Large Language Models (LLMs) benefits from the reinforcement of learning techniques that enable iterative improvements by learning from rewards. However, training these models remains effectively challenging as they often require extensive data sets and human supervision to improve their abilities. Development methods that allow LLMs to self-enhance autonomously without further human input or major architectural changes have become a main focus of AI research.
The most important challenge in Training LLMS is to ensure that the learning process is effective and structured. The education process can stop when models encounter problems beyond their abilities, leading to poor results. Traditional reinforcement learning techniques rely on well -curated data sets or human feedback to create effective learning paths, but this approach is resource -intensive. LLMS is also struggling to improve systematically without a structured difficulty gradient, making it difficult to bridge basic reasoning tasks and more complex problem solving.
Existing approaches to training LLMs involves primarily monitored fine -tuning, reinforcement learning from human feedback (RLHF) and curriculum learning. Monitored fine -tuning requires manually labeled data sets, which can lead to overfitting and limited generalization. RLHF introduces a layer of human supervision where models are refined based on human evaluations, but this method is expensive and does not scale effectively. Teaching learning, which gradually increases the difficulties of the task, has shown promise, but current implementations are still dependent on predefined data sets instead of allowing models to generate their learning courses. These limitations highlight the need for an autonomous learning framework that allows LLMs to improve their problem -solving abilities independently.
Researchers from TUFA Labs introduced Rises (learning through autonomous difficulty -driven example Recursion) to overcome these limitations. This framework enables LLMs to self -enhance by recursively generating and solving gradually simpler variants of complex problems. Unlike previous methods that depend on human intervention or curated data sets, Gadder exploits the model’s ability to create a natural degree of difficulty, allowing for structured self -learning. The research team developed and tested ladders on mathematical integration tasks, demonstrating its effectiveness in improving model performance. By using ladder, researchers activated a 3-billion parameter Llama 3.2 model to improve its accuracy on bachelor integration problems from 1% to 82%, an unprecedented leap in mathematical reasoning functions. The procedure was also expanded to larger models, such as QWEN2.5 7B Deepseek-R1 distilled, achieved 73% accuracy on the MIT integration BI qualification survey, far exceeds models such as GPT-4o, which received only 42% and typically human performance in the range of 15-30%.
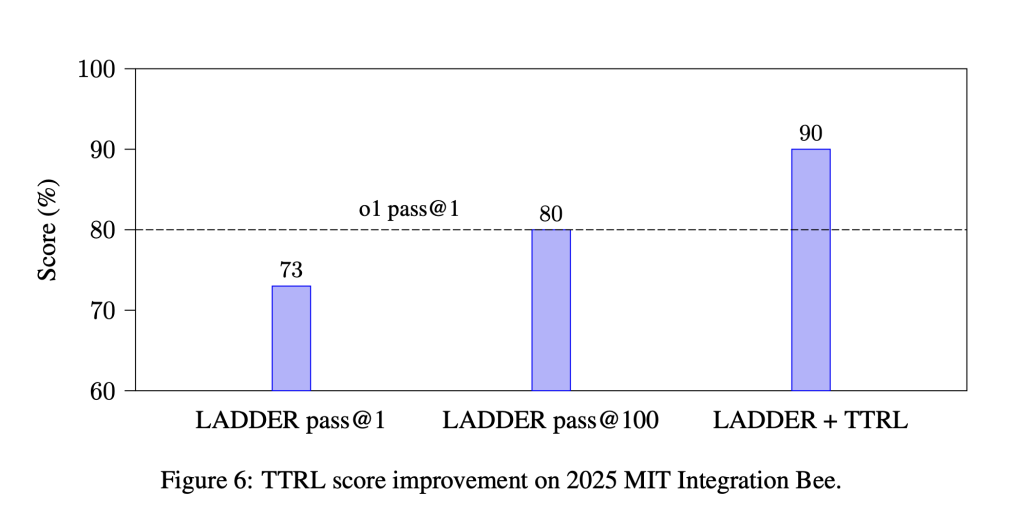
Ladder follows a structured method that allows LLMs to bootstrap their learning by systematically breaking down complex problems. The process involves three primary components: variant generation, solution of solution and reinforcement learning. The variant generation step ensures that the model gradually produces lighter versions of a given problem and forms a structured difficulty gradient. The solution verification step uses numerical integration methods to assess the correctness of generated solutions, providing immediate feedback without human intervention. Finally, the reinforcing learning component group uses relative political optimization (GRPO) to train the model effectively. This protocol allows the model to learn step by step by utilizing verified solutions so that it can refine its problem -solving strategies systematically. The researchers expanded this approach with test time reinforcement learning (TTRL), which dynamically generates problem variants during inference and uses reinforcement learning to refine real -time solutions. When used for my Integration BI -Qualification Survey, TTRL increased model accuracy from 73% to 90% and exceeded Openais O1 model.
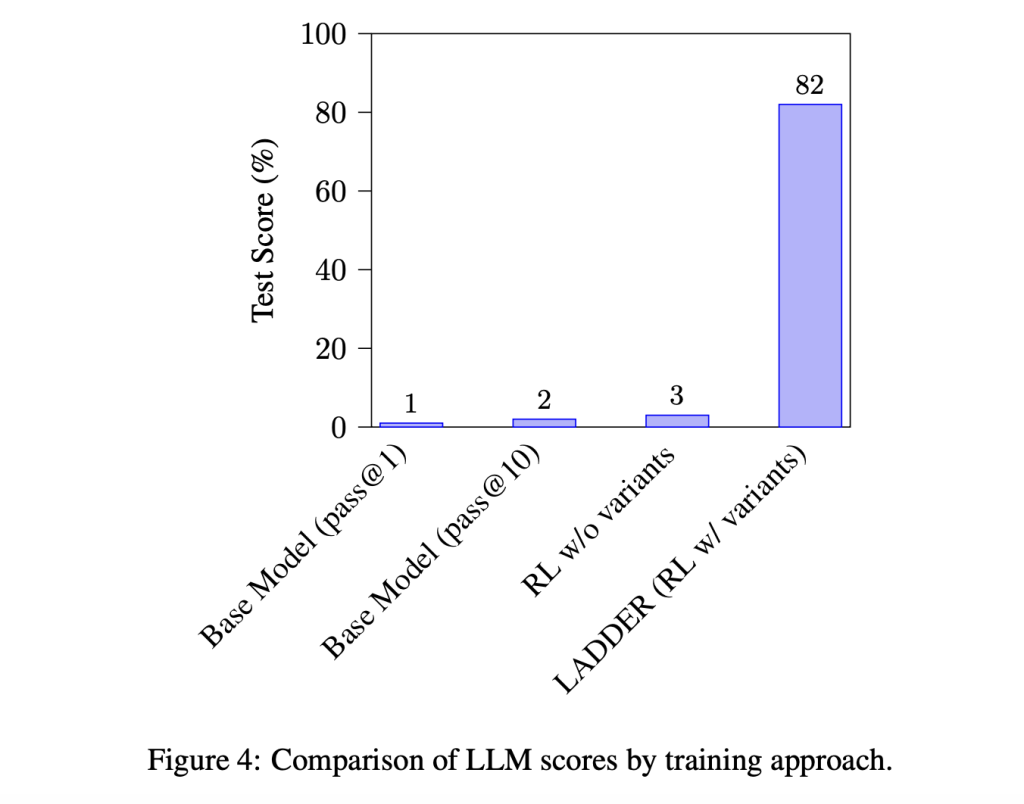
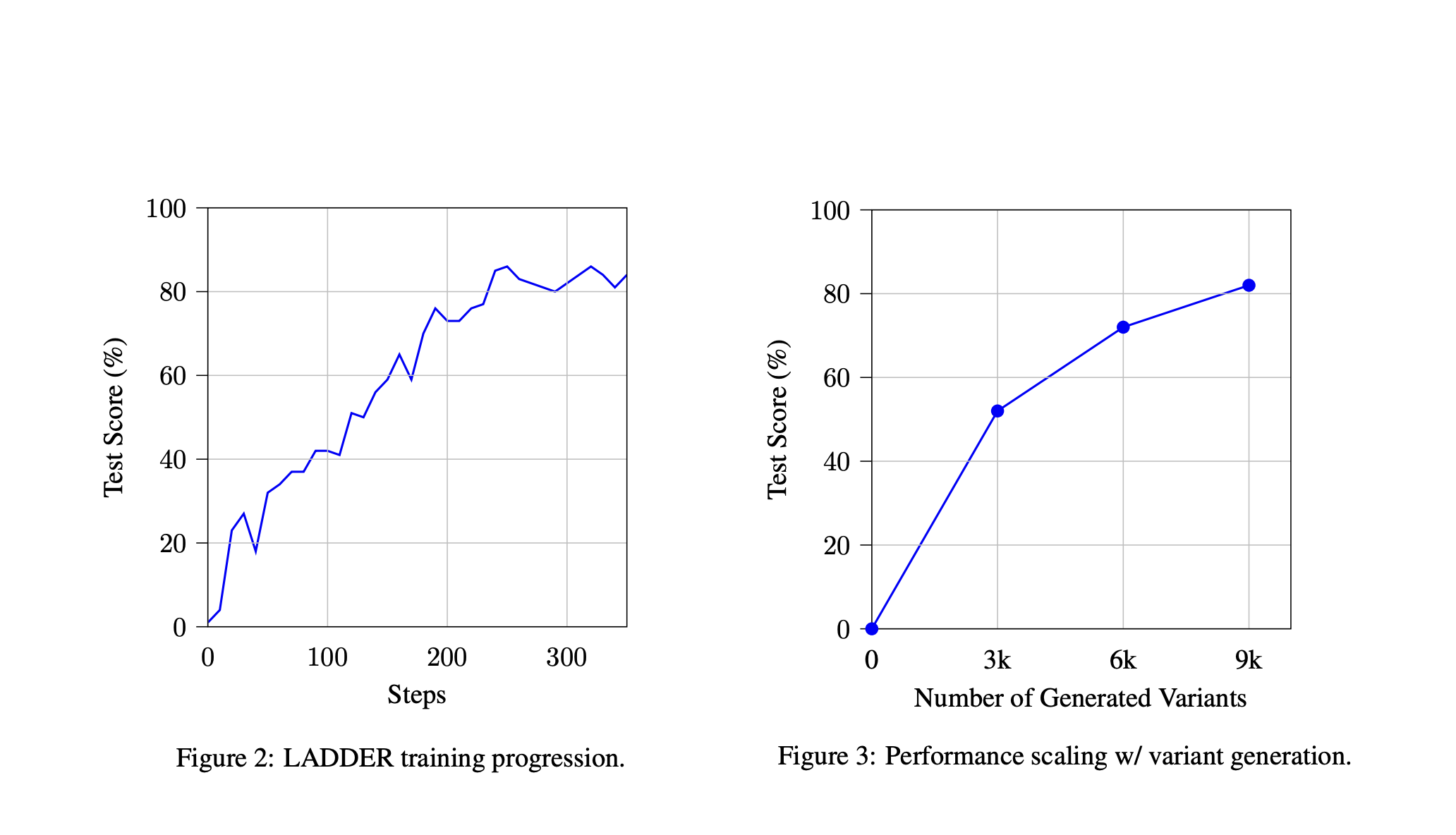
When tested on a dataset of 110 integration problems at the bachelor level, an Llama 3.2 3B model trained with the ladder with the ladder 82% accuracy compared with 2% accuracy when using Pass@10 sampling. The procedure also demonstrated scalability as the increase in the number of variants generated to continued performance improvements. In contrast, reinforcement learning failed to achieve meaningful gains, which reinforces the importance of structured problem degradation. The researchers observed that ladder-trained models could solve integrals that required advanced techniques that were previously out of reach. Use of the methodology for the MIT integration BI qualification study, a Deepseek-R1 QWEN2.5 7B model trained with the ladder, surpassed better than larger models that did not review recursive training, showing the effectiveness of structured self-improvement in mathematical reasoning.
The main takeaways from the research on ladder include:
- Enables LLMs to self -enhance by recursively generating and solving simpler variants of complex problems.
- Llama 3.2 3B model improved from 1% to 82% on bachelor integration tasks, demonstrating the effectiveness of structured self-learning.
- QWEN2.5 7B DEEPSEEK-R1 Distilled obtained 73%accuracy that exceeded GPT-4O (42%) and exceeded human performance (15-30%).
- Further increased accuracy from 73% to 90% and exceeded Openais O1 model.
- Ladder does not require external data sets or human intervention, making it a cost-effective and scalable solution for LLM training.
- Models trained with ladder demonstrated superior problem -solving ability compared to reinforcement learning without structured difficulty gradients.
- The framework provides a structured way for AI models to refine their reasoning skills without external supervision.
- Methodology can be expanded to competitive programming, theorem problem and agent -based problem solving.
Check out the paper. All credit for this research goes to the researchers in this project. You are also welcome to follow us on Twitter And don’t forget to join our 80k+ ml subbreddit.
🚨 Recommended Reading AI Research Release Nexus: An Advanced System Integrating Agent AI system and Data Processing Standards To Tackle Legal Concerns In Ai Data Set
Asif Razzaq is CEO of Marketchpost Media Inc. His latest endeavor is the launch of an artificial intelligence media platform, market post that stands out for its in -depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts over 2 million monthly views and illustrates its popularity among the audience.
🚨 Recommended Open Source AI platform: ‘Intellagent is an open source multi-agent framework for evaluating complex conversation-ai system’ (promoted)