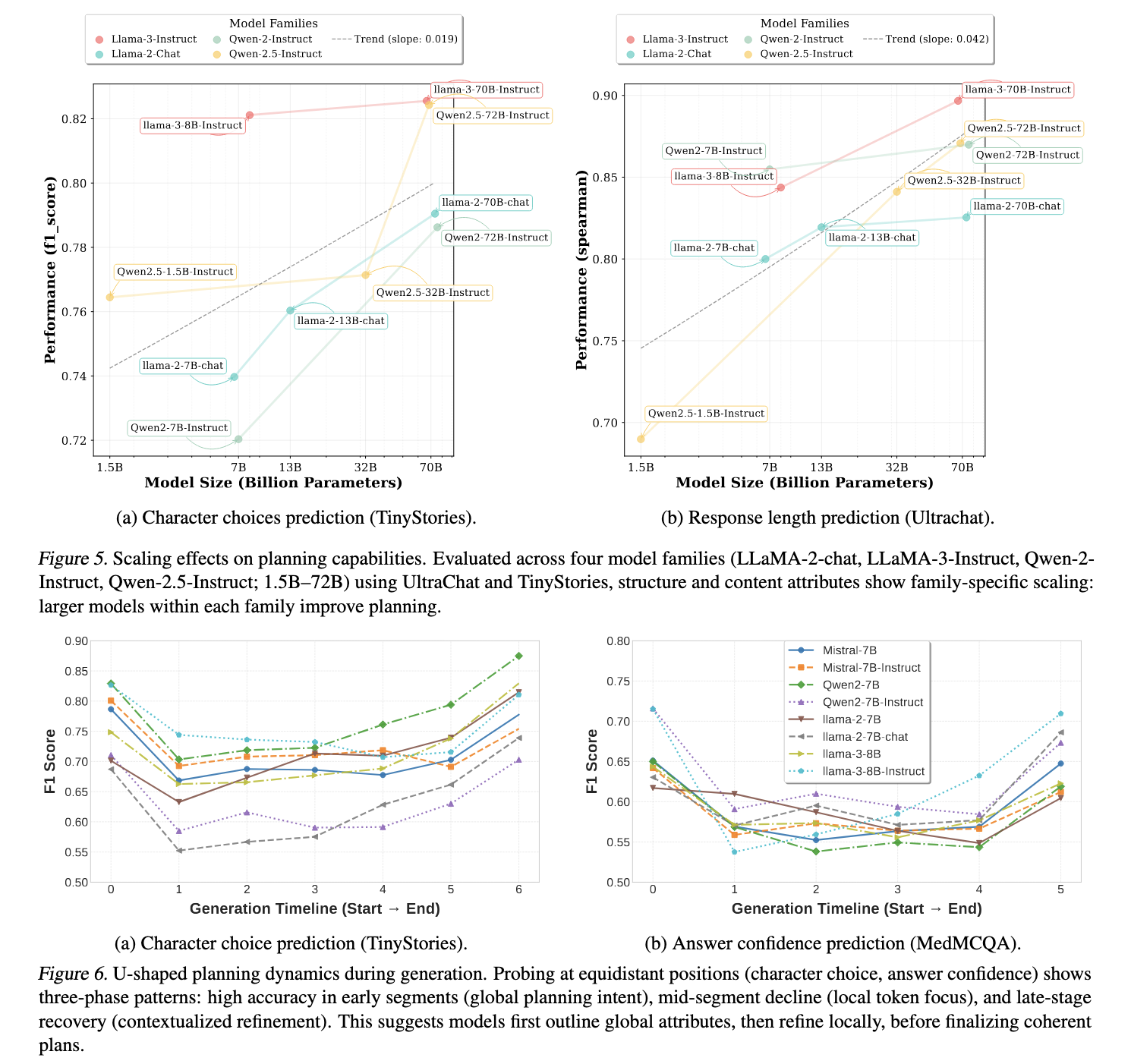
Larger models demonstrated superior planning skills across all attributes. Within the LLAMA and QWEN model, planning accuracy consistently improved with increased parameter numbers. The study found that Llama-3-70B and QWEN2.5-72B instructions exhibited the highest prediction benefit, while smaller models such as QWEN2.5-1.5B struggled to code long-term response structures effectively. Furthermore, layered layered sex periments indicated that structural attributes emerged prominently in the middle of the layers, while content properties became more pronounced in later layers. Behavioral properties, such as response confidence and factual consistency, remained relatively stable across different model depths.
These findings highlight a basic aspect of LLM behavior: They not only predict the next token but plan broader attributes for their answers before generating text. This new reaction planning ability has consequences for improving model transparency and control. Understanding these internal processes can help refine AI models, leading to better predictability and reduced dependence on after generation of corrections. Future research can investigate the integration of explicit planning modules in LLM architectures to improve the adaptation of the response coating and user-controlled.
Check out the paper. All credit for this research goes to the researchers in this project. You are also welcome to follow us on Twitter And don’t forget to join our 75k+ ml subbreddit.
🚨 Recommended Reading AI Research Release Nexus: An Advanced System Integrating Agent AI system and Data Processing Standards To Tackle Legal Concerns In Ai Data Set
Nikhil is an internal consultant at MarkTechpost. He is pursuing an integrated double degree in materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who always examines applications in fields such as biomaterials and biomedical science. With a strong background in material science, he explores new progress and creates opportunities to contribute.
