Tabular data is used widely in different areas, including scientific research, economics and healthcare. Traditionally, machine learning models such as gradient-boosted decision trees are preferred to analyze tabular data due to their efficiency in handling heterogeneous and structured data sets. Despite their popularity, these methods have remarkable limitations, especially in terms of performance on unseen data distributions, transfer of learned knowledge between data sets and integration challenges with neural network-based models due to their non-differential character.
Researchers from the University of Freiburg, Berlin Institute of Health, Prior Labs and Ellis Institute have introduced a new approach called Tabular Prior-Data Fitted Network (Tabpfn). Tabpfn utilizes transformer architectures to tackle common limitations associated with traditional tabular data methods. The model surpasses significantly gradient-boosted decision trees in both classification and regression tasks, especially on data sets with fewer than 10,000 samples. In particular, Tabpfn demonstrates remarkable efficiency and achieve better results in just a few seconds compared to several hours of extensive hyperparameter setting required by ensemble-based wood models.
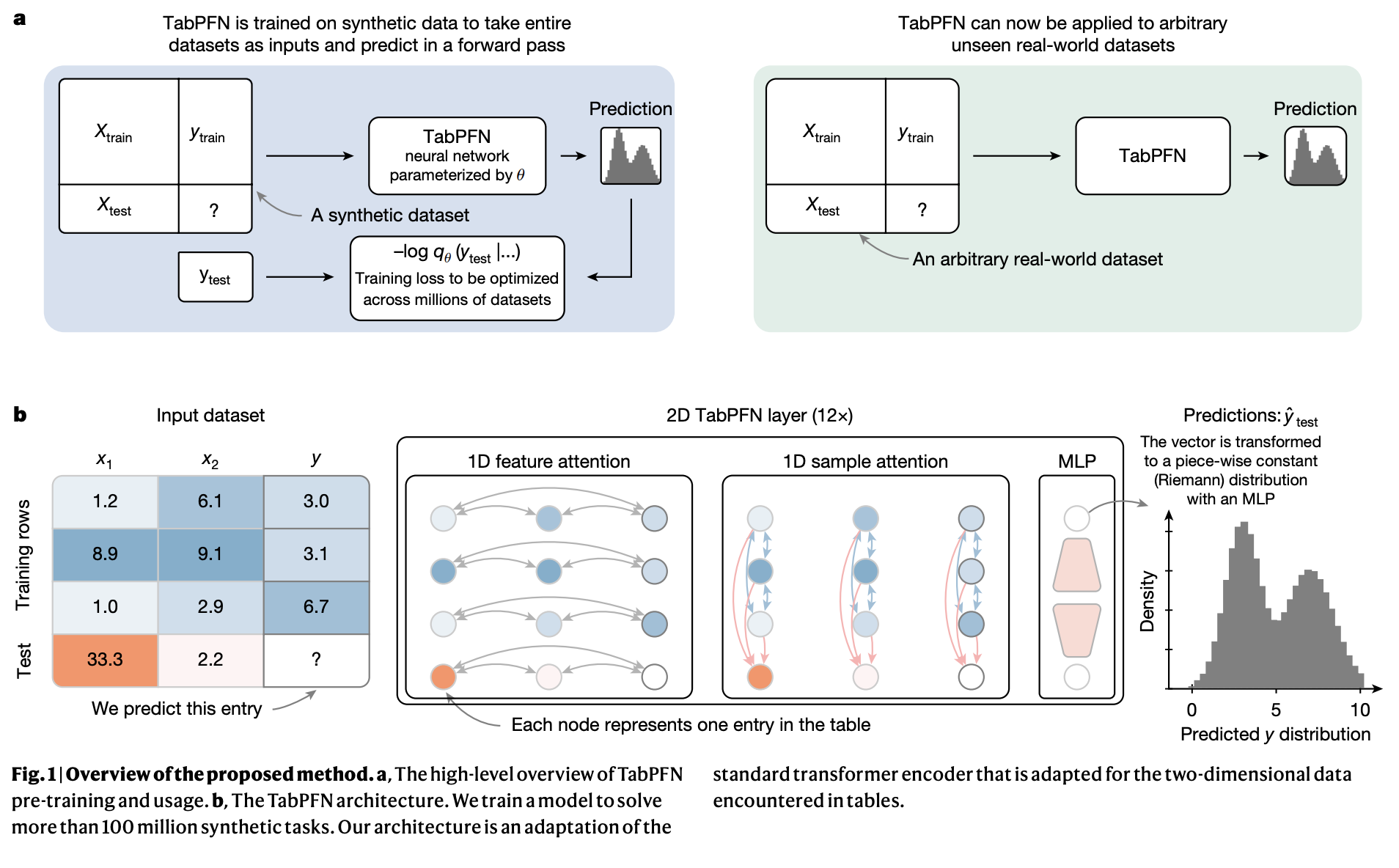
TabpfN uses In-Context Learning (ICL), a technique originally introduced by large language models, where the model learns to solve tasks based on contextual examples delivered during inference. The researchers adapted this concept specifically to table data by pre -processing Tabpfn on millions of synthetic generated data sets. This training method allows the model to implicitly learn a wide range of predictable algorithms, reducing the need for extensive data set specific training. Unlike traditional deep learning models, Tabpfn processes the entire data set at the same time during a single forward pass through the network, which significantly improves calculation efficiency.
The architecture of TabpfN is specifically designed for table data that uses a two-dimensional attention mechanism tailored to effectively apply the inherent structure of tables. This mechanism allows each data cell to interact with others across rows and columns, effectively managing different data types and conditions such as categorical variables, missing data and outliers. Furthermore, TabpfN optimizes the calculation efficiency of cache intermediaries from the training set, which markedly accelerates the inference on subsequent test tests.
Empirical evaluations highlight Tabpfn’s significant improvements over established models. Across different benchmark data sets, including Automl Benchmark and OpenML-CTR23, Tabpfn consistently achieves higher performance than widely used models such as XGBOOST, CATBOOST and Lightgbm. For classification issues, Tabpfn showed remarkable gains in normalized ROC AUC scores compared to extensive reconciled baseline methods. Similarly, in regression contexts, these established approaches surpassed and showing improved normalized RMSE scores.
Tabpfn’s robustness was also extensively evaluated across data sets characterized by challenging conditions, such as several irrelevant features, outliers and significant missing data. Unlike typical neural network models, Tabpfn maintained a consistent and stable performance during these challenging scenarios, demonstrating its fitness to practical applications in the real world.
In addition to its predictable forces, TabpfN also exhibits basic capabilities typical of foundation models. It effectively generates realistic synthetic tabular data sets and estimates precisely the probability distribution of individual data points, making it suitable for tasks such as anomalid detection and data enlargement. In addition, the embedders are produced by Tabpfn meaningful and recyclable, providing practical value for downstream tasks, including clusters and imputation.
In summary, the development of TabpfN denotes an important development in modeling tabular data. By integrating the strengths of transformer -based models with the practical requirements for structured data analysis, TABPFN offers improved accuracy, calculation efficiency and robustness, which potentially facilitates significant improvements across different scientific and business domains.
Here it is Paper. Nor do not forget to follow us on Twitter and join in our Telegram Channel and LinkedIn GrOUP. Don’t forget to take part in our 90k+ ml subbreddit.
🔥 [Register Now] Minicon Virtual Conference On Agentic AI: Free Registration + Certificate for Participation + 4 Hours Short Event (21 May, 9- 13.00 pst) + Hands on Workshop
Sana Hassan, a consultant intern at MarkTechpost and dual-degree students at IIT Madras, is passionate about using technology and AI to tackle challenges in the real world. With a great interest in solving practical problems, he brings a new perspective to the intersection of AI and real solutions.
